
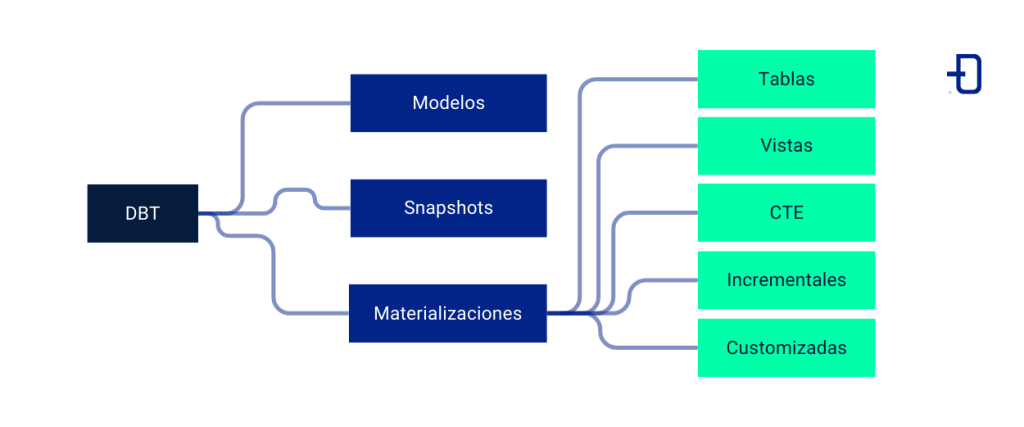
En otros espacios de discusión elaboramos una comparación entre DBT, Pentaho y Spark para realizar transformaciones de datos. En este post, veremos algunos de los conceptos claves de DBT: modelos, snapshots y materializaciones.
En el contexto de DBT, encontramos una serie de recursos para realizar el proceso de transformación de los datos. Cada uno de ellos tiene una semántica particular que lo caracteriza y que podría no coincidir con la que tiene un concepto con el mismo nombre fuera de este ámbito. Los tres que vamos a discutir son los más básicos de esta metodología y esenciales para comenzar con DBT.
Trabajando con modelos, snapshots y materializaciones en DBT
Modelos
A lo que llamamos modelos en la metodología de DBT son en realidad consultas SQL que se encargan de transformar y estructurar los datos de manera organizada y reproducible. Empleando modelos, somos capaces de crear un pipeline de pequeñas transformaciones incrementales a partir de un conjunto de datos. Para que esto ocurra, DBT es capaz de gestionar el orden de ejecución de los modelos definidos, garantizando que las dependencias entre ellos se resuelvan correctamente.
Cuando creamos un modelo, DBT le aplica una versión para ayudarnos con el seguimiento de cambios que realicemos. Además, nos permite agregarle pruebas para comprobar que el modelo se genera correctamente y documentación para describirlo. Esto es realmente útil cuando trabajamos en proyectos con equipos. Posteriormente, podremos usar cada uno de estos modelos creados para el análisis de datos, ya que se integran perfectamente con diversas herramientas de BI (como Looker o Tableau).
Snapshots
Es posible que alguna vez hayas necesitado consultar datos de una tabla que ha sido actualizada, pero los hayas sobreescrito, o hayas construido tu sistema de forma que tenga varias filas para un mismo dato con los cambios aplicados. ¿Sabrías distinguir qué entrada es la que estás buscando? Si no te ha pasado, es posible que te parezca un problema minúsculo, pero en muchas ocasiones no lo es.
Los snapshots de DBT lidian con ese problema creando tablas Type-2 Slowly Changing Dimensions, que no debemos confundir con una instantánea tal y como la conocemos. Las snapshots bajo este contexto, identifican cómo van cambiando las filas de los datos conforme pasa el tiempo y mantienen un historial de dichos cambios. Para aplicarlos, necesitamos identificar cuales son las columnas que pueden cambiar con el tiempo.
Un ejemplo de la funcionalidad de los snapshots de DBT podría ser el que observamos en la tabla de alumnos siguiente. Esta muestra cómo cambia el valor de la columna curso de failed a passed.
| id | name | dbt_updated_at | dbt_valid_from | dbt_valid_to | dbt_valid_from | |
| 1 | Alumn1 | @alumn1.es | 2020-01-01 | 2020-01-01 | 2023-01-01 | failed |
| 2 | Alumn1 | @alumn1.es | 2023-01-01 | 2023-01-01 | null | passed |
Materializaciones
A la hora de definir nuestros modelos, es importante conocer de qué forma necesitaremos almacenarlos en nuestro proyecto. Las materializaciones son la forma en la que se recogerán los datos de un modelo. Nos permitirán optimizar el rendimiento en las ejecuciones de estos, generando los modelos que necesitamos, pero ahorrando en tiempo y en recursos de nuestro sistema. Para ello, DBT nos proporciona distintos tipos de materializaciones que podemos utilizar, dependiendo de diversos factores: la naturaleza de nuestros datos, la periodicidad de actualización o adición de entradas, el tipo de transformación que hemos realizado, la frecuencia de consulta u otro tipo no predefinido que queremos construir.
Los tipos de materializaciones de los que dispondremos serán los siguientes:
Tablas
Cuando no especifiquemos una materialización, las tablas serán la forma predeterminada en la que encontraremos los datos. Debemos entender este tipo de materialización como una tabla física común, en la que se almacenarán los datos dentro de una estructura de filas y columnas. Idealmente, usaremos tablas para guardar los datos estáticos o con cambios poco frecuentes que necesiten resolver consultas complejas o en el menor tiempo posible.
El empleo de tablas nos puede ayudar a almacenar datos que reciban consultas frecuentes, ya que con los datos almacenados no necesitaremos recalcularlos en cada consulta. Esto es útil si almacenamos nuestras materializaciones en entornos cloud que nos cobren por el número de consultas realizadas o por su tiempo de ejecución. Además, si vamos a utilizar herramientas de BI, la mejor opción es emplear tablas.
Vistas
Una forma de materializar nuestros datos en DBT es mediante vistas, que son una representación lógica de los datos sin llegar a crear una tabla (se trata de la consulta SQL almacenada). Las vistas son ideales para recoger datos dinámicos, que no necesitan ser almacenados para posteriores consultas, de este modo, siempre podremos obtener la información actualizada de los datos. Otro de los puntos fuertes de esta materialización es que al almacenar la consulta en sí, en lugar del resultado de ésta, ahorramos en espacio de almacenamiento. Por último, si trabajamos con sistemas que aplican análisis interactivos que mandan la consulta en el momento de hacer clic, las vistas son las más apropiadas.
Common Table Expressions, CTEs (Ephemeral)
En algunas ocasiones podremos construir consultas SQL extremadamente complejas. En el momento en que las creamos, entendemos completamente su funcionalidad, pero con el tiempo resulta complejo interpretar para qué nos hicieron falta. Además, es común realizar consultas similares dentro de nuestros modelos, con lo que estaríamos duplicando líneas y líneas de código.
La manera adecuada de resolver esta situación es mediante CTEs, que consisten en subconsultas que se conectan para consolidar esa consulta incomprensible y no reutilizable que teníamos entre las manos. Las CTEs nos facilitan la lectura del código al ser más pequeñas y su reutilización al combinarse para consolidar una consulta compleja. Además, son particularmente útiles si necesitamos calcular agregaciones de los datos, resúmenes o ventanas temporales (como medias móviles).
Incrementales
Algunas de nuestras tablas necesitarán añadir o modificar filas con una determinada periodicidad (cada hora, cada día, cada semana, etc.), de modo que la tabla escale rápidamente con el tiempo. Si necesitamos materializar esos datos en formato tabla, con todas las ventajas que éstas proporcionan, tendremos que ejecutar una misma tabla con una gran cantidad de datos estáticos que seguirá escalando. Este problema se soluciona empleando tablas incrementales.
La materialización incremental permite actualizar únicamente los datos cambiantes de las tablas o añadir nuevas filas para reducir en tiempo de procesamiento y recursos empleados. Además, son útiles cuando utilizamos orquestadores de cargas de datos o planificamos la actualización de los modelos con una periodicidad. Finalmente, cuando trabajamos con tablas gigantes, usar materializaciones incrementales agiliza el proceso de rastreo de cambios.
Customizadas
A medida que nos familiarizamos con DBT, trataremos de darle un uso más personalizado para que la herramienta se ajuste a nuestros proyectos, en lugar de utilizar las estrategias que ya vienen predefinidas. Para ello, existe la posibilidad de crear materializaciones customizadas, que nos proporcionan un control más fino a la hora de almacenar y gestionar nuestros modelos.
Las materializaciones customizadas se pueden emplear para realizar transformaciones específicas de los datos, que no serían posibles mediante el empleo de tablas o vistas. Además, podemos utilizarlas para encontrar el rendimiento óptimo en la ejecución de modelos o para ajustarnos a fuentes de datos no tradicionales. Por último, podemos utilizar estas materializaciones para cumplir con regulaciones de seguridad específicas y para realizar operaciones de limpieza y normalización que vayan más allá de la funcionalidad de DBT.
Conclusión
En este post hemos hablado sobre los tres conceptos más importantes de DBT con el fin de ayudar a dar el primer paso a todo aquel que esté interesado en aprender esta tecnología. Te animo a utilizarla para tu próximo proyecto para que puedas explorar todas sus utilidades y puedas ajustarla a sus necesidades específicas. De esta forma, podrás compararla con otras alternativas que hayas utilizado y comprobar si ha valido la pena.
Esperamos que te haya sido útil el contenido de este post. Te recomendamos visitar la categoría Data Engineering para ver más artículos como este y te animamos a compartirlo con tus contactos para que ellos también puedan leerlos y opinar. ¡Nos vemos en redes!
