
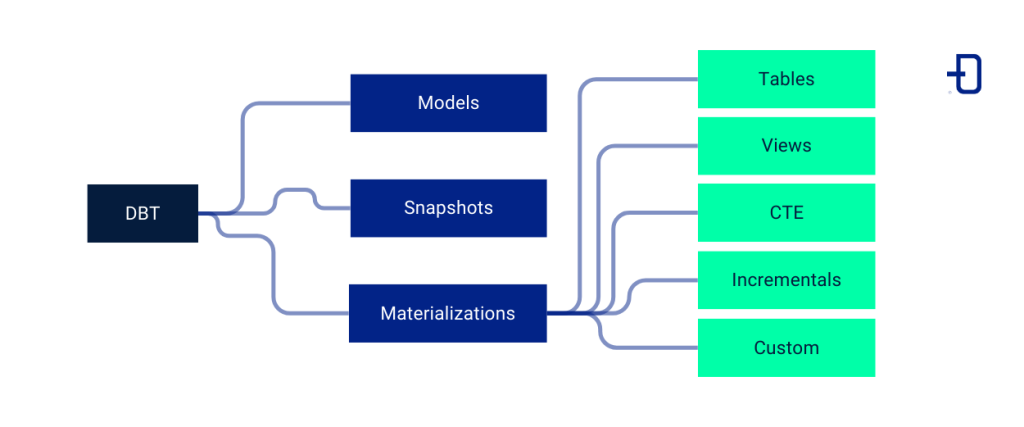
In other discussion spaces we elaborated a comparison between DBT, Pentaho and Spark to perform data transformations. In this post, we will look at some of the key concepts of DBT: models, snapshots and materializations.
Within the context of DBT, we find a series of resources that help us to perform the data transformation process. Each of them has a particular semantics that characterizes it and that might not coincide with the semantics of a concept with the same name outside this scope. The three we are going to discuss are the most basic of this methodology and are essential to start working with DBT.
Working with models, snapshots and materializations in DBT
Models
What we call models in the DBT methodology are actually SQL queries that are responsible for transforming and structuring data in an organized and reproducible way. By employing models, we are able to create a pipeline of small incremental transformations from a set of data. For this to happen, DBT is able to manage the order of execution of the defined models, ensuring that the dependencies between them are correctly resolved.
When we create a model, DBT applies a version to it to help us with the tracking of changes we make. In addition, it allows us to add tests to check that the model is generated correctly and documentation to describe it. This is really useful when working on projects with teams. Subsequently, we will be able to use each of these models created for data analysis, as they integrate seamlessly with various BI tools (such as Looker or Tableau).
Snapshots
You may have ever needed to look up data from a table that has been updated, but you have overwritten it, or you have built your system so that you have several rows for the same data with the changes applied. Can you tell which entry is the one you are looking for? If it hasn’t happened to you, it may seem like a minuscule problem, but in many cases it is not.
DBT snapshots deal with that problem by creating Type-2 Slowly Changing Dimensions tables, not to be confused with a snapshot as we know it. Snapshots in this context identify how rows of data are changing over time and keep a history of those changes. To apply them, we need to identify which columns may change over time.
An example of the functionality of DBT snapshots could be the one we see in the student table below. It shows how the value of the course column changes from failed to passed.
| id | name | dbt_updated_at | dbt_valid_from | dbt_valid_to | course | |
| 1 | Alumn1 | @alumn1.es | 2020-01-01 | 2020-01-01 | 2023-01-01 | failed |
| 2 | Alumn1 | @alumn1.es | 2023-01-01 | 2023-01-01 | null | passed |
Materializations
When defining our models, it is important to know how we need to store them in our project. Materializations are the way in which the data of a model will be collected. They will allow us to optimize the performance in the model executions, generating the models we need, but saving time and system resources. To do this, DBT provides us with different types of materializations that we can use, depending on several factors: the nature of our data, the periodicity of update or addition of entries, the type of transformation we have performed, the frequency of query or other non-predefined type that we want to build.
The types of materializations available to us are as follows:
Tables
When we do not specify a materialization, tables will be the default form in which we will find the data. We should understand this type of materialization as a common physical table, in which data will be stored within a structure of rows and columns. Ideally, we will use tables to store static data or data with infrequent changes that need to solve complex queries or in the shortest possible time.
The use of tables can help us to store data that receives frequent queries, since the stored data will not need to be recalculated for each query. This is useful if we store our materializations in cloud environments that charge us for the number of queries performed or their execution time. In addition, if we are going to use BI tools, the best option is to use tables.
Views
One way to materialize our data in DBT is by using views, which are a logical representation of the data without creating a table (it is the stored SQL query). The views are ideal to collect dynamic data, which do not need to be stored for later queries, so we can always get the updated information of the data. Another strong point of this materialization is that by storing the query itself instead of the query result, we save on storage space. Finally, if we work with systems that apply interactive analysis that send the query at the moment of clicking, the views are the most appropriate.
Common Table Expressions, CTEs (Ephemeral)
Sometimes we can build extremely complex SQL queries. At the moment we create them, we fully understand their functionality, but over time it becomes complex to interpret what we need them for. In addition, it is common to make similar queries within our models, so we would be duplicating lines and lines of code.
The appropriate way to solve this situation is through CTEs, which consist of subqueries that are connected to consolidate that incomprehensible and non-reusable query that we had in our hands. CTEs make the code easier to read because they are smaller and easier to reuse when combined to consolidate a complex query. In addition, they are particularly useful if we need to calculate data aggregations, summaries or time windows (such as moving averages).
Incremental
Some of our tables will need to add or modify rows with a certain periodicity (every hour, every day, every week, etc.), so that the table scales quickly over time. If we need to materialize that data in table format, with all the advantages that these provide, we will have to run the same table with a large amount of static data that will continue to scale. This problem is solved by using incremental tables.
Incremental materialization allows you to update only the changing data in the tables or add new rows to reduce processing time and resources used. In addition, they are useful when using data load orchestrators or when planning to update models periodically. Finally, when working with giant tables, using incremental materializations streamlines the change tracking process.
Customized
As we become more familiar with DBT, we will try to use it in a more customized way so that the tool fits our projects, instead of using the predefined strategies. For this purpose, there is the possibility to create custom materializations, which give us finer control when storing and managing our models.
Custom materializations can be used to perform specific data transformations that would not be possible using tables or views. In addition, we can use them to find the optimal performance in model execution or to adjust to non-traditional data sources. Finally, we can use these materializations to comply with specific security regulations and to perform cleansing and normalization operations that go beyond DBT functionality.
Conclusion
In this post we have talked about the three most important concepts of DBT in order to help take the first step to anyone interested in learning this technology. I encourage you to use it for your next project so that you can explore all its utilities and you can adjust it to your specific needs. This way, you will be able to compare it with other alternatives you have used and see if it has been worth it.
We hope you found the content of this post useful. We recommend you to visit the Data Engineering category to see more articles like this one and we encourage you to share it with your contacts so they can also read it and give their opinion. See you in networks!
