
En esta guía práctica adaptada a 2026, analizaremos cómo DBT se integra con Spark y para qué puede resultarnos útil dicha integración.
¿Qué es DBT y para qué se utiliza?
DBT es un framework que nos facilita el diseño del modelado de datos a lo largo de los diferentes ciclos del mismo. DBT se usa normalmente para el modelado de datos con fines analíticos. De esta manera, utilizando DBT interponemos una capa de desarrollo que adopta un DSL muy cercano al del SQL tradicional para agilizar el desarrollo de ELT.
Esta posibilidad, junto con su capacidad de ser transversal a diferentes almacenes de datos o Data Warehouses, son las principales virtudes que nos ofrece DBT frente al resto de alternativas.
Cómo integrar DBT y Spark paso a paso
A continuación, veremos un caso práctico de cómo utilizar Spark 3.5 como motor de las transformaciones modeladas con DBT 1.9.
Para esta actualización de 2026, utilizaremos las versiones más modernas y estables de todo el stack tecnológico.
Requisitos del sistema
Lo primero que necesitaremos es levantar el entorno adecuado para desarrollar esta POC.
- Java (JDK) 17. Es importante tener en cuenta que Spark 3.5 requiere como mínimo esta versión de Java. Por tanto, hay que asegurarse de tener la variable
JAVA_HOMEconfigurada correctamente. - Python 3.11. Es la versión recomendada de Python para garantizar la compatibilidad con DBT 1.9.
Por otro lado, procedemos a descargar una versión de Spark precompilada con Hadoop 3.3:
- spark-3.5.x-bin-hadoop3
Spark con Thrift JDBC/ODBC Server
A continuación, levantaremos el servicio de Spark utilizando Thrift JDBC/ODBC Server ejecutando el siguiente comando:
./sbin/start-thriftserver.sh --master local[*]Con este comando, levantamos un servicio de Thrift Server en Spark en nuestra máquina local (local[*]) que, a su vez, permite ejecutar consultas SQL interactivas en Spark a través de una conexión JDBC/ODBC. El servicio levantado expone por defecto el puerto 10000 que será utilizado para conectar DBT con Spark.
Si nos conectamos mediante un IDE de desarrollo de bases de datos a la URI jdbc:hive2://localhost:10000, podremos realizar queries directamente sobre Spark, ese es el mismo principio que DBT aprovecha para poder llevar a cabo esta integración.
El proceso de modelado de base de datos es similar al de otros desarrollos con DBT, pero es importante destacar las capacidades específicas de la integración con Spark.
En primer lugar, me gustaría resaltar que permite desarrollar modelos que no solo pueden persistir en un soporte indexado tipo base de datos, sino que también se pueden almacenar en un sistema de archivos y en todos los formatos habituales (parquet, csv, orc, etc.). Esto nos brinda la flexibilidad de movernos a un paradigma de ETL, lo cual es particularmente interesante, ya que en muchas ocasiones es posible que necesitemos trabajar con un modelo de datos que no tenga soporte en un Data Warehouse.
Sin embargo, en la mayoría de las integraciones con DBT, encontramos que este último es una pieza imprescindible dentro de la arquitectura.
Cómo configurar un proyecto de DBT y Spark
En este repositorio de GitHub de Damavis podemos encontrar un código muy sencillo que nos permite levantar un entorno de DBT con las dependencias necesarias y también un proyecto simple de modelado. Por tanto, clonamos el repositorio en local y procedemos a instalar las dependencias de Python mediante Poetry. Aconsejo que se haga mediante un virtualenv. No obstante, hay que tener en cuenta gestionar las dependencias de la forma adecuada.
pip install poetry
poetry installAsegúrate de instalar las versiones compatibles de 1.9:
pip install dbt-core==1.9.0 dbt-spark==1.9.0
pip install "dbt-spark[PyHive]"Es importante que la versión de dbt-core y dbt-spark coincidan en la versión menor (1.9.x). Si se mezclan distintas versiones, por ejemplo core 1.8 con Spark 1.9, pueden darse errores en la resolución de dependencias.
Definición del perfil de DBT para Spark
Una vez instaladas las dependencias, debemos crear nuestro profiles.yml, que contiene la conectividad entre DBT y el servicio de Spark abierto sobre el puerto 10000.
damavis_dbt_spark:
target: local
outputs:
local:
type: spark
method: thrift
host: localhost
schema: test # El esquema (database) donde dbt creará las tablas
port: 10000
threads: 4
connect_retries: 3 # Recomendado para evitar fallos de conexiónDBT tiene varios tipos de conexión con Spark ODBC, Thrift, Http y Session:
- ODBC es un método que nos permite conectarnos mediante el driver de conexión SQL de Databricks.
- Thrift nos permite conectarnos a un server de Spark como podría ser un EMR de Amazon o un HDinsight.
- Http nos permite conectarnos a un cluster pero mediante un servicio HTTP, actualmente (v1.6) solamente se puede integrar con el cluster interactivo de Databricks.
- Session te permite conectar con una sesión de pySpark lanzada en local.
Creación de modelos en DBT
Ya tenemos configurada la conexión entre DBT y nuestro Spark en local. Veamos ahora el código fuente. En el fichero dbt_project.yml encontramos la primera peculiaridad del desarrollo con Spark, el control sobre el formato del fichero:
name: 'damavis_dbt_spark'
version: '1.0.0'
config-version: 2
models:
damavis_dbt_spark:
+file_format: parquet # Recomendamos este formato o 'delta' para producción en 2026
+location_root: /tmp/hive/damavis
+materialized: tableEn versiones anteriores del post (2023), hemos utilizado CSV. Sin embargo, para 2026, el estándar es Parquet o formatos de tabla como Delta Lake o Iceberg. En este caso, usaremos Parquet por cuestiones de eficiencia.
Ejemplo de modelo particionado
Aquí vemos que podemos especificar por defecto que nuestros modelos se persistan con un formato específico mediante file_format o que se almacena por defecto en una ruta específica location_root. DBT soporta múltiples formatos con Spark como parquet, delta, iceberg, hudi, csv, json, text, jdbc, orc, hive o libsvm.
Si ejecutamos dbt run, veremos que se crea la siguiente estructura de carpetas:
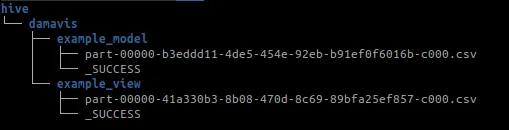
Podemos observar que el esquema de metainformación como es el fichero _SUCCESS se crea cuando el stage de Spark termina correctamente.
En el modelo example_partition_model vemos algunas de las opciones de las que disponemos para persistir los datos:
{{ config(
materialized='table',
partition_by=['year','month'],
file_format='parquet',
options={'compression': 'snappy'}
buckets= 10
) }}
select
id,
2026 as year,
01 as month,
description
from {{ ref('example_view') }}De esta forma, podemos especificar opciones de persistencia al igual que en Spark en el método write.option("header", True).csv("path"). También podemos establecer opciones de partition_by, en nuestro caso por year y month, o la cantidad de registros por cada uno de los ficheros que se almacenan mediante la opción buckets.
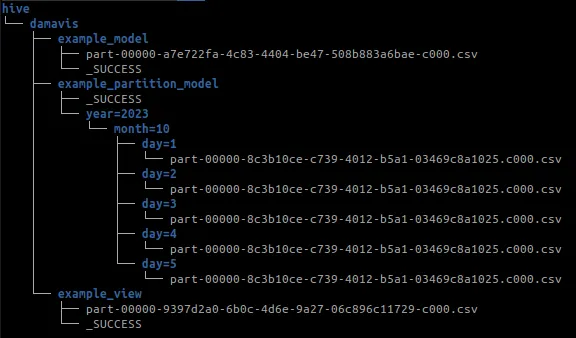
Ejecución de DBT y Spark
Para materializar los modelos, ejecutamos el siguiente comando:
dbt runSi todo está correcto, en la consola de DBT veremos cómo se conecta al Thrift Server y se crean las tablas. Para verificarlo, puedes comprobar si en la carpeta definida en location_root (/tmp/hive/damavis) se encuentra la estructura de directorios creada por Spark conteniendo los ficheros .parquet. Además, se genera un fichero _SUCCESS que indica que el proceso se completó correctamente.
Casos de uso: DBT en el entorno empresarial
Más allá de la parte técnica, integrar DBT con Apache Spark responde a la incipiente necesidad de las empresas que trabajan con grandes volúmenes de datos y necesitan las herramientas adecuadas para procesarlos.
En Damavis ya hemos puesto en producción esta arquitectura en distintos proyectos para cliente. Nuestra experiencia nos demuestra la enorme capacidad que ambas tecnologías poseen a la hora de resolver problemas reales.
A continuación, detallaremos algunos escenarios en los que puede aplicarse con grandes resultados.
Análisis avanzado de datos
En ocasiones, la enorme cantidad de datos generada es tan alta y el formato tan variable (JSON, parquet, csv…) que intentar almacenarlos de la «forma tradicional» es extremadamente lento y costoso.
Para este tipo de casos, Spark se puede utilizar para leer y procesar esos datos desde el almacenamiento de objetos (S3, HDFS…) mientras que DBT permite definir la transformación aplicada (limpieza, agregación…). De esta forma, los datos pueden ser consultados más fácilmente en un sistema de visualización o BI.
Optimización de costes
Definir pipelines optimizados con DBT y Spark para sustituir procesos ETL ineficientes, puede ser clave para reducir los costes de computación. Gracias a técnicas como el particionado o la ejecución incremental, es posible un ahorro considerable del presupuesto.
Conclusión
DBT nos permite desarrollar modelos dentro de un HDFS mediante el uso de Spark como motor de ejecución, permitiendo aprovechar las fortalezas de cada uno de los frameworks.
Por otro lado, DBT puede ayudarnos a modelar de una forma rápida, documentar, aliviar la curva de aprendizaje y, por último, gestionar operaciones relativamente complicadas de desarrollar en Spark como: pruebas de calidad e integridad de los datos en cada ejecución, sistemas de snapshots desde DBT, seeds, etc. Mientras que Spark, por su lado, nos permite utilizar el músculo de un cluster de Spark para tratar con una gran cantidad de datos sin necesidad de un sistema de un Datawarehouse.
La integración de DBT con Spark en 2026 sigue siendo una estrategia acertada para la gestión y transformación de datos.
Si este artículo te ha parecido interesante, te animamos a visitar la categoría Data Engineering para ver otros posts similares a este y a compartirlo en redes. ¡Hasta pronto!
