
In this practical guide adapted to 2026, we will analyse how DBT integrates with Spark and how this integration can be useful for us.
What is DBT and what is it used for?
DBT is a framework that facilitates the design of data modeling throughout the different data modeling cycles. DBT is normally used for data modeling for analytical purposes. In this way, using DBT we interpose a development layer that adopts a DSL very close to that of traditional SQL to speed up ELT development.
This possibility, together with its ability to be transversal to different data warehouses or Data Warehouses, are the main virtues offered by DBT compared to the rest of the alternatives.
How to integrate DBT and Spark step by step
Next, we will see a case study of how to use Spark 3.5 as an engine for transformations modeled with DBT 1.9.
For this 2026 update, we will use the most modern and stable versions of the entire technology stack.
System requirements
The first thing we will need is to raise the right environment to develop this POC.
- Java (JDK) 17. It is important to note that Spark 3.5 requieres at least this version of Java. Therefore, you must ensure that the
JAVA_HOMEvariable is configured correctly. - Python 3.11. This is the recommended version of Python to ensure compatibility with DBT 1.9.
Next, we proceed to download a precompiled version of Spark with Hadoop 3.3:
- spark-3.5.x-bin-hadoop3
Spark with Thrift JDBC/OCBD Server
Then, we will set up the Spark service using Thrift JDBC/OCBD Server by running the following command:
.sbin/start-thriftserver.sh --master local[*]With this command, we launch a Thrift Server service in Spark on our local machine (local[*]) that, in turn, allows to execute interactive SQL queries in Spark through a JDBC/ODBC connection. The raised service exposes by default port 10000 which will be used to connect DBT to Spark.
If we connect via a database development IDE to the URI jdbc:hive2://localhost:10000, we will be able to perform queries directly on Spark, that is the same principle that DBT leverages to be able to perform this integration.
The database modeling process is similar to other DBT developments, but it is important to highlight the specific capabilities of the Spark integration.
First of all, I would like to highlight that it allows us to develop models that can not only persist in an indexed database type support, but can also be stored in a file system and in all the usual formats (parquet, csv, orc, etc.). This gives us the flexibility to move to an ETL paradigm, which is particularly interesting, since in many occasions we may need to work with a data model that is not supported in a Data Warehouse.
However, in most integrations with DBT, we find that the latter is an indispensable piece within the architecture.
DBT and Spark project configuration
In this GitHub repository of Damavis we can find a very simple code that allows us to build a DBT environment with the necessary dependencies and also a simple modeling project. So, we clone the repository locally and proceed to install the Python dependencies using Poetry. I recommend that this is done using a virtualenv. However, it is important to manage dependencies appropiately.
pip install poetry
poetry installEnsure that you install the compatible versions of 1.9:
pip install dbt-core==1.9.0 dbt-spark==1.9.0
pip install "dbt-spark[PyHive]"It is important that the versions of dbt-core and dbt-spark match in the minor version (1.9.x). If different versions are mixed, for example core 1.8 with Spark 1.9, errors may occur in dependency resolution.
Definition of the DBT profile for Spark
Once the dependencies are installed, we must create our profiles.yml, which contains the connectivity between DBT and the Spark service opened on port 10000.
damavis_dbt_spark:
target: local
outputs:
local:
type: spark
method: thrift
host: localhost
schema: test # The schema (database) where dbt will create the tables
port: 10000
threads: 4
connect_retries: 3 # Recommended to prevent connection faliuresDBT has several connection types with Spark ODBC, Thrift, Http and Session:
- ODBC is a method that allows us to connect via Databricks SQL connection driver.
- Thrift allows us to connect to a Spark server such as an Amazon EMR or HDinsight.
- Http allows us to connect to a cluster but through an HTTP service, currently (v1.6) it can only be integrated with the Databricks interactive cluster.
- Session allows you to connect to a pySpark session launched locally.
Creating models in DBT
We have already configured the connection between DBT and our Spark locally. Let’s see now the source code. In the dbt_project.yml file we find the first peculiarity of Spark development, control over the file format:
name: 'damavis_dbt_spark'
version: '1.0.0'
config-version: 2
models:
damavis_dbt_spark:
+file_format: parquet # We recommend this format or 'delta' for production in 2026
+location_root: /tmp/hive/damavis
+materialized: tableIn previous versions of this article (2023), we used CSV. However, by 2026 the standard is Parquet or table formats such as Delta Lake or Iceberg. In this case, we will use Parquet for efficiency reasons.
Example of a partitioned model
Here we see that we can specify by default that our models are persisted with a specific format using file_format or that it is stored by default in a specific path location_root. DBT supports multiple formats with Spark such as parquet, delta, iceberg, hudi, csv, json, text, jdbc, orc, hive or libsvm.
If we execute dbt run, we will see that the following folder structure is created:
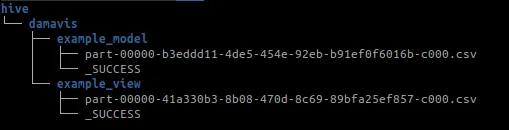
We can see that the meta-data schema such as the _SUCCESS file is created when the Spark stage terminates successfully.
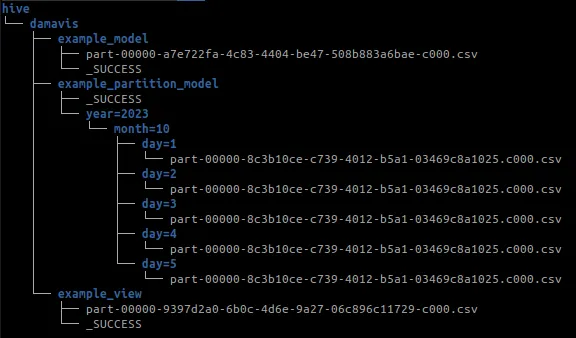
In the example_partition_model we see some of the options we have to persist the data:
{{ config(
materialized= 'table',
partition_by=['year','month'],
file_format='parquet',
options={'compression': 'snappy'}
buckets= 10
) }}
select
id,
2026 as year,
01 as month,
description
from {{ ref('example_view') }}In this way, we can specify persistence options as in Spark in the method write.option("header", True).csv("path"). We can also set partition_by options, in our case by year and month, or the number of records per each of the files that are stored using the buckets option.
Running DBT and Spark
To materialise the models, we execute the following command:
dbt runIf everything is correct, we will see how it connects to the Thrift Server and creates the tables in the DBT console. To verify this, you can check if the directory structure created by Spark containing the .parquet file is located in the folder defined in location_root (/tmp/hive/damavis). In addition, a _SUCCESS file is generated indicating that the process was completed successfully.
Use cases: DBT in the business environment
Beyond the technical aspects, integrating DBT with Apache Spark responds to the emerging need of companies that work with large volumes of data and require the right tools to process it.
At Damavis, we have already implemented this architecture in various client projects. Our experience demonstrates the enormous capacity of both technologies when it comes to solving real problems.
Below, we will detail some scenarios in which it can be applied with great results.
Advanced data analysis
Sometimes, the enormous amount of data generated is so high and the format so variable (JSON, parquet, csv…) that trying to store it in the “traditional way” is extremely slow and costly.
In these cases, Spark can be used to read and process this data from object storage (S3, HDFS, etc.), while DBT allows you to define the transformation applied (cleaning, aggregation, etc.). This makes it easier to query the data in a visualisation or BI system.
Cost optimization
Defining optimized pipelines with DBT and Spark to replace inefficient ETL processes can be key to reducing computing costs. Thanks to techniques such as partitioning or incremental execution, considerable budget savings are possible.
Conclusion
DBT allows us to develop models within an HDFS by using Spark as the execution engine, allowing us to leverage the strengths of each of the frameworks.
On the other hand, DBT can help us to model in a fast way, document, ease the learning curve and, finally, manage relatively complicated operations to develop in Spark such as: data quality and integrity tests in each execution, snapshot systems from DBT, seeds, etc. While Spark, on the other hand, allows us to use the muscle of a Spark cluster to deal with a large amount of data without the need of a Datawarehouse system.
The integration of DBT and Spark in 2026 remains a sound strategy for data management and transformation.
If you found this article interesting, we encourage you to visit the Data Engineering category to see other posts similar to this one and to share it on networks. See you soon!
