
Hoy me gustaría tratar un tema que, desde mi punto de vista, es muy importante y que probablemente sea el santo grial de los proyectos de ingeniería de datos. Sin embargo, en rara ocasión llegamos al nivel de madurez necesario para poder aplicarlo de una manera total. Me refiero, por supuesto, al Data Governance y su aplicación práctica.
El Data Governance es la última estación dentro de la maduración de nuestros proyectos de tratamiento de datos. Esto no quiere decir que se deba dejar para el final y aplicarlo entonces, no. Esto significa que es, posiblemente, la fase más difícil de completar dentro del camino Data Driven de nuestra organización.
Una de las principales dificultades que encontramos a la hora de aplicar la gestión del Data Governance, es la dificultad técnica. Las herramientas que el mercado ofrece y sobre todo las herramientas de software libre son escasas. Pero dentro del stack de Apache podemos encontrar una que destaca por su funcionalidad y sencillez, Apache Atlas.
¿Qué es Apache Atlas?
Apache Atlas es un proyecto que fue incubado por Hortonworks y traspasado a la fundación Apache en 2015. Desde entonces ha sido mantenida por la comunidad y actualmente nos encontramos en la versión 2.2.
Apache Atlas es una herramienta enfocada a resolver la mayoría de los principales retos del Data Governance. Esta herramienta nos permite construir un catálogo con todos los datos de nuestra organización y presentar dicho catálogo de una manera fácil e intuitiva.
Arquitectura de Apache Atlas
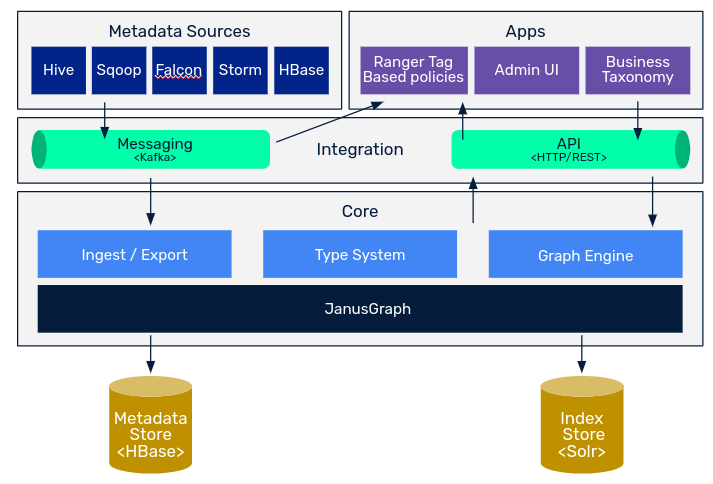
Core
El módulo Type System es el módulo principal de la herramienta, aporta la suficiente flexibilidad como para poder diseñar y almacenar cualquier tipo de información.
Para ello, utiliza los conceptos de Type y Entity de la misma manera que en programación orientada a objetos se utiliza clase e instancia. De esta forma, Apache Atlas nos provee de una herramienta que, modelando Types, podremos almacenar unidades de información respecto a esos Types llamadas Entities.
Dentro del core podemos encontrar el sistema de ingesta y exportación de Apache Atlas, que nos permite proveer y extraer datos del sistema. Las formas qué tenemos para hacerlo son las siguientes:
- Import: Zip, Api Rest y Kafka.
- Export: Api Rest, Incremental y Kafka (principalmente para auditoría).
Por último, el módulo Graph Engine se encarga de toda la parte de búsqueda e indexado de la información, para lo que utiliza el motor de grafos JanusGraph por debajo. Janus es una base de datos de grafos de código abierto qué es utilizada por Apache Atlas para representar las relaciones entre entidades dentro del catálogo. A su vez, se utiliza para realizar búsquedas sobre estas relaciones. Por ejemplo, para encontrar todas las entidades que son derivadas de una fuente de información, estaríamos utilizando JanusGraph.
Como backend, Atlas hace uso de dos tecnologías de almacenamiento. La primera sería Hbase, la cual es una base de datos orientada a columnas y de tipo clave valor. Básicamente en Hbase se estaría almacenando toda la información de las entidades, toda la metainformación de nuestro catálogo.
Por otro lado, Atlas también hace uso Apache Solr, una base de datos orientada a la indexación para poder acceder a la información de una manera más rápida. Esta funcionalidad nos permitirá realizar acciones de discovering durante el uso cotidiano de la información, con las capacidades que posteriormente veremos de la herramienta.
Integración
La forma principal de integración con la herramienta es a través del módulo API. El módulo API no es más qué una API HTTP REST que es desplegada por defecto en el puerto 21000, actualmente se encuentra la versión V2. Aparte de aportar toda la funcionalidad CRUD sobre los Types y Entities, la API también provee endpoints de consultas básicas y avanzadas y exploración.
Atlas también ofrece la posibilidad de integrar el catálogo con importaciones y exportaciones en tiempo real. La forma en la que nos ofrece esta funcionalidad es Kafka. Esta forma de integración es utilizada principalmente para la notificación de cambios en tiempo real e integración con otras herramientas de Data Governance como Ranger para la gestión de permisos de lectura del data lake.
Apps
La principal aplicación que se conecta con el resto de módulos es la aplicación web, que es desplegada por herramienta. Esta aplicación es la principal interfaz con el usuario, ya que de una forma muy usable podemos interactuar con el catálogo de metadatos.
Metadata Sources
Los metadatos son aquellas fuentes que ya están soportadas de manera nativa sobre Apache Atlas.
Atlas soporta la ingesta y gestión de metadatos desde las siguientes fuentes: Hive, HBase, Sqoop, Storm y Kafka.
Conclusión
Hoy hemos visto la arquitectura principal de Apache Atlas. En el siguiente post, veremos conceptos básicos acerca de la herramienta, funcionalidades que nos ofrece y la forma de desplegar y trabajar con ella.
Si este artículo te ha parecido interesante, te animamos a visitar la categoría Data Engineering para ver otros posts similares a este y a compartirlo en redes. ¡Hasta pronto!
