
Today I would like to deal with a topic that, from my point of view, is very important and is probably the holy grail of data engineering projects. However, we rarely reach the necessary level of maturity to be able to apply it in a complete way. I am referring, of course, to Data Governance and its practical application.
Data Governance is the last station in the maturation of our data processing projects. This does not mean that it should be left to the end and applied then, it doesn’t. It means that it is possibly the most difficult phase to complete within the Data Driven path of our organization.
One of the main difficulties we face when implementing Data Governance management is the technical difficulty. The tools that the market offers and especially the free software tools are limited. But within the Apache stack we can find one that stands out for its functionality and simplicity, Apache Atlas.
What is Apache Atlas?
Apache Atlas is a project that was incubated by Hortonworks and handed over to the Apache Foundation in 2015. Since then, it has been maintained by the community and we are currently at version 2.2.
Apache Atlas is a tool focused on solving most of the main challenges of Data Governance. This tool allows us to build a catalog with all the data of our organization and present this catalog in an easy and intuitive way.
Apache Atlas Architecture
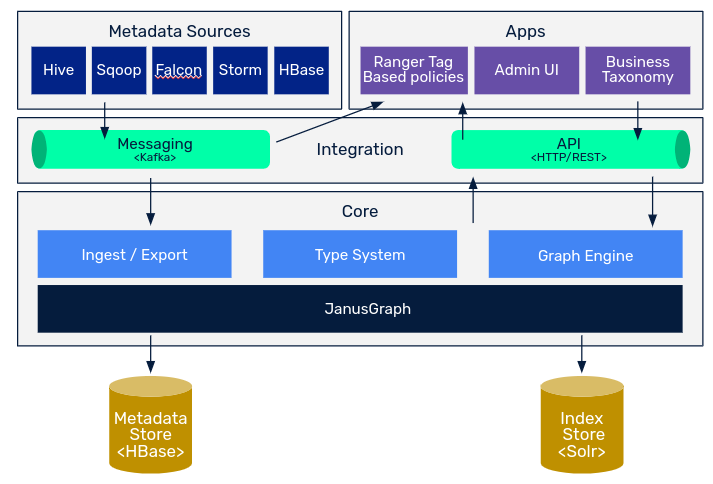
Core
The Type System module is the main module of the tool, providing enough flexibility to be able to design and store any type of information.
To do so, it uses the concepts of Type and Entity in the same way that object-oriented programming uses class and instance. In this way, Apache Atlas provides us with a tool that, by modeling Types, we will be able to store units of information regarding those Types called Entities.
Within the core we can find the Apache Atlas ingest and export system, which allows us to ingest and extract data from the system. The ways we have to do it are the following:
- Import: Zip, Api Rest and Kafka.
- Export: Api Rest, Incremental and Kafka (mainly for auditing).
Finally, the Graph Engine module takes care of all the search and indexing of the information, using the graph engine JanusGraph underneath. Janus is an open source graph database which is used by Apache Atlas to represent the relationships between entities within the catalog. In turn, it is used to perform searches on these relationships. For example, to find all entities that are derived from an information source, we would be using JanusGraph.
As a backend, Atlas makes use of two storage technologies. The first one would be Hbase, which is a column-oriented database of key-value type. Basically in Hbase we would be storing all the information of the entities, all the meta-information of our catalog.
On the other hand, Atlas also makes use of Apache Solr, a database oriented to indexing in order to access the information in a faster way. This functionality will allow us to perform discovering actions during the daily use of the information, with the capabilities of the tool that we will see later.
Integration
The main form of integration with the tool is through the API module. The API module is nothing more than an HTTP REST API that is deployed by default on port 21000, currently in version V2. Besides providing all the CRUD functionality on Types and Entities, the API also allows basic and advanced query and exploration endpoints.
Atlas also offers the possibility to integrate the catalog with real-time imports and exports. The form in which it offers this functionality is Kafka. This form of integration is mainly used for real-time change notification and integration with other Data Governance tools such as Ranger for managing data lake read permissions.
Apps
The main application that connects with the rest of the modules is the web application, which is deployed by tool. This application is the main interface with the user, since in a very usable way we can interact with the metadata catalog.
Metadata Sources
Metadata are those sources that are already natively supported on Apache Atlas.
Atlas supports the ingestion and management of metadata from the following sources: Hive, HBase, Sqoop, Storm and Kafka.
Conclusion
Today we have seen the main architecture of Apache Atlas. In the next post, we will see basic concepts about the tool, functionalities it offers and how to deploy and work with it.
If you found this article interesting, we encourage you to visit the Data Engineering category to see other posts similar to this one and to share it on social networks. See you soon!
