
En el mundo de la ingeniería de datos, el uso de orquestadores de tareas es clave para asegurar que la información llega en el momento adecuado y de la forma correcta. Uno de los orquestadores más extendidos, y que ya hemos analizado en varios artículos de este blog, es Airflow. Sin embargo, existen otras opciones que, a pesar de tener menos popularidad, pueden resultar muy útiles en ciertos entornos o casos de uso.
¿Qué es Dagster?
Dagster es un orquestador de tareas open source que permite automatizar los flujos de trabajo, lo cual es una parte vital en todo proceso ETL o ELT. A diferencia de otras herramientas como Airflow que se centran más en las tareas, en Dagster el elemento principal son los DataAssets.
A lo largo de este artículo, veremos cómo implementar un flujo de tareas simple en Dagster. Para ello, leeremos un fichero (el dataset CNN-DailyMail News Text Summarization), aplicaremos embeddings al texto que hay en él y escribiremos el resultado en otro fichero distinto.
Ejemplo de flujo de trabajo con Dagster
La implementación de este flujo de trabajo constará de 3 fases. En la primera, se lee el fichero, en el segundo paso se aplican los embeddings y, por último, se escribe el resultado.
Definición de funciones y tareas
Para llevar a cabo el ejemplo, lo primero que haremos será definir 3 funciones con el decorador de @op.
@op
def read_file() -> dict:
"""Example of a Dagster op that reads a CSV."""
values = {}
limit = 1000
with open('/usr/src/app/dagster_example/ops/file.csv', newline='') as csvfile:
reader = csv.reader(csvfile, delimiter=',', quotechar='"')
for row in reader:
if len(row)>1:
values[row[0]]=row[1]
limit+=1
if limit>=10000:
break
return values
# En este caso, se ha aplicado un límite de lectura para evitar sobrecargar el worker, ya que esto es solo un ejemploLa tarea que se ha definido en este código lee un CSV y lo transforma en un diccionario que pasa a una tarea futura.
@op
def embed_file(texts: dict) -> dict:
model = TextEmbedding(model_name="BAAI/bge-small-en-v1.5")
embeddings = model.embed(texts.values())
embedded_documents = dict(zip(texts.keys(), embeddings))
return embedded_documentsEn este caso, esta tarea carga un modelo de embedding y aplica embeddings al diccionario de documentos creado anteriormente. Finalmente, devuelve un diccionario con el resultado.
@op
def write_embeddings(texts: dict, embeddings: dict):
with open('embedded_texts.csv', 'w', newline='') as csvfile:
fieldnames = ['id', 'text', 'embedding']
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
for key in texts.keys():
writer.writerow({'id':key,'text':texts[key],'embedding':embeddings[key]})Por último, esta tarea recibe los dos diccionarios generados en las tareas anteriores y escribe el resultado en un CSV.
Establecer el flujo de trabajo
Una vez hemos definido las 3 tareas, definimos un flujo de trabajo con las mismas usando el decorador de @job:
@job
def embedding():
"""Example of a simple Dagster job."""
text_file = read_file()
embeddings = embed_file(text_file)
write_embeddings(text_file,embeddings)Este flujo de trabajo aplica las 3 tareas anteriores. En primer lugar, lee el fichero, después aplica los embeddings y, finalmente, usa ambos outputs para generar un CSV final. Una vez definimos este trabajo, podemos ver el resultado en la UI de Dagster.
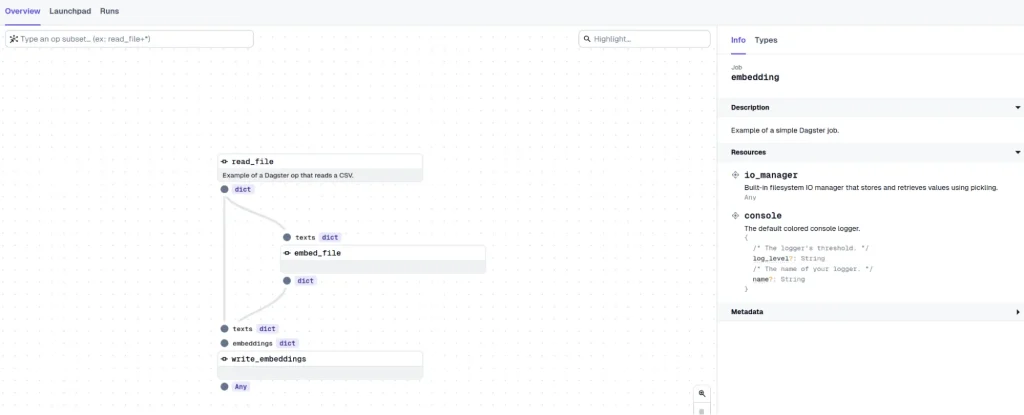
En la imagen anterior podemos ver que la UI de Dagster ha generado el flujo de trabajo con el orden apropiado.
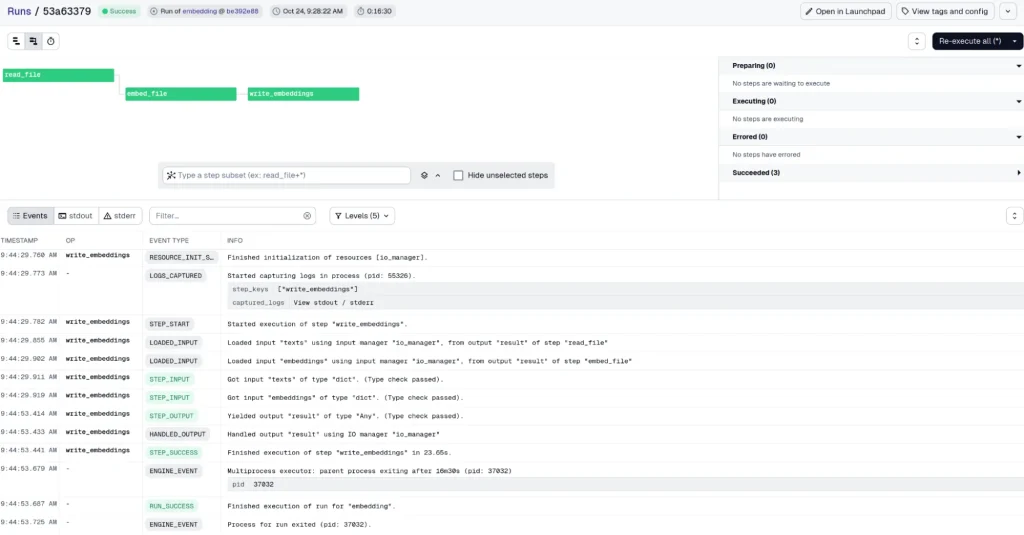
Si vamos a la sección de launchpad, podemos ejecutar el trabajo. Pasado un tiempo, vemos que acaba sin problemas con un sistema de logging bastante robusto.
Además, podemos definir que este trabajo esté programado siguiendo un cron job con el decorador de @schedule.
@schedule(
cron_schedule="0 9 * * 1-5",
job=embedding,
execution_timezone="Europe/Madrid",
)
def embedding_schedule(context):
"""Example of how to setup a weekday schedule for a job."""
date = context.scheduled_execution_time.strftime("%Y-%m-%d")
return {"ops": {"embedding": {"config": {"date": date}}}}El resultado podemos verlo en el siguiente flujo de trabajo automatizado en la UI:

Conclusión
Dagster nos permite definir flujos de trabajos arbitrarios en Python, ofreciendo mucha flexibilidad sobre lo que podemos implementar. Gracias a esta capacidad, es posible implementar cualquier flujo ETL o ELT que sea necesario. Además, Dagster expone estos flujos con una UI simple de entender, junto con un logging nativo considerable. Todas estas características lo convierten en una opción interesante para la automatización de flujos de trabajo.
Hasta aquí nuestro post de hoy. Si te ha parecido interesante, te animamos a visitar la categoría Software para ver artículos similares y a compartirlo en redes con tus contactos. ¡Hasta pronto!
