
Los continuos avances en modelos de Inteligencia Artificial han facilitado en gran medida la vida de los usuarios. La evolución de la IA generativa ha abierto un amplio abanico de posibilidades y allanado el camino a los desarrolladores hasta el punto de que ya pueden tener un chatbot personalizado en su propia máquina.
En este artículo, exploramos cómo construir un asistente de IA en un entorno local a partir de FastAPI, los modelos de Ollama y la librería LlamaIndex. Primero abordaremos estas tres tecnologías desde un punto de vista teórico para después pasar a la práctica y ver cómo se integran con un ejemplo sencillo.
FastAPI para dar servicio al chatbot
FastAPI es un framework que ayuda a los desarrolladores a crear webs, servicios o aplicaciones que otras apps pueden utilizar para intercambiar información. Destaca por su simplicidad, siendo una herramienta que no presenta una curva de aprendizaje muy elevada y que es ideal para sistemas grandes por su escalabilidad.
El funcionamiento de FastAPI es sencillo. Se basa en uno de los lenguajes más populares y extendidos en la actualidad, Python. A través de él, el programador define una serie de reglas (qué información se puede pedir y qué se devuelve) y FastAPI se encarga de recibir los inputs, validar la solicitud y enviar la respuesta correspondiente.
De esta forma, los desarrolladores son capaces de crear endpoints que permitirán a las aplicaciones realizar ese intercambio de datos.
Ollama: Modelos de IA en local
Ollama es una herramienta de código abierto que nos permite tener nuestro propio LLM en el ordenador sin necesidad de conexión a internet. Una vez lo instalemos en nuestro entorno local y descarguemos un modelo (llama3, mistral, Gemma, etc.), podremos hablar con él (o bien desde la Terminal, o bien desde una interfaz gráfica estilo ChatGPT) e integrarlo con otras aplicaciones o APIs.
La principal ventaja de Ollama es que todo ocurre dentro de nuestro entorno local. Gracias a ello, nuestros datos estarán completamente seguros. Si, además, tenemos un buen hardware, conseguiremos grandes resultados a nivel de velocidad.
Extracción e indexación de datos con LlamaIndex
Antes de definir qué es y en qué consiste LlamaIndex, vamos a detenernos en explicar brevemente lo que es un RAG. Retrieval Augmented Generation (RAG) es una técnica consistente en combinar las capacidades de un LLM con la obtención de información proveniente de fuentes externas. En los artículos Retrieval Augmented Generation: ¿Qué es el RAG? e Implementaciones y extensiones de RAG analizamos este concepto en detalle.
LlamaIndex no es más que una biblioteca de Python utilizada para generar RAGs de una forma muy fácil. Extrae el texto, lo indexa, lo busca y lo conecta al modelo.
Caso práctico: Crea un chatbot sencillo
Una vez que ya conocemos qué son y para qué se utilizan FastAPI, Ollama y LlamaIndex, llega el momento de ponerlo en práctica mediante un ejemplo sencillo.
Requisitos previos
Antes de comenzar, repasaremos algunos de los requisitos necesarios para que el caso de uso que vamos a realizar funcione correctamente:
- Es recomendable disponer de un ordenador de entre al menos 8 y 16 GB de RAM. Ollama dispone de varios modelos de diferentes tamaños. La elección de uno u otro dependerá de la capacidad de tu máquina.
- Para conseguir buenos resultados a nivel de rendimiento, se aconseja contar con una GPU moderna y una CPU de, al menos, 4 núcleos. Los modelos de Ollama tendrán un rendimiento mucho mayor si caben completamente en la VRAM de la GPU.
- En cuanto al espacio en disco, lo ideal es destinar unos 20 GB para trabajar con modelos y datos.
- El ejemplo está basado en macOS, aunque puede adaptarse a otros sistemas operativos como Linux o Windows.
Primeros pasos con FastAPI
En primer lugar, crearemos un nuevo directorio que será la raíz del proyecto ejecutando desde nuestra terminal:
mkdir fastapi-rag-test
cd fastapi-rag-testAdemás, estableceremos el entorno virtual que usaremos para trabajar en el proyecto:
python -m venv .venv
# Para activarlo, lanzamos el comando
source .venv/bin/activate Seguidamente, instalamos FastAPI y Uvicorn con el siguiente comando:
pip install fastapi uvicorn requestsUvicorn es un servidor web ligero que permite ejecutar FastAPI desde el navegador y hacerle peticiones HTTP.
En esta ecuación, FastAPI actúa como capa intermedia entre el modelo y el usuario separando la tecnología subyacente de la lógica de negocio. ¿Qué implicaciones tiene esto? Significa que, aunque ahora estamos usando Ollama, podríamos perfectamente cambiar a otro sistema (por ejemplo, ChatGPT) sin que afecte a otras aplicaciones que ya consumen esta API. Esto proporciona gran flexibilidad, pues únicamente sería necesario modificar la lógica interna del endpoint si, llegado el momento, queremos trabajar con otros modelos.
Instalación de Ollama
El siguiente paso sería dirigirnos a la web oficial de Ollama y descargamos el instalador para nuestro sistema operativo. Una vez instalado, lanzamos el comando ollama run llama3 para trabajar con el modelo llama3 y verificar que la instalación es correcta.
Dentro del directorio fastapi-rag-test, crearemos el archivo main.py y añadiremos el siguiente contenido:
from fastapi import FastAPI
from pydantic import BaseModel
import requests
app = FastAPI()
class ChatRequest(BaseModel):
message: str
model: str = "llama3"
@app.post("/chat")
def chat_with_ollama(request: ChatRequest):
url = f"http://localhost:11434/api/generate"
payload = {
"model": request.model,
"prompt": request.message,
"stream": False
}
response = requests.post(url, json=payload)
if response.status_code == 200:
return {"response": response.json()["response"]}
else:
return {"error": "Error al conectarse con Ollama", "details": response.text}Después, y desde el Terminal, lanzamos FastAPI ejecutando:
uvicorn main:app --reloadSi ahora accedemos desde nuestro navegador a http://localhost:8000/docs, veremos la interfaz gráfica de FastAPI y podremos empezar a comunicarnos con nuestro modelo.
Al hacer clic en el botón POST, se nos abre un desplegable donde introducir la pregunta que queremos hacerle al LLM. Si pulsamos en Try it out, se habilitará el Request body que es donde introduciremos la información que queremos solicitar al modelo.
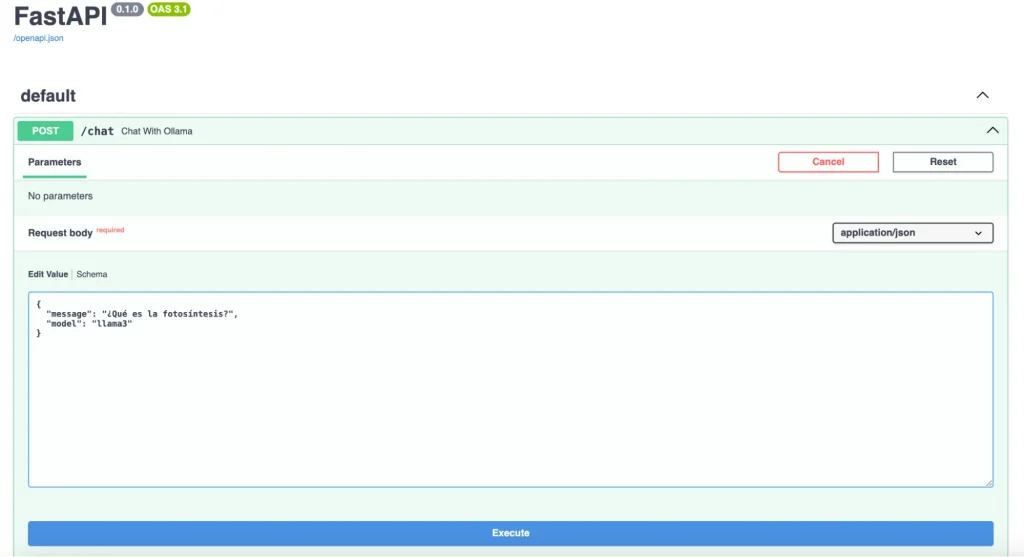
Seguidamente, pulsaremos en Execute y, pasados unos segundos, el modelo nos devolverá la información solicitada.
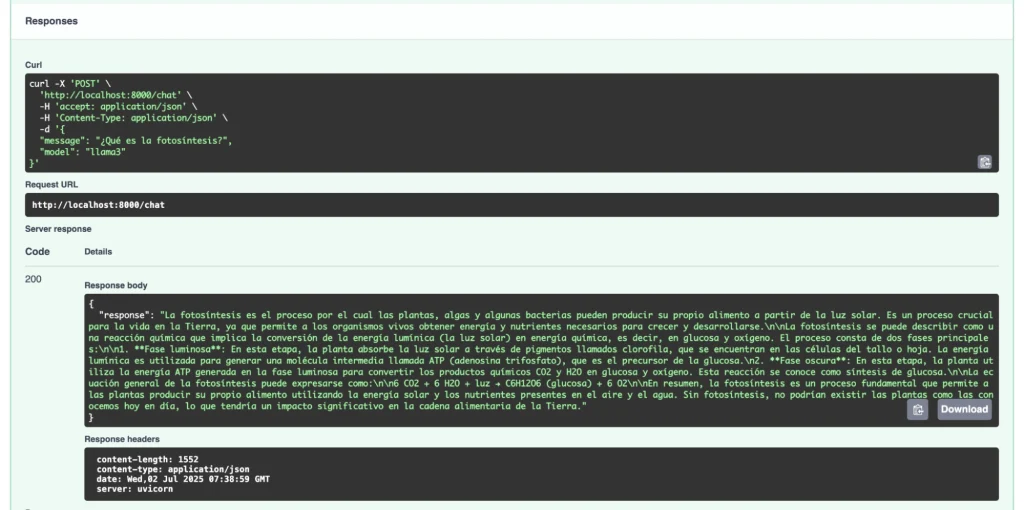
El usuario lanza una petición a través de FastAPI que es respondida por Ollama en función del conocimiento interno del modelo (en este caso, llama3) que ha sido previamente entrenado. En este caso, no se está nutriendo de ninguna fuente de información externa, se basa únicamente en lo que conoce de ese entrenamiento.
Hasta aquí, hemos conseguido crear un chat simple con FastAPI y Ollama. Ya tenemos listo un LLM que responde a preguntas desde nuestra propia máquina, sin necesidad de conectarse a Internet.
Crea un chatbot personalizado en local
A continuación, incorporaremos algo más de complejidad a la ecuación creando un sistema de RAG con LlamaIndex. Hasta ahora, las respuestas que nos da el modelo se basan únicamente en su conocimiento interno. Lo que haremos será agregarle la capacidad de consultar documentos externos y que las respuestas que nos proporcione sean en función a ellos. En este caso, vamos a transformar a nuestro LLM en un experto profesor que nos ayudará a preparar las oposiciones.
Construye un RAG
Para ello, realizamos algunos cambios en el archivo main.py, que quedaría de la siguiente forma:
from fastapi import FastAPI, Request
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
from llama_index.llms.ollama import Ollama
app = FastAPI()
# Cargamos los documentos en el directorio local /data
documents = SimpleDirectoryReader("data").load_data()
# Indicamos al LLM que el modelo usado es llama3. Es importante haber ejecutado previamente 'ollama run llama3'
llm = Ollama(model="llama3")
# Creamos el índice de vectores
index = VectorStoreIndex.from_documents(documents, llm=llm)
# Creamos el chat para comunicarnos con el LLM
query_engine = index.as_query_engine()
@app.post("/chat")
async def chat(request: Request):
data = await request.json()
question = data.get("message")
response = query_engine.query(question)
return {"response": str(response)}Como podemos observar, se han importado nuevas librerías de LlamaIndex y también se han aplicado algunos cambios para que el modelo extraiga la información del directorio /data.
- llama-index. Es la librería principal de LlamaIndex que nos permitirá conectar los documentos que carguemos con el LLM para hacerle las preguntas correspondientes.
- llama-index-llms-ollama. Se utiliza para que el modelo de Ollama que tenemos en local se comunique con LlamaIndex.
Para instalar LlamaIndex, tenemos que ejecutar:
pip install llama-index llama-index-llms-ollamaEn este punto, crearemos un nuevo directorio, /data, donde almacenaremos los documentos que contienen la información que nos suministrará el modelo cuando le preguntemos. Añadiremos dos archivos de ejemplo, doc1.txt y doc2.txt.
La estructura final del proyecto debería tener la siguiente forma:
fastapi-rag-test/
├── data/
│ ├── doc1.txt
│ └── doc2.txt
├── main.py
└── .venv/Dentro de la carpeta /data, añadiremos los documentos con temas relacionados con las oposiciones que estamos preparando (por ejemplo, la Constitución Española), que el modelo tomará como fuente de datos.
Una vez modificado el archivo main.py y subidos los documentos, ejecutamos:
uvicorn main:app --reload Cómo lanzar peticiones al RAG
A través de nuestro navegador, volvemos a acceder a http://127.0.0.1:8000/docs.
En esta ocasión, le haremos al modelo una pregunta sobre algo concreto que se encuentra en los documentos que hemos añadido en la carpeta data.
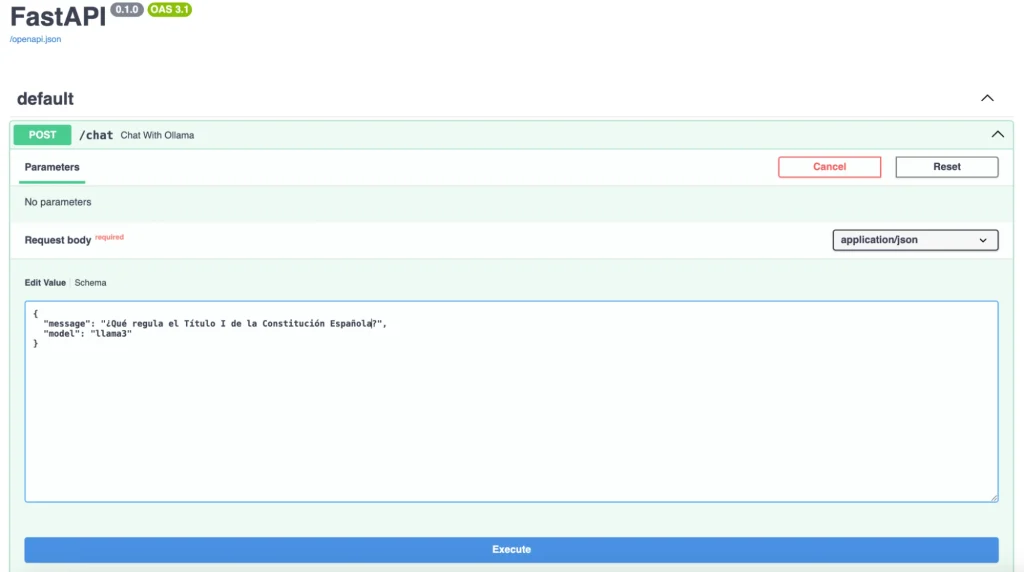
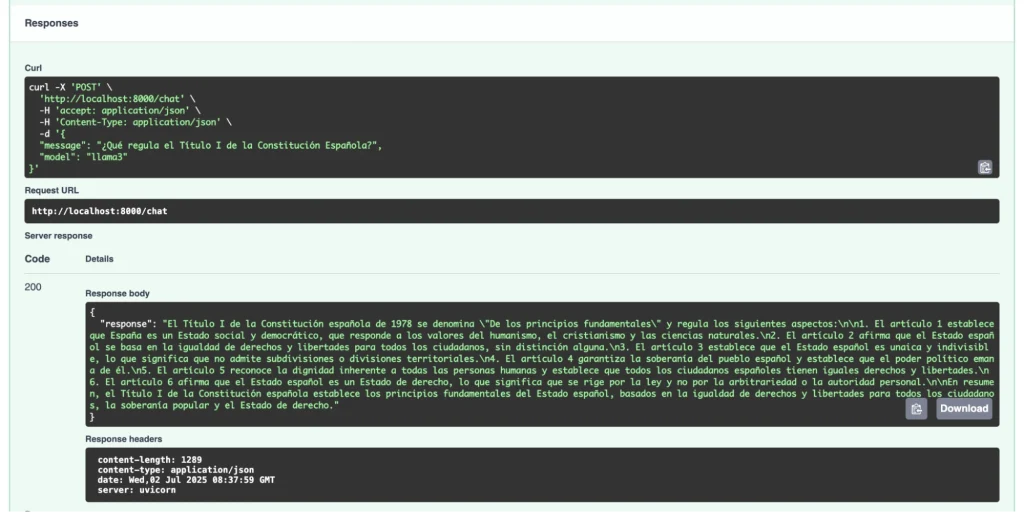
Tal y como podemos apreciar, el LLM nos está contestando en base a la información que ha encontrado en dichos documentos.
¿De qué manera funcionan los tres componentes integrados? El usuario lanza una pregunta (una petición POST) a través de un navegador web o frontend con FastAPI. FastAPI la recibe y, mediante LlamaIndex, busca en las fuentes de datos. Una vez revisa los documentos, LlamaIndex extrae la información relevante y se la envía a Ollama. Basándose en ella, Ollama elabora una respuesta que es devuelta por FastAPI al usuario a través del navegador.
Próximos pasos
Para terminar de construir nuestro modelo profesor de oposiciones, bastaría con agregar nuevos documentos o temas dentro de la carpeta /data. Se podrían añadir desde documentos oficiales hasta nuestros propios apuntes personalizados.
No obstante, hay que tener en cuenta que, en el ejemplo realizado, el LLM únicamente lee documentos .txt. En caso de que sea necesario agregar otros formatos de texto (.pdf, .docx, etc.) habría que considerar instalar dependencias adicionales.
Una mejora interesante que se podría aplicar al proyecto es utilizarlo con una interfaz gráfica tipo Open WebUI. De esta forma, podremos obtener una experiencia muy parecida a la que ofrecen LLMs populares como ChatGPT.
Conclusión
La posibilidad de construir un chatbot en un entorno local capaz de aprender del contenido suministrado por el usuario, supone una gran evolución en el área de la Inteligencia Artificial. La proliferación de herramientas y frameworks open source en esta línea está permitiendo a los desarrolladores explorar nuevas vías y ser partícipes de estos avances tecnológicos.
Si este artículo te ha parecido interesante, te animamos a visitar la categoría Data Engineering para ver otros posts similares a este y a compartirlo en redes. ¡Hasta pronto!
