
Cuando se trata de lidiar con cantidades importantes de datos, la forma en que los guardas puede marcar la diferencia entre el éxito y el fracaso. En este post, vamos a echar un vistazo a un formato de archivo que quizás no sea el más popular, pero que definitivamente vale la pena considerar: Parquet. Te explicaremos qué problemas resuelve y cómo funciona, sin ahorrarnos los términos técnicos clave. Pero más allá de eso, el objetivo es transmitir la importancia de elegir el formato de archivo adecuado para cada caso de uso.
Apache Parquet se define como un formato de archivos columnar. Fue creado en 2013 en un esfuerzo entre los ingenieros de Twitter y Cloudera para afrontar las limitaciones que se estaban encontrando a la hora de tratar con grandes cantidades de datos en bulk. En 2015, Apache Foundation anunció Parquet como uno de sus proyectos top-level.
La definición de Parquet introduce dos conceptos: «formato de archivos» y «columnar». ¿Qué significan exactamente?
Formato de archivo
Un formato de archivo no es más que una especificación que define la estructura y organización de la información contenida en un fichero. Estos formatos determinan cómo se almacenan los datos, qué tipo de datos pueden contener y cómo se pueden consultar y manipular. Los formatos varían según el tipo de datos y el propósito. Por ejemplo, tenemos TXT o DOCX para texto, JPEG o PNG para imágenes, MP3 o WAV para audio, y MP4 o AVI para vídeo.
En el ámbito de los datos, los formatos más comunes son CSV, JSON y XML, aunque existen otros menos conocidos como Avro, Protocol Buffers y, por supuesto, Parquet. La extensión del archivo determina el formato, siendo «.parquet» para Parquet. ¿Hasta aquí nada raro, verdad? Veamos ahora qué implica la parte de «columnar».
Columnar
Al almacenar datos, existen dos enfoques principales: por filas o por columnas. En el método por filas, los valores de una misma fila se almacenan juntos, mientras que en el enfoque columnar, los valores de una misma columna se agrupan. La siguiente imagen ilustra estos dos métodos:
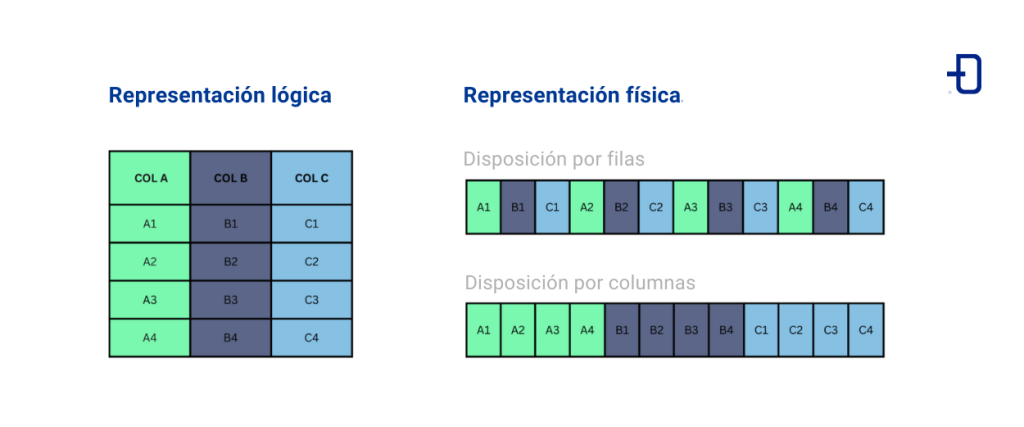
Para comprender las implicaciones de esto, es fundamental entender el funcionamiento interno de un disco. Los datos se almacenan en bloques en el disco, siendo este el mínimo unidad que puede leerse. Es decir, para acceder a un valor específico, es necesario leer el bloque completo. La idea es organizar los datos en disco de manera que se minimice la cantidad de datos innecesarios que se leen. Dependiendo del tipo de lectura, puede ser más eficiente almacenar los datos por filas o por columnas.
En el caso de operaciones analíticas sobre grandes conjuntos de datos, el enfoque columnar resulta más eficaz. Por ejemplo, si tenemos una tabla con millones de filas y deseamos sumar todos los valores de una columna, si los datos están almacenados por filas, se leerán muchos datos innecesarios, ya que un bloque del disco contendrá los valores de las otras columnas. Sin embargo, si la tabla está organizada por columnas, la cantidad de bloques que deben leerse será considerablemente menor.
Otro aspecto a tener en cuenta es el ratio de compresión. Al guardar los datos de manera columnar, tendremos tipos de datos similares juntos y el ratio de compresión será mayor.
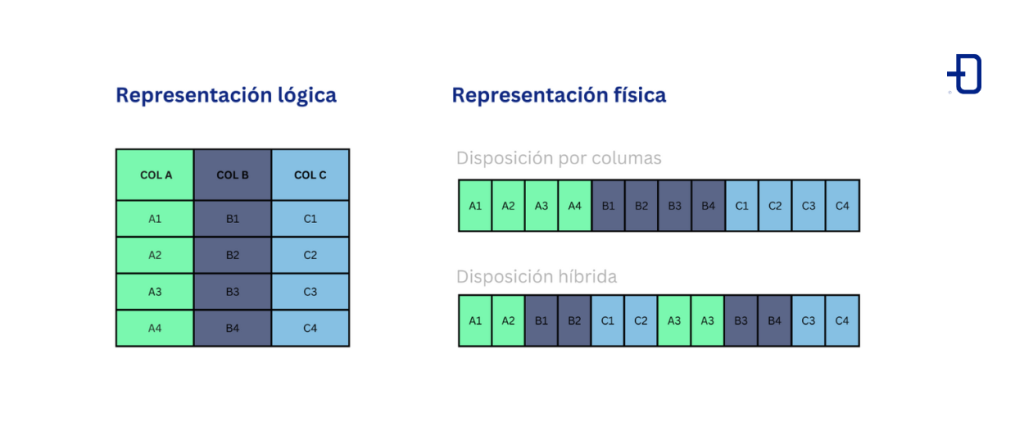
Parquet se define como «columnar» porque guarda los datos por columnas. Sin embargo, es interesante destacar que esto no es completamente cierto, ya que Parquet utiliza un modelo híbrido que le otorga cierta flexibilidad. La idea detrás de este modelo híbrido es dividir la tabla original en conjuntos de filas y luego guardar cada conjunto por columnas, tal y como se muestra en la siguiente imagen:
Esta introducción nos proporciona una visión general para entender las diferencias fundamentales entre Parquet y otros formatos. Sin embargo, ¿cómo se materializan exactamente estas diferencias en la práctica?
Conceptos clave de Apache Parquet
Estructura del archivo
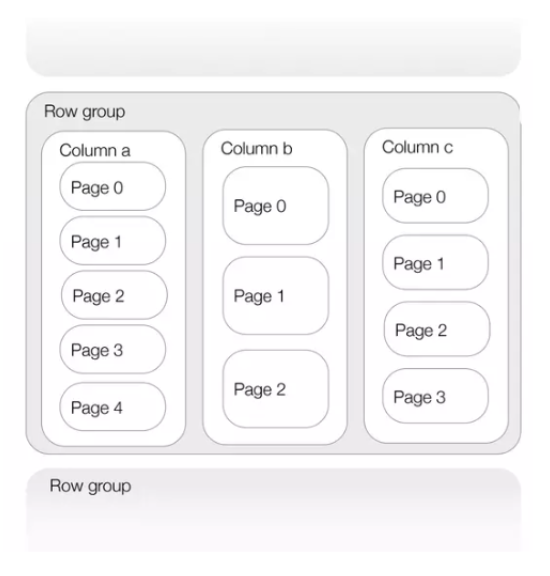
Parquet adopta una estrategia de división de datos en archivos predeterminados de 1GB (aunque este parámetro es configurable), lo que resulta en la generación de múltiples archivos «.parquet». Cada uno de estos archivos está compuesto por grupos de filas (row groups), donde cada grupo de filas se segmenta en sus respectivas columnas, y cada columna se divide en páginas. Estas páginas representan la unidad mínima de información que puede leerse. La siguiente imagen ilustra la estructura típica de un archivo Parquet.
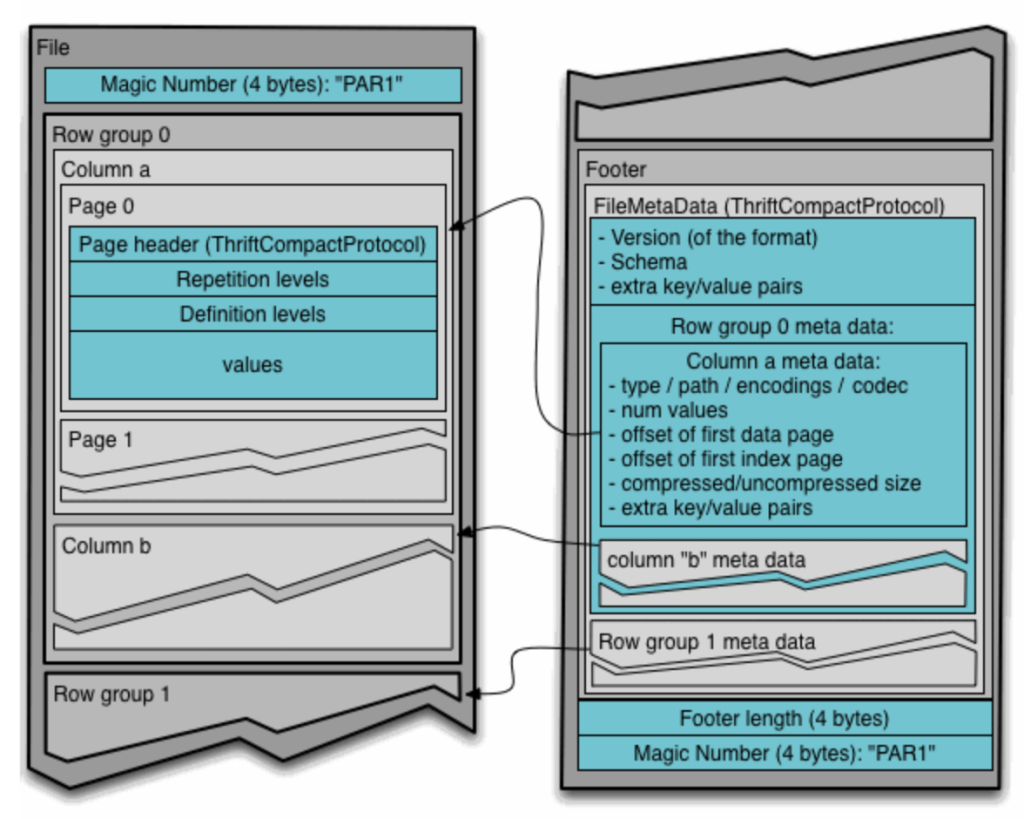
Al final de cada archivo, se añaden tanto los metadatos a nivel general (esquema, algoritmo de encriptación, fecha de creación, entre otros) como los metadatos correspondientes a cada grupo de filas (nombre de cada columna, algoritmo de compresión, etc.). Esta inclusión de metadatos al final de cada archivo permite la escritura del mismo en una sola pasada. A la hora de leerlo, es crucial comenzar por los metadatos para así seleccionar exclusivamente las columnas de interés. La siguiente imagen extraída de la documentación oficial muestra con mayor detalle la estructura de un archivo Parquet.
Tipos de dato
Los tipos de datos primitivos que soporta Parquet son los siguientes:
- BOOLEAN: Booleano de 1 bit.
- INT32: Entero con signo de 32 bits.
- INT64: Entero con signo de 64 bits.
- INT96: Entero con signo de 96 bits.
- FLOAT: Coma flotante IEEE de 32-bits.
- DOUBLE: Coma flotante IEEE 64-bits.
- BYTE_ARRAY: Array de bytes de longitud arbitraria.
- FIXED_LEN_BYTE_ARRAY: Array de bytes de longitud fija.
El enfoque de Parquet es trabajar con el mínimo número de tipos de datos primitivos. Utiliza tipos lógicos para extender estos tipos primitivos, definiendo cómo deben ser interpretados mediante anotaciones. Por ejemplo, un string se representa como un byte_array con la anotación UTF8.
Cuando los datos no están anidados, Parquet representa cada valor de manera secuencial. Sin embargo, en el caso de estructuras anidadas, Parquet se basa en el modelo de Dremel y utiliza niveles de repetición/definición para manejar estas estructuras. Aunque la explicación técnica detallada de este modelo excede el alcance de este post, la idea es tener un modelo para aplanar/desaplanar estas estructuras anidadas. Puedes encontrar más información sobre Dremel y Parquet explicado de manera sencilla en este artículo.
Metadata
Parquet genera metadata en tres niveles: a nivel de archivo, a nivel de columna y a nivel de página. Aquí se puede ver un diagrama de la metadata en los distintos niveles. Esta metadata es esencial para el procesamiento eficiente de datos.
A nivel de archivo, además de información de las columnas, la pieza más importante que se guarda es el esquema de los datos, que describe la estructura de los datos almacenados. A nivel de columna, se guarda información detallada como el tipo de columna y el encoding utilizado, lo que permite una interpretación precisa de los datos. Por último, a nivel de página, además del tipo de página o el número de valores que contiene, se almacena el máximo y mínimo de estos valores. Estos valores máximos y mínimos son especialmente útiles, ya que permiten optimizar las consultas al saltarse ciertas páginas sin necesidad de leerlas completamente.
En conjunto, esta metadata proporciona información esencial para la correcta interpretación y manipulación de los datos almacenados en archivos Parquet.
Codificación
Para representar los datos de manera más compacta dentro de las páginas de datos (data pages), Parquet utiliza tres piezas de información: los niveles de repetición, los niveles de anidación y los propios valores. Las codificaciones admitidas varían según el tipo de dato e incluyen PLAIN, Dictionary Encoding, Run Length / Bit Packing Hybrid (para niveles de repetición/definición y booleanos), Delta Encoding (para enteros), Delta-length byte array (para arrays), Delta Strings (para arrays) y Byte Stream Split (para floats y doubles).
Si bien entrar en detalles sobre cada codificación está más allá del alcance de este post, es importante comprender que Parquet aplica estas codificaciones a nivel de página para optimizar el almacenamiento y la eficiencia de la lectura de datos.
Compresión
Parquet permite comprimir el bloque de datos de cada página. Se admiten varios algoritmos de compresión que cubren diferentes áreas en el espectro de relación compresión/costo de procesamiento. Los algoritmos soportados son: sin compresión, Snappy, Gzip, LZO, BROTLI y ZSTD.
Desventajas de Parquet
Como ocurre con cualquier tecnología, Parquet presenta algunas limitaciones que deben tenerse en cuenta. A pesar de sus numerosas ventajas en términos de rendimiento y eficiencia, hay ciertos aspectos negativos a considerar:
- Escritura lenta: La escritura en archivos Parquet puede ser más lenta en comparación con otros formatos.
- No legible por un humano: A diferencia de los formatos de datos como CSV y JSON, que son legibles para humanos, los archivos Parquet están en un formato binario y no son fácilmente legibles o interpretables sin herramientas especializadas.
- Cambios en el esquema: Uno de los desafíos de Parquet es la gestión de cambios en el esquema de los datos. A diferencia de formatos como CSV, que son flexibles en cuanto a la adición o modificación de columnas, Parquet requiere una planificación cuidadosa al realizar cambios en el esquema.
- Mayor uso de CPU: El proceso de escritura y lectura de archivos Parquet puede requerir un mayor uso de la CPU en comparación con otros formatos, especialmente durante la fase de compresión y descompresión de datos.
Comparación
En este apartado, comparamos los formatos CSV y JSON con Parquet utilizando un conjunto de datos real de Kaggle, del Departamento de Finanzas de la Ciudad de Nueva York, que recopila información sobre multas de estacionamiento emitidas en la ciudad (~10 millones por año). El conjunto de datos abarca los años 2015, 2016 y 2017, con 43 columnas y aproximadamente 33 millones de filas.
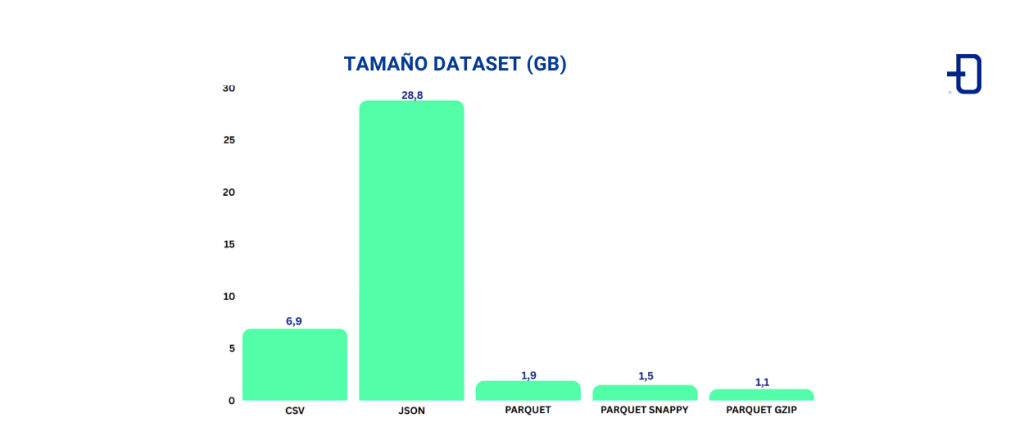
Primero, comparamos el tamaño del dataset en diferentes formatos. La tabla a continuación muestra el tamaño en GB del dataset en CSV, JSON, Parquet (sin compresión), Parquet con Snappy y Parquet con Gzip. Se observa que en comparación con Parquet, el tamaño en CSV es aproximadamente 3 veces mayor, y en JSON es aproximadamente 15 veces mayor. La diferencia de tamaño entre las diferentes codificaciones de Parquet no es tan significativa (esto dependerá mucho de los datos y el ratio de compresión), pero se puede notar una reducción de aproximadamente 0.8x a 0.6x. Este ejemplo destaca la eficiencia de Parquet en el almacenamiento de datos en disco.
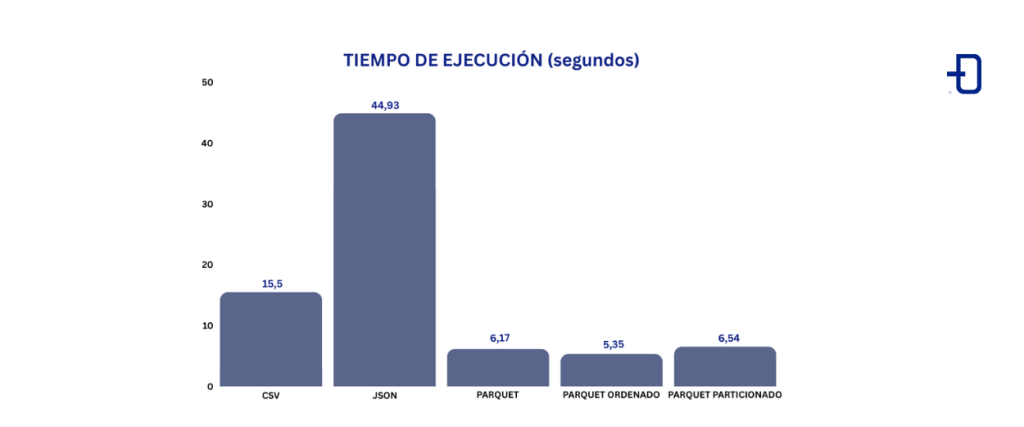
Segundo, evaluamos el tiempo de ejecución de una consulta sobre el conjunto de datos. Supongamos que queremos saber cuántos vehículos fabricados entre 2000 y 2010 han recibido una multa. Esto se traduce en contar los registros de la columna «Vehicle Year» entre 2000 y 2010, que suman un total de 11,550,949. Este tipo de consulta, analítica en naturaleza, involucra un pequeño número de columnas y es para lo que Parquet está diseñado. Utilizamos Spark como motor de búsqueda. La imagen a continuación muestra los tiempos de ejecución en segundos de la consulta utilizando CSV, JSON, Parquet, Parquet (con la columna Vehicle Year ordenada) y Parquet (particionado por Vehicle Year).
En comparación con Parquet, la consulta en CSV tarda aproximadamente 2.5 veces más, mientras que en JSON es aproximadamente 7.28 veces más lenta. Los tiempos de ejecución en las diferentes representaciones de Parquet son más similares, aunque existen algunas diferencias.
Se puede observar que la consulta en Parquet es considerablemente más rápida, gracias a factores como el tamaño reducido del conjunto de datos, la lectura selectiva de columnas y la capacidad para saltar ciertas páginas utilizando la metadata (por ello, Parquet ordenado es el más veloz, ya que al estar ordenado la metadata de max/min de cada página, se puede utilizar de manera más efectiva).
Además de ocupar menos espacio en disco, Parquet ofrece tiempos de ejecución considerablemente más rápidos para consultas analíticas.
Conclusión
En resumen, hemos desglosado el formato de archivos Parquet y hemos descubierto cómo puede marcar la diferencia en el manejo de grandes volúmenes de datos. Además, se ha comparado Parquet con otros formatos mediante un ejemplo real. El objetivo final del artículo es que la próxima vez que estés pensando en cómo almacenar tus datos, consideres Parquet como una alternativa que puede hacerte la vida mucho más fácil y tu análisis de datos mucho más eficiente. ¡Hay vida fuera del CSV!
Si este artículo te ha parecido interesante, te animamos a visitar la categoría Data Engineering para ver otros posts similares a este y a compartirlo en redes. ¡Hasta pronto!
