
When dealing with significant amounts of data, the way you store it can make the difference between success and failure. In this post, we’re going to take a look at a file format that may not be the most popular, but is definitely worth considering – Parquet. We’ll explain what problems it solves and how it works, without sparing us the key technical terms. Beyond that, though, the goal is to convey the importance of choosing the right file format for each use case.
Apache Parquet is defined as a columnar file format. It was created in 2013 in an effort between Twitter and Cloudera engineers to address the limitations they were encountering when dealing with large amounts of bulk data. In 2015, Apache Foundation announced Parquet as one of its top-level projects.
The definition of Parquet introduces two concepts: ‘file format’ and ‘columnar’. What do they mean exactly?
File format
A file format is nothing more than a specification that defines the structure and organization of the information contained in a file. These formats determine how data is stored, what type of data it can contain and how it can be accessed and manipulated. Formats vary according to the type of data and purpose. For example, there are TXT or DOCX for text, JPEG or PNG for images, MP3 or WAV for audio, and MP4 or AVI for video.
On the data side, the most common formats are CSV, JSON and XML, although there are lesser-known formats such as Avro, Protocol Buffers and, of course, Parquet. The file extension determines the format, being “.parquet” for Parquet. So far nothing unusual, right? Now let’s see what the “columnar” part implies.
Columnar
When storing data, there are two main approaches: by rows or by columns. In the row method, values in the same row are stored together, while in the columnar approach, values in the same column are grouped together. The following image illustrates these two methods:
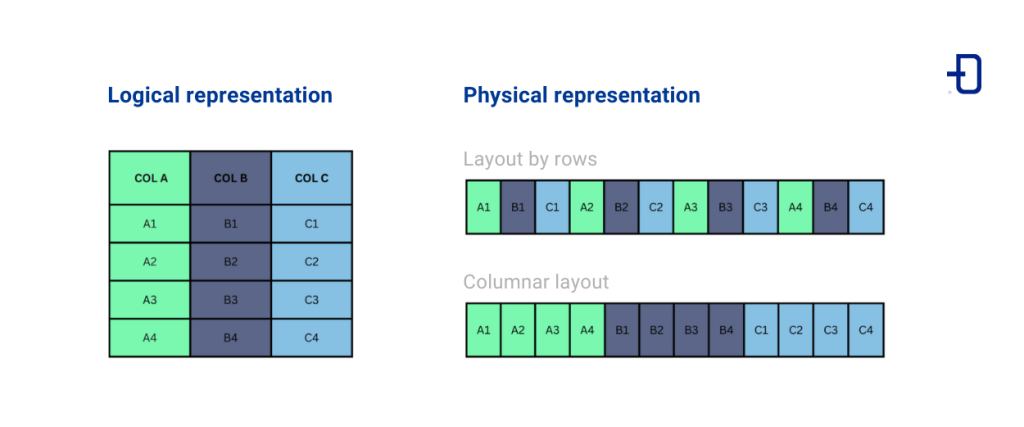
To grasp the implications of this, it is essential to understand the inner workings of a disk. Data is stored in blocks on the disk, being this the minimum unit that can be read. That is, to access a specific value, it is necessary to read the entire block. The idea is to organize the data on disk in such a way as to minimize the amount of unnecessary data read. Depending on the type of read, it may be more efficient to store data by rows or by columns.
For analytical operations on large datasets, the columnar approach is more efficient. For example, if we have a table with millions of rows and we want to sum up all the values in a column, if the data is stored by rows, a lot of unnecessary data will be read, since one block of the disk will contain the values of the other columns. However, if the table is organized by columns, the number of blocks to be read will be considerably less.
Other aspect to take into account is the compression ratio. By saving data in columnar form, we will have similar data types together and the compression ratio will be higher.
Parquet is defined as “columnar” because it stores data by columns. However, it is interesting to note that this is not completely true, as Parquet uses a hybrid model that gives it some flexibility. The idea behind this hybrid model is to split the original table into sets of rows and then store each set by columns, as shown in the following image:
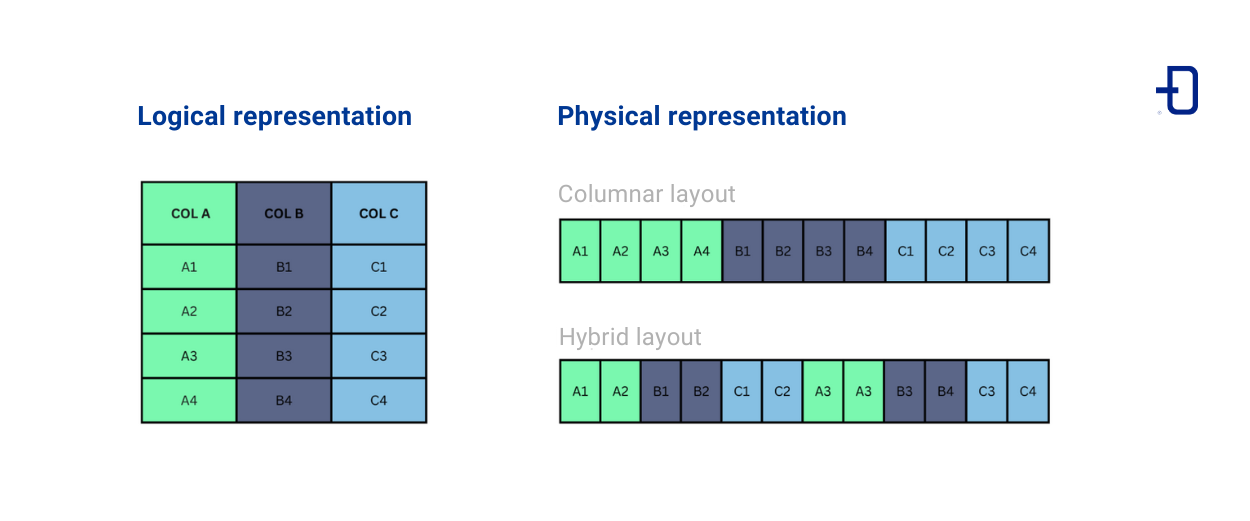
This introduction provides an overview to understand the fundamental differences between Parquet and other formats. However, how exactly do these differences materialize in practice?
Apache Parquet Key Concepts
File structure
Parquet adopts a strategy of splitting data into default 1GB files (although this parameter is configurable), resulting in the generation of multiple “.parquet” files. Each of these files is composed of row groups, where each row group is segmented into its respective columns, and each column is divided into pages. These pages represent the minimum unit of information that can be read. The following image illustrates the typical structure of a Parquet file.
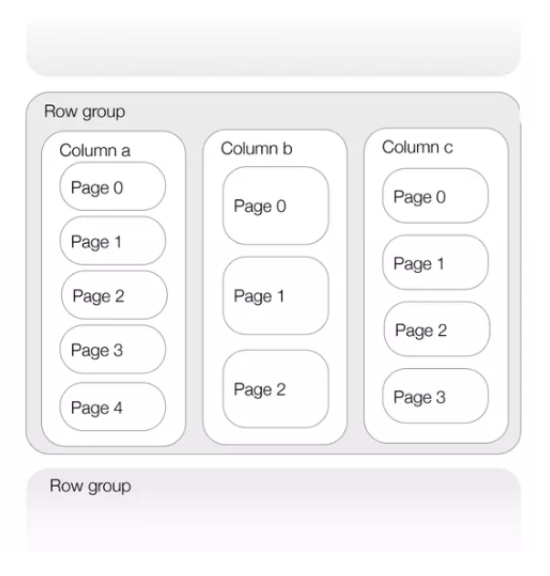
At the end of each file, both general metadata (schema, encryption algorithm, creation date, etc.) and metadata corresponding to each group of rows (name of each column, compression algorithm, etc.) are added. This inclusion of metadata at the end of each file allows it to be written in a single pass. When reading it, it is crucial to start with the metadata in order to select only the columns of interest. The following image extracted from the official documentation shows in more detail the structure of a Parquet file.
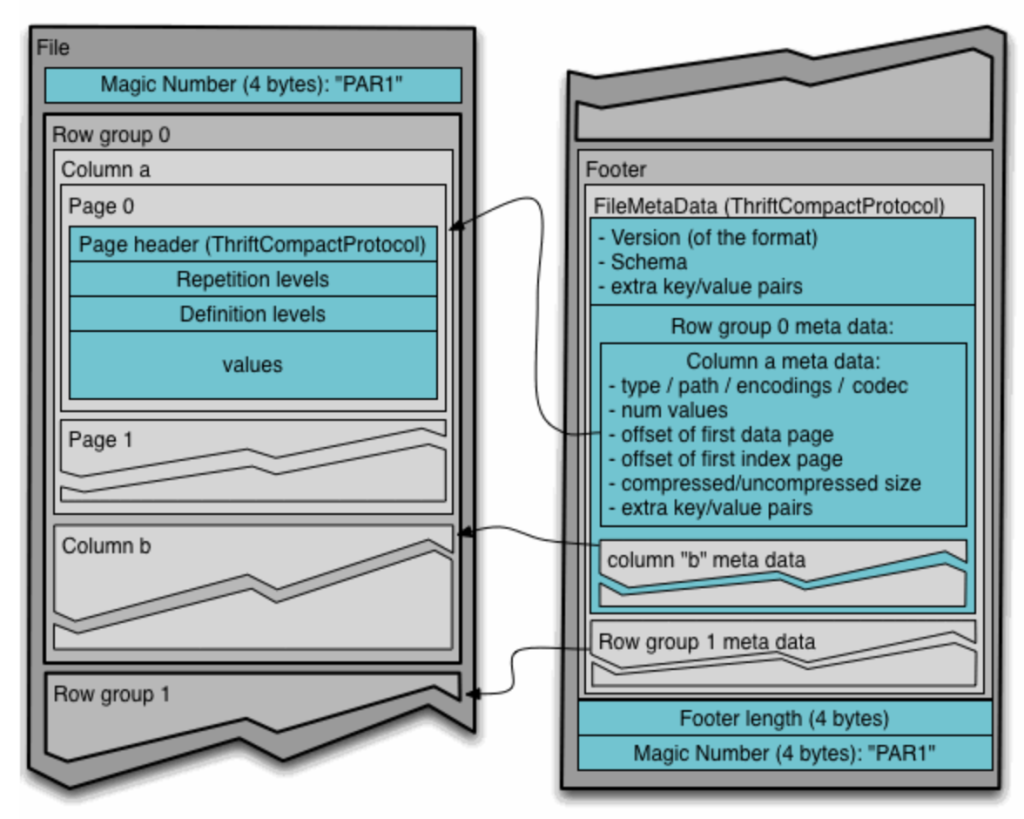
Data types
The primitive data types supported by Parquet are the following:
- BOOLEAN: 1-bit Boolean.
- INT32: 32-bit signed integer.
- INT64: 64-bit signed integer.
- INT96: 96-bit signed integer.
- FLOAT: IEEE 32-bit floating point.
- DOUBLE: IEEE 64-bit floating point.
- BYTE_ARRAY: Array of bytes of arbitrary length.
- FIXED_LEN_BYTE_ARRAY: Fixed-length byte array.
The approach of Parquet is to work with the minimum number of primitive data types. It uses logical types to extend these primitive types, defining how they should be interpreted by annotations. For example, a string is represented as a byte_array with the UTF8 annotation.
When data is not nested, Parquet represents each value sequentially. However, in the case of nested structures, Parquet is based on the Dremel model and uses levels of repetition/definition to handle these structures. Although a detailed technical explanation of this model is beyond the scope of this post, the idea is to have a model for flattening/deflattening these nested structures. You can find more information about Dremel and Parquet explained in a simple way in this post.
Metadata
Parquet generates metadata at three levels: file level, column level and page level. Here is a diagram of metadata at the different levels. This metadata is essential for efficient data processing.
At the file level, in addition to column information, the most important piece of information stored is the data schema, which describes the structure of the stored data. At the column level, detailed information such as the type of column and the encoding used is stored, allowing an accurate interpretation of the data. Finally, at the page level, in addition to the type of page or the number of values it contains, the maximum and minimum of these values is stored. These maximum and minimum values are particularly useful, as they allow to optimize queries by skipping certain pages without having to read them completely.
Overall, this metadata provides essential information for the correct interpretation and manipulation of data stored in Parquet files.
Coding
To represent data more compactly within data pages, Parquet uses three pieces of information: repetition levels, nesting levels and the values themselves. The supported encodings vary by data type and include PLAIN, Dictionary Encoding, Run Length / Bit Packing Hybrid (for repeating/defining levels and Booleans), Delta Encoding (for integers), Delta-length byte array (for arrays), Delta Strings (for arrays) and Byte Stream Split (for floats and doubles).
While going into detail about each encoding is beyond the scope of this post, it is important to understand that Parquet applies these encodings at the page level to optimize storage and data reading efficiency.
Compression
Parquet allows to compress the data block of each page. Several compression algorithms are supported covering different areas in the compression/processing cost ratio spectrum. The supported algorithms are: uncompressed, Snappy, Gzip, LZO, BROTLI and ZSTD.
Disadvantages of Parquet
As with any technology, Parquet has some limitations that must be taken into account. Despite its many advantages in terms of performance and efficiency, there are some downsides to consider:
- Slow writing: Writing to Parquet files can be slower compared to other formats.
- Not human readable: Unlike data formats such as CSV and JSON, which are human readable, Parquet files are in a binary format and are not easily readable or interpretable without specialized tools.
- Schema changes: One of the challenges of Parquet is managing changes to the schema of the data. Unlike formats such as CSV, which are flexible in terms of adding or modifying columns, Parquet requires careful planning when making schema changes.
- Higher CPU usage: The process of writing and reading Parquet files may require higher CPU usage compared to other formats, especially during the data compression and decompression phase.
Comparison
In this section, we compare CSV and JSON formats with Parquet using a real dataset from Kaggle, from the New York City Department of Finance, which collects information on parking tickets issued in the city (~10 million per year). The dataset spans the years 2015, 2016, and 2017, with 43 columns and approximately 33 million rows.
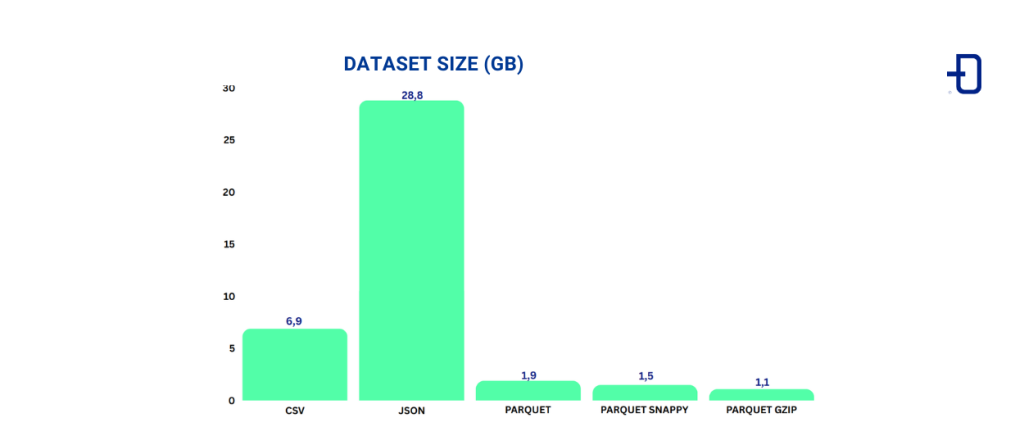
First, we compare the size of the dataset in different formats. The table below shows the size in GB of the dataset in CSV, JSON, Parquet (without compression), Parquet with Snappy and Parquet with Gzip. It is observed that compared to Parquet, the size in CSV is about 3 times larger, and in JSON it is about 15 times larger. The size difference between the different Parquet encodings is not that significant (this will depend a lot on the data and the compression ratio), but a reduction of about 0.8x to 0.6x can be noticed. This example highlights the efficiency of Parquet in storing data on disk.
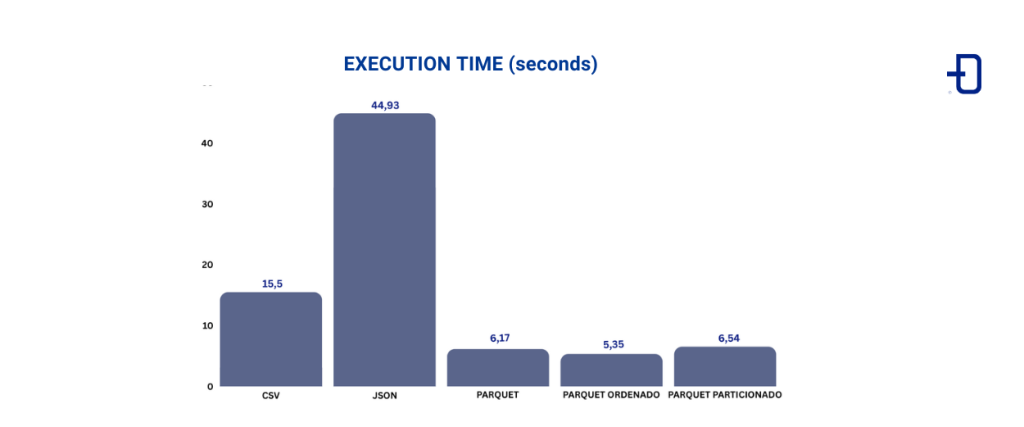
Second, we evaluate the execution time of a query on the dataset. Suppose we want to know how many vehicles manufactured between 2000 and 2010 have received a ticket. This translates to counting the records in the “Vehicle Year” column between 2000 and 2010, which total 11,550,949. This type of query, analytical in nature, involves a small number of columns and is what Parquet is designed for. We use Spark as the search engine. The image below shows the execution times in seconds of the query using CSV, JSON, Parquet, Parquet (with the Vehicle Year column sorted) and Parquet (partitioned by Vehicle Year).
Compared to Parquet, the query in CSV takes approximately 2.5 times longer, while in JSON it is approximately 7.28 times slower. The execution times in the different Parquet representations are more similar, although there are some differences.
It can be seen that the Parquet query is considerably faster, thanks to factors such as the reduced dataset size, selective column reading, and the ability to skip certain pages using the metadata (hence, sorted Parquet is the fastest, since the max/min metadata for each page is sorted, it can be used more effectively).
Conclusion
In summary, we have analyzed the Parquet file format and discovered how it can make a difference in handling large volumes of data. In addition, Parquet has been compared to other formats using a real-world example. The final goal of the article is that the next time you are thinking about how to store your data, consider Parquet as an alternative that can make your life much easier and your data analysis much more efficient. There is life outside of CSV!
If you found this article interesting, we encourage you to visit the Data Engineering category to see other posts similar to this one and to share it on social networks. See you soon!
