
Imagínese ser un data scientist que trabaja para una empresa que ha decidido unificar las bases de datos de dos de sus departamentos en una sola. No existe ningún índice común entre ambas fuentes y la tarea consiste en “deduplicar” los registros o, dicho de otra manera, en establecer qué registro de una tabla se corresponde a la misma entidad de otro registro de la otra tabla para consolidarlos en uno solo:
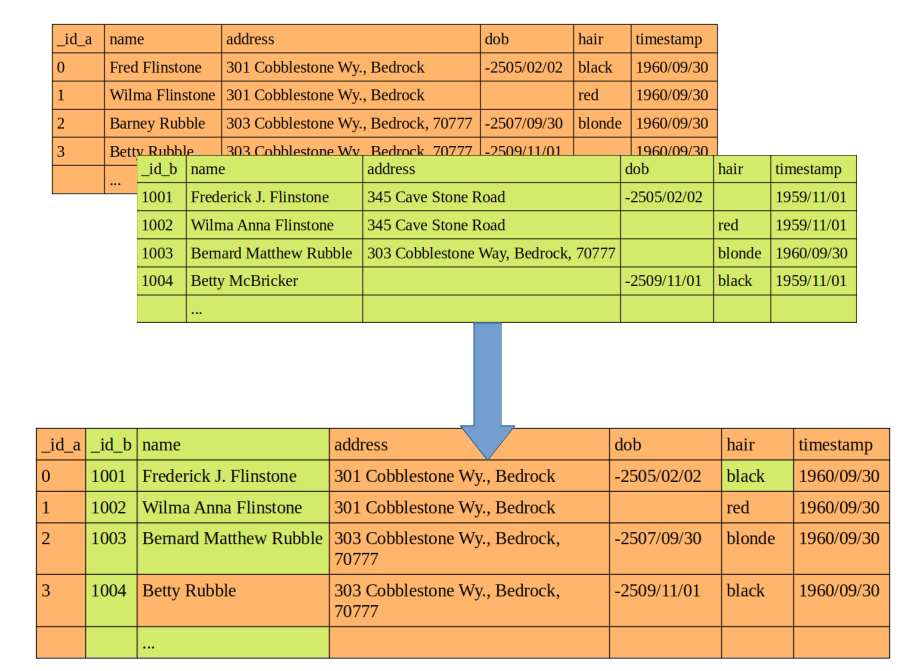
Este proceso puede recibir muchos nombres. En estadística se conoce como vinculación de datos (en inglés: “record linkage”) y en informática como cotejo de datos o resolución de entidades. Una lista no exhaustiva de conceptos más o menos sinónimos en distintos contextos incluye “procesos de purga”, “resolución de correferencias”, “coincidencias difusas” o “integración de datos”. En todos los casos responde al proceso de encontrar registros correspondientes a la misma entidad en distintas fuentes de datos, o en la misma.
La necesidad de técnicas específicas para la vinculación de datos responde siempre a la ausencia de identificadores comunes y fiables entre fuentes de datos. Es en estos casos donde la vinculación de datos resulta especialmente útil, sea cual sea la causa por la que falten los identificadores. Por ejemplo, si desean integrarse datos censales del siglo XIX con fines de investigación histórica, muy posiblemente no se dispondrá de ningún identificador común para los individuos.
En entornos desfavorecidos también pueden faltar identificadores oficiales que permitan mantener una sola historia clínica para todos los individuos que acuden a hospitales de una misma zona. Casos más habituales de uso en empresas son procesos de Master Data Management para crear golden records (típicamente de clientes) y los procesos de vinculación para la detección de fraudes en el sector financiero.
Enfoques en vinculación de datos
Existen dos enfoques clásicos para hacer vinculación de datos:
La vinculación de datos basada en reglas es el enfoque más sencillo de vinculación. Aquí se incluyen todos los sistemas de reglas que se hayan decidido con antelación que son el método adecuado para vincular registros. Por ejemplo, a falta de un identificador común, se puede decidir vincular registros siempre que la concatenación de tres campos sea la misma.
Otro ejemplo sería que, a partir de una cantidad de posibles identificadores comunes, dos registros se vinculan si hay una proporción de identificadores comunes mayor o igual que un umbral X predefinido. Otra aproximación sería otorgar discrecionalmente un peso a los campos y decidir que son la misma entidad si su grado de vinculación supera cierto umbral.
Si, en lugar de dar pesos a los campos de manera determinista, estos pesos se computan con un modelo que tenga en cuenta las capacidades de los identificadores para determinar si hay o no vinculación, estamos ante un tipo de vinculación probabilística. De la manera más sencilla, y definido cierto umbral, el usuario asume que las parejas de registros con una probabilidad por encima de éste se consideran vinculadas y las que quedan por debajo, no lo están. Otra opción es definir dos umbrales, entre cuyos valores se sitúan las parejas de registros que son “posibles vinculaciones”.
Fellegi y Sunter definieron un primer algoritmo específico para vincular registros. Funciona asignando ponderaciones específicas (u y m) a cada identificador donde:
- u refleja la probabilidad de que el valor de un identificador coincida en un par de registros no vinculados;
- m sería la probabilidad de que el valor del identificador coincida para un par de registros vinculados.
Se pueden determinar u y m para cada identificador con un análisis previo de los datos o bien corriendo varias iteraciones del algoritmo. Luego, estos pesos m y u se usan junto con la probabilidad global de vinculación para computar los pesos que se usarán para calcular las probabilidades. Para una explicación más a fondo, la documentación de Splink sobre el modelo Fellegi-Sunter es un buen recurso.
El método Fellegi-Sunter todavía se usa ampliamente y se ha ido extendiendo para lidiar con alguna de sus debilidades (datos faltantes, relaciones complejas entre campos, etc.).
Sin perjuicio de estas mejoras, algunos investigadores consideran que este algoritmo es equivalente a un clasificador naïve Bayes (Wilson, 2011). Se ha observado, asimismo, que algoritmos de clasificación genéricos usados comúnmente en machine learning como la regresión logística o las máquinas de soporte vectorial pueden igualar o llegar a superar sus resultados (Mason, 2018; Aiken et al. 2019).
Desafíos de la vinculación de datos
En general, los enfoques clásicos de vinculación son sencillos, fáciles de explicar y funcionan bien con conjuntos de datos pequeños. Independientemente de si sus resultados son mejores o peores que el de los algoritmos de machine learning, su debilidad más destacable es la escasa flexibilidad para adaptarse a cambios en los datos. Otros desafíos, en cierto modo comunes con cualquier algoritmo que pretenda usarse para la vinculación de datos, son:
- Lidiar con las variaciones y errores en los valores específicos de los identificadores. Los campos de tipo cadena de texto (string) son muy susceptibles de contener errores tipográficos o variaciones, pequeñas o grandes, del mismo valor que dificultan, a priori, su vinculación efectiva. Junto con un preprocesado de los campos de texto, algoritmos de comparación de cadenas de texto o de distancia entre texto tokenizado, pueden ser útiles para computar grados de similitud entre campos de este tipo en sus posibles emparejamientos. Algoritmos fonéticos como Soundex y Metaphone también pueden ser de utilidad si son cadenas de texto en inglés.
- Temas de privacidad. Cuando por temas de legislación o política corporativa no esté permitido compartir datos sensibles, algoritmos como Bloom pueden encriptar los campos sensibles de tipo string conservando a la vez la similitud entre pares (Chi et al., 2017).
- La falta de valores puede dificultar más el proceso de vinculación que un valor erróneo o borroso. Cuando los campos son numéricos, puede ser recomendable imputar valores antes de intentar vincular las bases de datos. En Chi et al., 2017, por ejemplo, se usa KNN-neighbours para imputar valores faltantes.
- Manejar temas de escala. La falta de identificadores comunes hace que el espacio de comparaciones pueda crecer de forma cuadrática. Para limitar este crecimiento, suelen bloquearse ciertos campos para evitar explorar vinculaciones fuera de éstos. Por ejemplo, si en dos bases de datos de proveedores se dispone de una variable fiable como el código CNAE (Clasificación Nacional de Actividades Económicas), bloquearla para evitar explorar vinculaciones donde este código sea distinto limita el número de combinaciones posibles.
Aproximaciones con Machine Learning
Los enfoques clásicos de vinculación de datos pueden ser muy útiles cuando el caso de uso es sencillo y estático. Por ejemplo, cuando tiene que hacerse una sola vez con dos tablas estáticas de pequeñas dimensiones, puede ser suficiente diseñar unas cuantas reglas que nos permitan asociar pares de registros. Cuando las tablas tienen millones de filas, están en continuo cambio, existen relaciones complejas entre los campos o la calidad del dato es mala, los métodos de machine learning empiezan a ganar interés.
En primera instancia, el acervo de algoritmos de aprendizaje automático que se podrán utilizar para vincular registros dependerá de si se dispone o no de un conjunto de datos etiquetados para entrenar.
- Si se dispone de él, se puede usar cualquier algoritmo de aprendizaje supervisado con un objetivo de clasificación, desde regresiones logísticas a implementaciones de Extreme Gradient Boosting. Métodos basados en redes neuronales también pueden resultar especialmente útiles para casos en los que existan relaciones no lineales.
- Si no se dispone de conjunto etiquetado, las opciones se restringen a algoritmos de aprendizaje no supervisado, en concreto de clustering. Los algoritmos de clustering basados en grafos pueden resultar especialmente útiles si existen relaciones complejas o dependencias entre entidades.
Sea cual sea el algoritmo escogido, aplicarlo en casos de vinculación de datos puede requerir de una preparación ligeramente distinta de los datos. En primer lugar, se deberán tomar decisiones para lidiar con los desafíos expuestos en el punto anterior.
En el caso de estar usando algoritmos de clasificación, generar el conjunto de entrenamiento requiere hacer una unión cruzada de registros (o acaso una unión bloqueando ciertos campos). Esto puede provocar un desequilibrio de clases que puede intentar solucionarse reduciendo el número de observaciones de la clase mayoritaria (pares no vinculados) y dando más peso en el entrenamiento a las observaciones de la clase minoritaria (pares vinculados).
Antes de entrenar, hay que identificar el conjunto de campos comunes entre fuentes e iterar sobre él para computar el grado de similitud entre pares de registros de cada campo de acuerdo con un criterio previamente establecido, según el caso de uso. Es sobre este conjunto de similitudes que se entrena el modelo.
En cuanto a la evaluación en modelos de clasificación, en muchos casos, debido a los problemas de contaminación de datos que pueden generarse, cobra más sentido hacerla en base a medidas de precission, recall o F1-score que hacerlo por accuracy.
Por otra parte, si se va a entrenar un modelo de clustering es importante hacerlo de forma correcta. La mejor forma de realizarlo es generar una unión cruzada de registros (como en clasificación) calculando la similitud entre dimensiones y luego correr el modelo para agrupar los pares en 2 clusters: match vs no match.
Por lo demás, el entrenamiento, el despliegue y la monitorización del modelo no deberían suponer diferencias, comparados con casos de uso habituales de machine learning.
Probabilidades de vinculación
Hay dos cuestiones clave que se tienen que considerar antes de intentar resolver vinculaciones:
- Hay que saber si puede haber duplicados en las tablas mismas, antes de vincular. No es lo mismo que, siendo así, un registro en una tabla se corresponda muy probablemente con otros 2 en la otra tabla, que, pasando lo mismo, sepamos de antemano que no puede haber duplicados.
- El grado de vinculación entre tablas casi en ningún caso será del 100%. Puede haber registros en una y otra tabla que no tengan su correspondencia en su contraparte.
Teniendo esto en consideración, tras entrenar un modelo de clasificación, éste se encuentra listo para comprobar si cada combinación de registros es o no una vinculación real. La mayoría de librerías tienen un método predict_proba() o análogo que devuelve las predicciones en forma de probabilidad. Según el caso de uso, puede que tenga sentido usar estas probabilidades ordenadas antes que el output en sentido binario.
En el entrenamiento de un algoritmo de clustering se tiene que asumir que, aunque solo sea con una probabilidad muy alta, cada clúster se corresponde con una entidad. Luego, algoritmos de soft clustering como el modelo de mezcla gaussiana (Gaussian mixture model) pueden usarse para computar la probabilidad de que un registro pertenezca a cada clúster.
Dependiendo de las especificaciones del caso de uso, tendremos que decidir cómo solucionar casos en que las probabilidades de vinculación sean elevadas para varias entidades a la vez. Si prevemos que pueden haber duplicados, vinculamos todas las que superen cierto umbral de probabilidad; si no, quizá tenemos que tomar la que tiene una probabilidad más elevada. Y, casi con total seguridad, vamos a tener registros que no podremos vincular, porque en la mayoría de los casos vamos a prever que el grado de vinculación no es perfecto.
Conclusión
La vinculación de datos no es un problema nuevo. Solucionarlo con aprendizaje automático tampoco es muy novedoso, aunque sí más reciente en el tiempo que los enfoques clásicos, ya sea el basado en reglas o el probabilístico. En este post, se ha analizado a muy alto nivel la problemática de record linkage y los desafíos que implica. Por otro lado, se han repasado los enfoques de machine learning que puede tener sentido tomar para afrontar el problema y las particularidades que conlleva en las etapas de preparación del dato, evaluación e interpretación de las probabilidades.
Bibliografía
Mason, L. G. (2018). A comparison of record linkage techniques. Quarterly Census of Wages and Employment (QCEW): Washington, DC, USA, 2438-2447.
Aiken, V. C. F., Dórea, J. R. R., Acedo, J. S., de Sousa, F. G., Dias, F. G., & de Magalhães Rosa, G. J. (2019). Record linkage for farm-level data analytics: Comparison of deterministic, stochastic and machine learning methods. Computers and Electronics in Agriculture, 163, 104857.
Wilson, D. R. (2011, July). Beyond probabilistic record linkage: Using neural networks and complex features to improve genealogical record linkage. In The 2011 international joint conference on neural networks (pp. 9-14). IEEE.
Chi, Y., Hong, J., Jurek, A., Liu, W., & O’Reilly, D. (2017). Privacy preserving record linkage in the presence of missing values. Information Systems, 71, 199-210.
¡Esto es todo! Si este post te ha parecido interesante, te animamos a visitar la categoría Data Analytics para ver todos los posts relacionados y a compartirlo en redes. ¡Hasta pronto!
