
En el Tutorial DataHub I analizamos la arquitectura de esta plataforma. En este post, vamos a ver una guía de cómo desplegar DataHub y empezar a trabajar con esta herramienta.
DataHub se puede desplegar de dos formas: mediante Helm o con imágenes de Docker. El despliegue está muy orientado a trabajar con contenedores. La principal razón es que, como vimos en el artículo anterior, DataHub depende de muchos servicios que se interconectan entre sí. Por lo tanto, los desarrolladores nos ahorran el esfuerzo de configurar esta interdependencia mediante Docker Compose y Helm.
Despliegue de DataHub con Docker
Para hacer el despliegue, necesitamos tener instalados Docker y Docker Compose. La manera más sencilla de levantar DataHub es mediante las imágenes de Docker. Podemos desplegar fácilmente todas estas imágenes de la siguiente forma:
Ojo: Desde la documentación nos advierten que no debemos usar las imágenes etiquetadas como latest ni debug. Hay que utilizar las marcadas como head para obtener la última versión. Esto se debe, principalmente, a que el proyecto está configurado con un sistema de despliegue continuo que actualiza las imágenes en cada commit.
- acryldata/datahub-ingestion
- acryldata/datahub-gms
- acryldata/datahub-frontend-react
- acryldata/datahub-mae-consumer
- acryldata/datahub-mce-consumer
- acryldata/datahub-upgrade
- acryldata/datahub-kafka-setup
- acryldata/datahub-elasticsearch-setup
- acryldata/datahub-mysql-setup
- acryldata/datahub-postgres-setup
- acryldata/datahub-actions (deprecada)
A lo largo de esta serie utilizaremos la siguiente configuración:
- Ubuntu 22.04
- Python 3.11.9
- Docker 27.0.3
- Docker Compose 2.20.3
- Helm 3.15.3
Lo primero que vamos a hacer es crear un entorno virtual de Python en el que trabajaremos. En mi caso, se llamará datahub-test. Comenzamos.
Instalamos los paquetes de Python de DataHub:
pip install --upgrade pip wheel setuptools
pip install --upgrade acryl-datahubLanzamos el comando clave que nos permitirá descargar todas las imágenes:
datahub docker quickstartLo que internamente está haciendo este comando es crear una carpeta en nuestra home con el siguiente contenido:
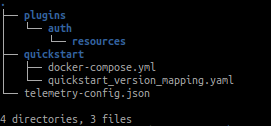
En el directorio ~/.datahub/quickstart podemos encontrar un docker-compose.yml que será el que se ejecute cuando se lance este comando.
Una vez haya terminado este comando, veremos que se exponen todos los servicios y, entre ellos, se encuentra el llamado datahub-datahub-frontend-react-1, que expone el puerto 9002.
Para acceder a la web, podremos hacerlo a través de localhost:9002 e ingresar las credenciales: Usuario: datahub; contraseña: datahub.

¡Enhorabuena! Hemos conseguido levantar por primera vez DataHub. A continuación, ingestaremos unos datos de ejemplo y exploraremos un poco más las opciones de despliegue.
datahub docker ingest-sample-dataAhora podemos ver los siguientes datos ingestados.
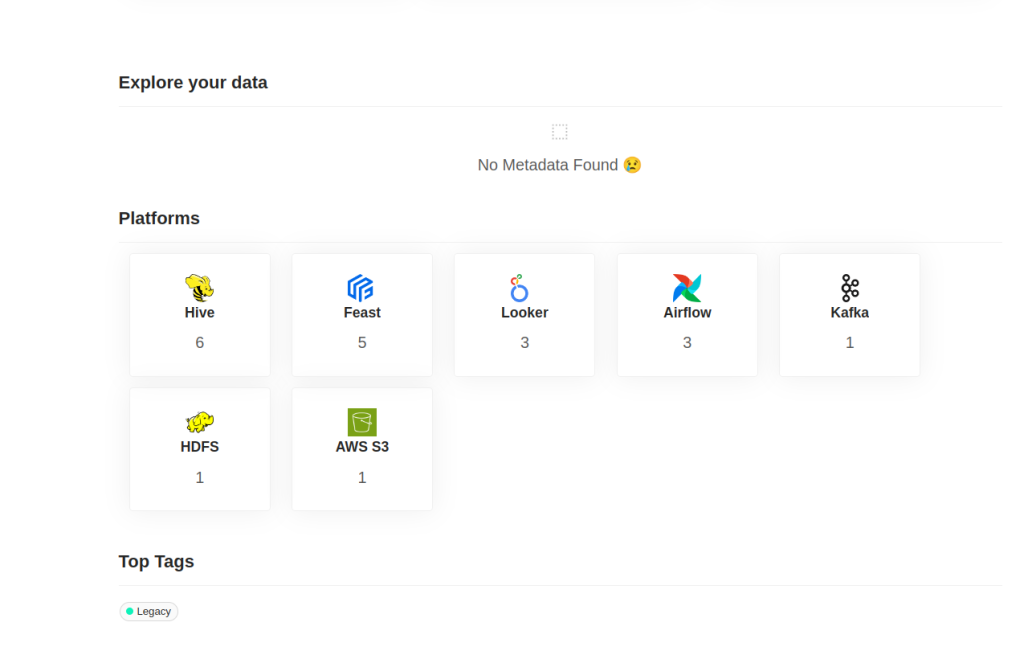
Existen varios comandos sencillos que nos permiten gestionar la plataforma, todos ellos están bajo el de datahub. El siguiente comando nos permite eliminar y limpiar el estado de la misma:
datahub docker nukeEn ocasiones, queremos guardar el estado de la plataforma y, para ello, tenemos el siguiente comando:
datahub docker quickstart --backupEsto generará un fichero normalmente en la ruta ~/.datahub/quickstart/backup.sql
Al final, este backup es un dump de la base de datos mysql donde existe una tabla que persiste todos los datos. La tabla es metadata_aspect_v2, es una tabla única que podremos restaurar en cualquier momento.
Para restaurar el estado utilizamos el siguiente comando:
datahub docker quickstart --restore --restore-file <<my_backup_file.sql>>Despliegue de DataHub en entornos productivos
El despliegue que hemos visto, quickstart, es muy cómodo, pero no es recomendable para despliegues productivos. Está orientado a realizarse en una sola máquina, desplegando en ella todos los servicios transversales en los que se apoya DataHub.
Para este despliegue, se recomienda que el cluster de DataHub tenga al menos 7GB de RAM libres.
DataHub, como hemos visto, se divide en cuatro componentes: dos opcionales y dos requeridos. GMS y Frontend son componentes requeridos, mientras que MAE Consumer y MCE Consumer son obligatorios. Todos ellos se desplegarán como subcharts dentro del chart principal de Helm. En este enlace encontramos el github de Helm de DataHub.
Para nuestra demo, levantaremos un cluster de Kubernetes con Minikube. Si no conoces Minikube te recomiendo revisar nuestro post Qué es Minikube y cómo funciona.
Lo primero que debemos hacer es crear una serie de secrets en el cluster de kubernetes para poder desplegar todos los servicios.
kubectl create secret generic mysql-secrets --from-literal=mysql-root-password=datahub
kubectl create secret generic neo4j-secrets --from-literal=neo4j-password=datahubPara desplegar con Helm, lo más sencillo es añadir el repositorio a nuestro Helm. Sin embargo, también podemos hacerlo manualmente a través del repositorio de GitHub. En DataHub Helm Charts se puede acceder a la documentación.
Una vez instalado el repositorio, debemos levantar una serie de servicios que, básicamente, son servicios de backend: Kafka, Mysql, Zookeeper.
helm install prerequisites datahub/datahub-prerequisitesUna vez levantados, queda instalar el servicio principal de DataHub.
helm install datahub datahub/datahubTras instalarlo, deberemos ver los servicios frontend, gms, mae y mce dentro del cluster.
Para poder consumir el servicio de frontend es necesario realizar el port-forwarding.
kubectl port-forward <datahub-frontend pod name> 9002:9002Todos los servicios pueden instalarse por separado, pero entramos en un terreno más complicado, ya que debemos editar los ficheros YAML de Helm. Sin embargo, esto es muy recomendable para reutilizar ciertos servicios transversales dentro de nuestra organización, como por ejemplo, servicios de MySQL dentro de nuestra nube. Todo ello se puede configurar en forma de propiedades dentro del chart.
¡Enhorabuena! Ahora podemos empezar a trabajar de manera operativa con DataHub.
Conclusión
En este post hemos cubierto aspectos básicos del despliegue de DataHub, tanto con Docker como con Helm. Este tipo de despliegue está enfocado a entornos de desarrollo o preproductivos, para un enfoque más robusto y escalable es recomendable ver la documentación de DataHub.
Sin embargo, este entorno será ideal para los siguientes posts de esta serie, en los que trabajaremos con nuestra plataforma ya levantada. ¡Ya estamos listos para comenzar a trabajar y sacarle el máximo partido a DataHub!
Si este artículo te ha parecido interesante, te animamos a visitar la categoría Data Engineering para ver otros posts similares a este y a compartirlo en redes. ¡Hasta pronto!
