
El progreso en el campo de la inteligencia artificial durante los últimos años es innegable. La carrera frenética que están llevando a cabo los gigantes tecnológicos por alcanzar modelos más precisos, está originando que la IA se encuentre cada vez más presente en nuestro día a día.
Desde modelos de visión por computador que consiguen realzar las fotografías tomadas por nuestro móvil, hasta algoritmos de machine learning que permiten predecir la tasa de abandono de un empleado. Es decir, se está consiguiendo generar valor a partir de inteligencia artificial.
Sin embargo, el punto común de estos modelos es que todos ellos se tratan de sistemas inteligentes unisensoriales. A diferencia de la inteligencia humana, estos sistemas basan sus predicciones en un único tipo de entrada, un único tipo de sentido humano. Por ejemplo, si hablamos de visión artificial, las famosas redes neuronales convolucionales basan su funcionamiento en imágenes, pero no son capaces de interpretar al mismo tiempo otro tipo de información como podría ser el audio.
Jeff Dean 一 máximo responsable de Google Research 一 en una reciente charla TED, en agosto de 2021, concluye que esta situación desemboca en el problema de que finalmente se obtiene una gran cantidad de modelos independientes muy capacitados para tareas muy concretas. Donde cada modelo tan solo tiene asociado un tipo de dato. Además, este conocimiento entre modelos con tipos de datos diferentes no se transfiere y, por tanto, obliga a los nuevos modelos a aprender todo ese conocimiento desde cero.

Toda esta problemática nace de entender los sistemas inteligentes como unisensoriales, cuando, en realidad, si pretendemos emular la inteligencia humana, nosotros no actuamos así.
Por ejemplo, si un humano ha sido capaz de abstraer el concepto de un leopardo a partir de imágenes no necesitará realizar un aprendizaje desde cero para identificarlo en un video. Esto se debe a que nuestro sistema inteligente es capaz de interpretar diferentes tipos de datos de forma simultánea. Así pues, el objetivo de Google con esta nueva arquitectura, llamada Pathways, es iniciar las transición hacia modelos multisensoriales.
¿Por qué Pathways?
Atendiendo a la tesitura planteada, el objetivo es aunar los distintos modelos con diferentes entradas en un solo modelo multisensorial que sea capaz de interpretar cualquiera de ellos. Es decir, se le agrega al modelo la capacidad humana de tener en cuenta sentidos distintos, como podría ser la imagen y el sonido asociadas a la vista y el oído.
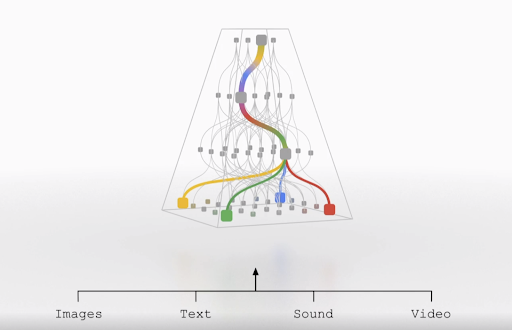
De hecho, tal y como menciona Jeff Dean en la publicación del blog de Google, Pathways no está restringido únicamente a los sentidos que conocemos, sino que podría ser capaz de gestionar otras formas más abstractas de representación del dato.
En segundo lugar, Google presenta esta arquitectura como una forma de conseguir que los modelos no sean entrenados para una sola tarea, sino que permitan la realización de múltiples de ellas. La problemática deriva en el desarrollo de múltiples modelos para tareas individuales y por tanto la necesidad de una mayor cantidad de datos. Cuando, en realidad, una tarea podría ayudar a mejorar el rendimiento de otra.
El ejemplo que presenta Jeff Dean es claro, imaginemos que se entrena un modelo para predecir la elevación del terreno, esta tarea podría ayudar a otro modelo que tratase de predecir cómo una inundación fluirá a través de dicho terreno.
Por último, el tercer inconveniente que resuelve esta arquitectura de nueva generación es la densidad de los modelos. Actualmente, el funcionamiento intrínseco de las redes neuronales provoca que todas las neuronas de la red se activen, en mayor o menor medida, para la realización de una tarea. Este funcionamiento es ineficiente y sobre todo muy dispar a como actúa el cerebro humano.
Tal y como se menciona en la charla TED de Jeff Dean, se conoce que distintas partes de nuestro cerebro son responsables de distintos tipos de tareas. Es decir, para llevar a cabo ciertos procedimientos algunas partes del cerebro no son activadas. Pathways trata de emular dicho comportamiento.
La forma en que se desea conseguir este objetivo es creando un modelo que se active de manera “sparse” o dispersa. Donde no todas las neuronas se activan para realizar la tarea, sino que tan solo se activarán aquellas conexiones que sean necesarias. Este cambio deriva en una mayor rapidez de respuesta y un menor consumo de energía debido a que no consume toda la red.
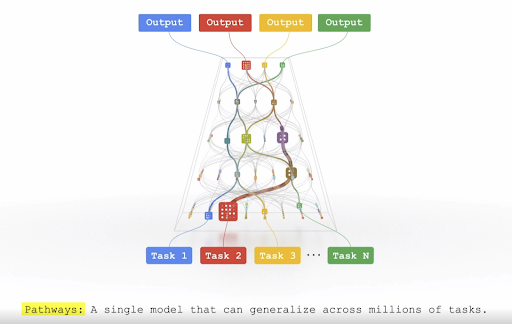
En definitiva, la introducción de esta novedosa arquitectura genera un nuevo camino entre los modelos de inteligencia artificial de próxima generación. Modelos que a su vez emulan cada vez más y mejor el comportamiento de un cerebro humano. Quizás sea esta la primera piedra hacia un tipo de red neuronal asociado a la inteligencia artificial más generalista y más eficiente.
Artículo basado en la publicación de Google AI: Introducing Pathways: A next-generation AI architecture.
Si te ha parecido interesante este artículo, te animamos a visitar la categoría Algoritmos de nuestro blog para ver post similares a este y a compartirlo en redes con todos tus contactos. No olvides mencionarnos para poder conocer tu opinión @Damavisstudio. ¡Hasta pronto!
