
A la hora de desarrollar código, no solo es importante tener en cuenta su funcionalidad, sino también su legibilidad. Este aspecto cobra especial importancia en entornos de trabajo donde un equipo de personas operan sobre el mismo código. Un código legible y unificado mediante unas reglas comunes no solo permite que se entienda mejor, sino que a la postre, también incrementa la productividad de todo el equipo.
Existen diversas herramientas diseñadas para mejorar la calidad del código. Entre ellas destacan formateadores como Black y linters como Ruff o Pylint, que se enfocan en lenguajes como Python y otros similares. Sin embargo, SQLFluff se caracteriza por centrarse exclusivamente en SQL, lo que lo convierte en una herramienta especialmente relevante para ingenieros de datos, dado el papel fundamental que este lenguaje desempeña en su día a día.
¿Qué es SQLFluff?
SQLFluff es una herramienta de linting y autoformateo diseñada específicamente para SQL, que permite mantener estándares de calidad consistentes en el código SQL, reduciendo errores y simplificando revisiones.
Esta es una función especialmente interesante en todo lo relacionado con Data. Esto se debe a que SQL es un lenguaje que cobra gran relevancia en este ámbito, ya que se usa de manera muy recurrente para realizar consultas sobre los datos almacenados. Además, SQLFluff no solo soporta múltiples dialectos SQL, como ANSI, T-SQL, PostgreSQL, BigQuery, entre otros, sino que se integra con herramientas como dbt para analizar y formatear modelos generados dinámicamente.
Instalación de SQLFluff
Una vez explicado qué es y para que se utiliza SQLFluff, el siguiente paso es proceder a su instalación dentro del proyecto que estamos realizando. Para ello, lo más fácil es usar pip o poetry, dependiendo de cómo gestionas tus entornos de desarrollo. En mi caso, yo suelo usar poetry, por lo que lo explicaré siguiendo ese enfoque.
Si gestionas tus dependencias con Poetry, puedes añadir SQLFluff como una dependencia más al archivo pyproject.toml de tu proyecto con el siguiente comando:
poetry add sqlfluffAdemás, si en tu proyecto estás usando DBT, será necesario que también instales el templater de DBT para que SQLFluff pueda procesar correctamente las macros y plantillas.
poetry add sqlfluff-templater-dbtCuando ya esté instalado y esté corriendo dentro de tu entorno virtual, puedes verificar que esté correctamente configurado mediante el comando:
sqlfluff --versionConfiguración básica de SQLFluff
Tras realizar la instalación y comprobar que ya lo tenemos corriendo dentro de nuestro entorno virtual, el siguiente paso es configurarlo para poder sacarle el máximo partido.
La configuración de SQLFluff se realiza mediante un archivo .sqlfluff, que se ha de ubicar en la raíz del proyecto. Este archivo define las reglas de linting, el dialecto SQL y otras opciones personalizables que vamos a ver a continuación.
En primer lugar, es importante definir una serie de configuraciones generales. Para ello, usaremos anotaciones YAML que nos permitirán especificar ciertos parámetros clave como pueden ser el dialecto SQL o el templater que queremos usar. Además, en este fichero también definiremos y personalizaremos datos específicos de cómo queremos que se realice el linting mediante secciones específicas reservadas para ello, como puede ser la indentación o si las palabras clave de SQL deben de estar en mayúscula o minúscula.
Creación del fichero .sqlfluff
Con todo esto en mente, un fichero .sqlfluff con una configuración básica podría ser el siguiente:
[sqlfluff]
dialect = postgres
templater = dbt
max_line_length = 120
processes = -1
[sqlfluff:templater:jinja]
# Path to the jinja templates
loader_search_path = include
ignore_template_errors = True
[sqlfluff:indentation]
# Allow implicit indents in code
allow_implicit_indents = True
tab_space_size = 4
indented_joins = True
template_blocks_indent = True
[sqlfluff:rules:aliasing.length]
# Sets a minimum length of 3 characters for table or column aliases
min_alias_length = 3
max_alias_length = 15
ignore_short_aliases = False
[sqlfluff:rules:capitalisation.keywords]
# SQL keywords must be capitalized
capitalisation_policy = upper
require_capitalisation = True
[sqlfluff:rules:capitalisation.identifiers]
# Identifiers must be lowercase.
extended_capitalisation_policy = lower
[sqlfluff:rules:capitalisation.functions]
# Function names must be capitalized.
extended_capitalisation_policy = upper
[sqlfluff:rules:capitalisation.literals]
# Text values must be lowercase.
capitalisation_policy = lower
[sqlfluff:rules:capitalisation.types]
# SQL data type names (STRING, INTEGER..) must be capitalized.
extended_capitalisation_policy = upper
[sqlfluff:rules:convention.not_equal]
# The inequality operator must be in C style (!= instead of <>)
preferred_not_equal_style = c_styleComo habrás podido observar, hay infinidad de ajustes que se pueden hacer en este punto. Esto otorga una flexibilidad y precisión increíble a SQLFluff, permitiéndote tener un control muy pormenorizado de cómo ha de estar escrito todo tu código SQL.
Una vez que ya se haya configurado esta parte, el siguiente paso es probarlo en un fichero concreto. Para ello, solo tendrás que ejecutar el siguiente comando:
sqlfluff lint path/to/sql_fileY esto te mostrará una salida con todos los ajustes que han de hacerse para cumplir con las especificaciones que has configurado anteriormente.
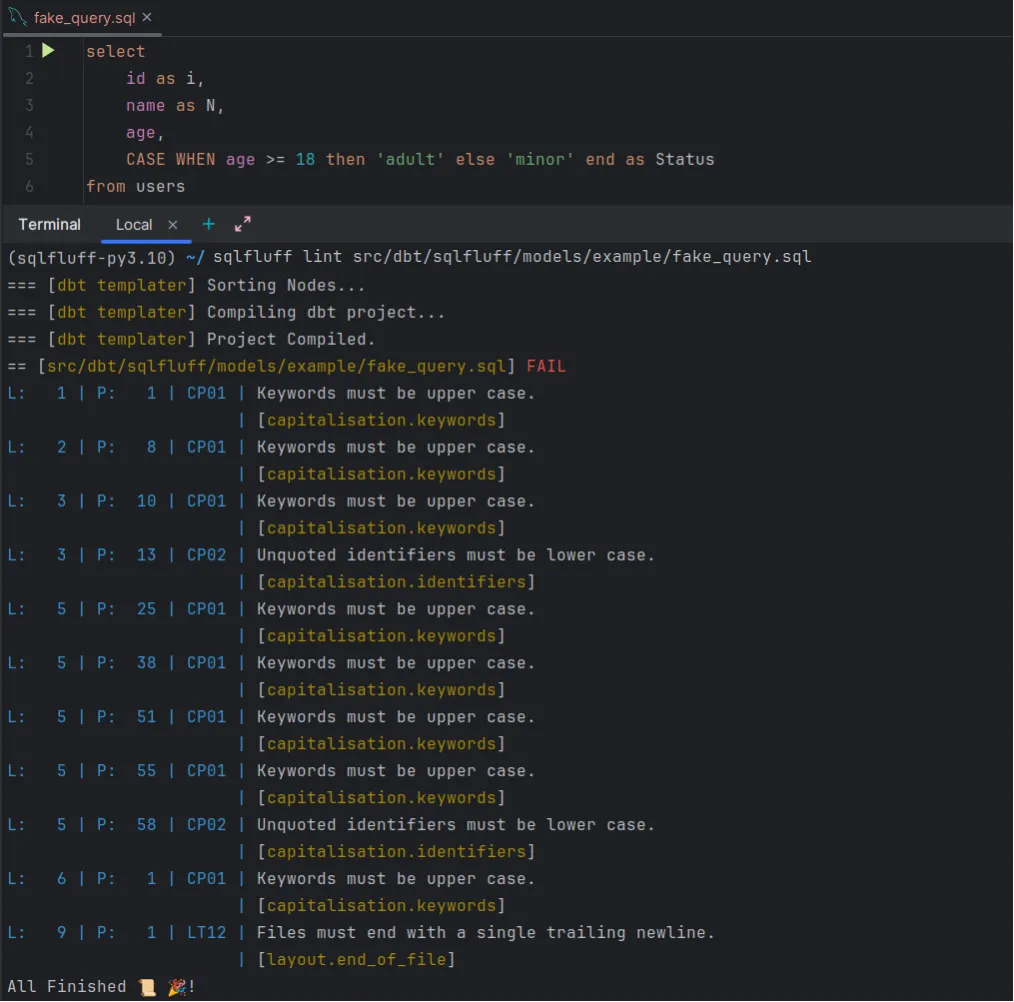
Linter vs Pre-commit en SQLFluff
Una de las características principales de SQLFluff es que no solo ofrece una funcionalidad de linter cuando se ejecuta manualmente, sino que también se puede integrar dentro de pre-commit. De esta manera, se puede automatizar la validación de los archivos que están en el staging antes de confirmar un commit.
Linter
Como acabamos de comentar, SQLFluff puede ejecutarse directamente desde la terminal para comprobar que el código SQL cumple con los parámetros establecidos en tu fichero de configuración.
En este punto, los comandos principales son los siguientes:
- lint: Analiza archivos SQL y muestra errores en relación a las reglas definidas.
sqlfluff lint path/to/sql/files- fix: Primero ejecuta el linter y sobre los errores obtenidos, aplica automáticamente las correcciones necesarias para ajustar el fichero a las reglas definidas.
sqlfluff fix path/to/sql/files- render: Este comando es especialmente útil si usas jinja, ya que te permite ver cómo se van a renderizar los archivos SQL. Es beneficioso a la hora de depurar código generado.
sqlfluff render path/to/sql/file.sql- parse: Por último, mediante este comando, podemos obtener una representación jerárquica del código SQL, lo que nos servirá para ver cómo está estructurado.
sqlfluff parse path/to/sql/file.sqlComo se puede comprobar, las posibilidades de esta herramienta son enormes. Gracias a los comandos explicados anteriormente y otros disponibles en la herramienta (a los que se puede acceder con sqlfluff -h), puedes validar cambios durante el desarrollo sin necesidad de tener que integrarlo con herramientas externas.
Pre-commit
Por otro lado, SQLFluff posee otra funcionalidad que permite que se puede integrar dentro del flujo de pre-commit, ejecutándose automáticamente sobre los archivos preparados para el commit (en staging) y validando que cumplen con las reglas establecidas antes de ser confirmados en el repositorio.
Para ello, ha de configurarse el fichero pre-commit-config.yml de la siguiente manera:
- repo: https://github.com/sqlfluff/sqlfluff
rev: 3.2.5
hooks:
- id: sqlfluff-fix
args: ["--config", ".sqlfluff"]En este punto, se ha de especificar si a la hora de hacer el pre-commit se quiere que se realice únicamente un linter, para lo que habría que configurarlo con:
- id: sqlfluff-lintSin embargo, si se prefiere que aplique los cambios, habría que dejarlo como se indica en el primer ejemplo.
Por otra parte, en el apartado de los argumentos, también es importante especificar el archivo de configuración que se debe de ejecutar. Aunque lo veremos más adelante, en proyectos complejos se pueden tener diferentes ficheros de configuración adaptados a diferentes partes del código.
Integración de SQLFluff con DBT
Pasemos ahora a otro de los puntos fuertes de SQLFluff, que es que se puede integrar con proyectos que utilicen DBT.
Para ello, lo primero que habrá que hacer es incluir el templater de DBT dentro del fichero de .sqlfluff de la siguiente manera:
[sqlfluff:templater:dbt]
# Path to the dbt project.
project_dir = ./src/dbt/sqlfluff
exclude_paths = target/En donde en project_dir se definirá la ruta al proyecto DBT y en exclude_paths se especificarán las rutas que queremos que queden excluidas del análisis.
Una vez realizado este paso, sólo tendremos que tener en cuenta la base de datos que estamos usando e instalar el adaptador necesario para permitir realizar la conexión. En mi caso, dbt-postgres, ya que es la base de datos que estoy utilizando.
poetry add dbt-postgresPor último, si queremos integrarlo con pre-commit, tendremos que añadirlo al archivo pre-commit-config.yaml de la siguiente manera:
- repo: https://github.com/sqlfluff/sqlfluff
rev: 3.2.5
hooks:
- id: sqlfluff-fix
args: ["--config", ".sqlfluff"]
additional_dependencies: ["--sqlfluff-templater-dbt", "dbt-postgres"]Una vez realizado estos ajustes, ya podremos utilizar SQLFluff en código procesado por DBT.
Linting en proyectos DBT
A la hora de hacer linting en un proyecto de DBT, es importante comprender cuales son las principales diferencias al trabajar con DBT o jinja.
En DBT, antes de realizar la validación, se lleva a cabo una compilación del proyecto para comprobar que el SQL generado sea funcional y correcto. De esta manera, también nos asegura que nuestro código es válido dentro de un contexto de DBT. Es decir, si nuestro modelo de DBT no tiene errores de estilo, pero si los tiene de forma, SQLFfluff mostrará un error en el compilado.
Por otro lado, si no se configura el templater de DBT antes de lanzar el linter sobre un proyecto de DBT, éste solamente corregirá los errores de estilo, formateando únicamente el código SQL, pero no tendrá en cuenta la lógica ni el contexto nivel de DBT.
Exclusiones específicas con .sqlfluffignore
El archivo .sqlfluffignore es una herramienta esencial para excluir archivos o directorios específicos del análisis de SQLFluff. Esto es útil cuando en el proyecto se tienen carpetas temporales, archivos generados automáticamente o cualquier contenido que no es necesario que sea procesado.
Al igual que el fichero .sqlfluff de configuración, .sqlfluffignore se ha de ubicar en la raíz del proyecto y debe tener una estructura similar a la siguiente:
# Folders
src/logs/
src/tmp/
__pycache__/
node_modules/
# Files
*.log
*.bak
# Paths
src/test/ignorar
# SQL Files
src/query/TEST1.sql
src/dbt/sqlfluff/models/example/fake_query_ignore.sqlComo se puede observar, al igual que en un fichero .gitignore, se pueden realizar exclusiones a nivel carpeta, tipos de ficheros, paths o directamente sobre ficheros específicos.
Por último, es importante destacar que en si el fichero .sqlfluffignore está ubicado en la raíz del proyecto, SQLFluff lo detectará automáticamente y excluirá los elementos definidos, por lo que no habrá que realizar ninguna configuración adicional.
Uso avanzado de SQLFluff
Múltiples configuraciones
Por último, vamos a hablar sobre cómo integrar distintas configuraciones para proyectos más grandes que incorporen diferentes herramientas. En mi caso, estoy trabajando con un proyecto que integra DBT y Airflow, donde cada herramienta requiere una configuración específica.
Por un lado, DBT necesita incluir la gestión de variables, modelos y dependencias para poder realizar la compilación y la validación de SQL. Por otro, las plantillas de Airflow están basadas en jinja, lo que permite poder ejecutarlo con una configuración más simple.
De igual manera, y aunque en mi caso no es necesario por la gestión actual del proyecto que estoy realizando, se pueden especificar estilos independientes para DTB y Airflow simplemente configurando un archivo de configuración específico para cada herramienta.
Ficheros de configuración
En primer lugar, como se van a integrar dos configuraciones, se crearán dos ficheros .sqlfluff. Cada uno de ellos tendrá la configuración específica adaptada a la herramienta correspondiente y ambos han de ubicarse en la raíz del proyecto.
Por un lado, el destinado a DBT se llamará dbt.sqlfluff y tendrá la configuración especificada anteriormente con el templater de DBT. Por otra parte, el de Airflow se llamará airflow.sqlfluff y contendrá el templater de jinja.
Linter especificando la configuración
Una vez generados ambos ficheros de configuración, el siguiente paso es poder usarlos de manera independiente en la parte del código deseada. Para ello, a la hora de ejecutar el comando con la ruta específica al archivo, se ha de incluir el flag de configuración de la siguiente manera:
sqlfluff lint --config airflow.sqlfluff path/to/sql/fileEsto permitirá usar una u otra configuración en función de cuál sea la parte del código que queremos revisar.
Pre-commit con varios ficheros de configuración
Por último, será necesario configurar el pre-commit para que utilice un fichero de configuración u otro dependiendo de la herramienta o de la parte del proyecto a la que se esté aplicando. Esto se puede lograr modificando el fichero .pre-commit-config.yaml de la siguiente forma:
- repo: https://github.com/sqlfluff/sqlfluff
rev: 3.2.5
hooks:
- id: sqlfluff-fix
args: ["--config", "airflow.sqlfluff"]
exclude: "^src/dbt"
name: "sqlfluff_airflow"
- id: sqlfluff-fix
args: [ "--config", "dbt.sqlfluff" ]
additional_dependencies : ['sqlfluff-templater-dbt', 'dbt-postgres']
files: "^src/dbt"
name: "sqlfluff_dbt"Como se puede observar, se han configurado dos hooks. Uno de ellos tiene la configuración de Airflow y, mediante el exclude, se aplica a todo el proyecto menos a la ruta especificada. El otro posee la configuración necesaria para ejecutar DBT, asociado al fichero de configuración de DBT y se aplica únicamente a los ficheros que estén dentro del path especificado.
Por último, para poder diferenciar ambos procesos, se ha añadido un campo name que permitirá una visualización más clara de lo que se está ejecutando.
Con esta configuración, a la hora de realizar un commit, se ejecutará el pre-commit automáticamente teniendo en cuenta cada parte su configuración específica.
Contextos personalizados en .sqlfluff para Jinja
A la hora de trabajar con jinja es muy común tener variables dinámicas que, si no se manejan apropiadamente, pueden generar errores en el linter de SLQFluff. Para poder evitarlo, se pueden configurar dentro del fichero .sqlfluff contextos personalizados que solucionen estas casuísticas.
En mi caso concreto, en el proyecto de Airflow utilizo variables dinámicas para especificar el dataset al que apuntan las queries. Por esa razón, si no configuro un contexto específico que me reconozca esta casuística, a la hora de realizar el linter me generará un fallo en este punto.
Para testear esta configuración, he generado el siguiente fichero sql de prueba:
CREATE OR REPLACE TABLE `{{ var.value.get('test') }}.ejemplo`
OPTIONS (description = "Ejemplo de query con jinja") AS
SELECT
test.id,
test.name,
test.age,
age.date
FROM
`{{ var.value.get('test') }}.ejemplo_1` AS test
LEFT JOIN
`{{ var.value.get('test') }}.ejemplo_2` AS age
ON test.age = age.age_idY he incluido en el fichero airflow.sqlfluff lo siguiente:
[sqlfluff:templater:jinja:context]
var = {"value": {"test": "ejemplo"}}En este caso, el contexto de jinja especificado a la hora de hacer la compilación sustituirá la variable “test” por el parámetro “ejemplo”, por lo que al ejecutar el linter no mostrará ningún error.
Para comprobar que verdaderamente esto ocurre, ejecuto el render de ese fichero y obtengo este resultado:
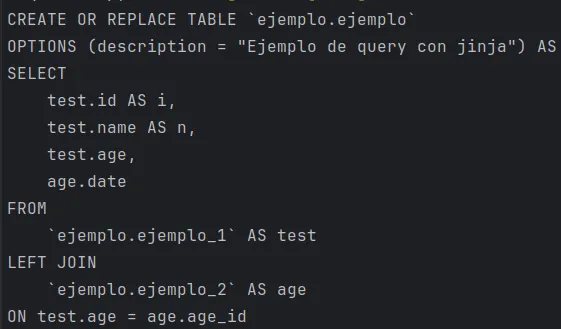
Como se puede observar, ha sustituido la variable “test” por “ejemplo” y, por tanto, me permitirá realizar el compilado sin errores.
Conclusión
Como se ha podido comprobar a lo largo de todo este artículo, SQLFluff es una herramienta increíblemente útil y versátil, especialmente para entornos de trabajo en los que SQL sea el lenguaje por excelencia.
Además, debido a su fácil instalación, su sencillez de uso y a la amplia configuración aplicable, SQLFluff es el linter perfecto para integrarlo en tus proyectos.
Si este artículo te ha parecido interesante, te animamos a visitar la categoría Data Engineering para ver otros posts similares a este y a compartirlo en redes. ¡Hasta pronto!
