
La idea de este artículo es ahorrarles un poco de tiempo a los que están interesados en Elasticsearch y compartir algunos conceptos y recursos que son útiles.
¿Qué es Elasticsearch?
Elasticsearch es un motor de búsqueda distribuido, gratuito y de código abierto desarrollado en Java capaz de manejar todo tipo de datos incluyendo texto, datos numéricos, datos geoespaciales, estructurados y no estructurados.
Para interactuar con el motor de búsqueda, Elasticsearch proporciona una extensa API REST que permite integrar, consultar y administrar los datos. La primera versión de la herramienta fue publicada por Shay Banon en 2010. Hay dos conceptos básicos que definen la esencia de Elasticsearch: elasticidad (elastic) y búsqueda (search).
Elasticsearch es un motor de búsqueda. Elasticsearch no fue creado para hacer de base de datos y no reemplaza a los sistemas de gestión de bases de datos relacionales (RDBMS). Elasticsearch tiene capacidades asombrosas para realizar búsquedas avanzadas, rápidas y casi en tiempo real.
Elasticsearch es muy adaptable a diferentes escenarios. Las características necesarias del motor de búsqueda dependen directamente de la carga de trabajo en el entorno de producción. No es lo mismo un motor de búsqueda para un proyecto pequeño que para una gran empresa que ingesta múltiples terabytes de datos y recibe millones de peticiones de búsqueda diarias. Elasticsearch, mediante su modelo distribuido y la fragmentación de los datos, permite adaptar el motor de búsqueda a ambos escenarios.
Componentes principales
En este apartado se introducen los componentes principales que definen a Elasticsearch.
Índices
En Elasticsearch un documento contiene información de un único objeto y se almacena como un objeto JSON, es decir, un documento es un conjunto de claves (nombres de los campos) y valores (strings, números, booleanos, fechas, arrays, etc.). De esta manera, se soportan objetos con estructuras complejas. Elasticsearch está diseñado para poder hacer consultas avanzadas a este tipo de documentos. Un índice no es más que una colección de documentos relacionados entre sí.
Cuando Elasticsearch recibe un objeto raw, el objeto se parsea, se le añade la metadata creando el correspondiente documento, y se indexa. Se podría decir que un índice en Elasticsearch es lo análogo a una tabla en una base de datos relacional. En la práctica, el modelo de índices resulta ser más flexible. Por ejemplo, los índices se utilizan para organizar los datos y aumentar el rendimiento.
Un uso muy común de Elasticsearch es manejar datos de logs, y un formato estándar es asignar un nuevo índice a cada día. Los índices son estructuras muy livianas internamente, crear y destruir índices es barato para Elasticsearch, por lo que un cluster puede contener cientos de índices sin problema.
Elastic proporciona una API para crear, administrar y borrar índices. Por ejemplo, el siguiente comando crea un índice con el nombre persona que contiene documentos con los campos nombre y apellido, ambos del tipo texto.
PUT /persona
{
"mappings": {
"properties": {
"nombre": { "type": "text" },
"apellido": { "type": "text" }
}
}
} El siguiente comando añade un documento al índice:
POST persona/_doc/1
{
"nombre": "Test",
"apellido": "Test"
}Para borrar el índice basta con ejecutar DELETE /persona.
Clúster
Un clúster en Elasticsearch no es más que un conjunto de nodos (ya sea un servidor físico, un servidor virtual, etc.) separados físicamente pero conectados entre sí mediante una red. Cualquier nodo del clúster puede gestionar tráfico HTTP y reenviar las solicitudes de los clientes a cualquier otro nodo. Esto es lo que otorga a Elasticsearch la propiedad de ser un motor de búsqueda distribuido. Por ejemplo, si estás ejecutando Elasticsearch de manera local en un solo nodo, entonces tienes un clúster de un nodo.
Elasticsearch asigna a cada nodo de un clúster uno o múltiples roles. Los roles principales son:
- Nodo maestro: Es el nodo más importante del clúster, y solamente puede haber uno. Su responsabilidad es realizar acciones a nivel de clúster. Por ejemplo, crear/borrar un índice, trackear qué nodos forman el clúster, o decidir a qué nodo asignar cada fragmento. Es importante para la salud del clúster tener un nodo maestro estable.
- Nodo elegible como maestro: Este nodo es un candidato para convertirse en el nodo maestro en el futuro. Elasticsearch elige un nuevo nodo maestro entre los nodo elegibles en caso de ser necesario, por ejemplo, cuando el nodo maestro está fuera de servicio. Elasticsearch elige el nuevo nodo maestro mediante un proceso de votación entre los nodos. Se puede dar el caso en el que el nodo maestro o los nodos elegibles como maestros estén ocupados y no puedan realizar ciertas tareas importantes para la salud del clúster. Por ello, en la práctica es muy habitual no asignar más roles al nodo maestro y a los nodos elegibles como maestros para permitirles centrarse en la gestión del clúster. Un clúster pequeño o con poca carga puede funcionar bien si sus nodos aptos para maestros tienen otras funciones y responsabilidades. Sin embargo, una vez que el clúster tiene cierto tamaño, por lo general tiene sentido utilizar los nodos maestros exclusivamente para la gestión del clúster. El número de nodos elegibles a maestro suele ser 3, y la única razón por la que pasaría de 3 es si necesita poder soportar el fallo de más de un nodo elegible a maestro en un mismo instante.
- Nodo de datos: Son los nodos que contienen los documentos. Estos nodos manejan operaciones relacionadas con datos como CRUD, búsqueda y agregaciones, es decir, operaciones I/O demandantes a nivel de memoria y CPU. Por ello es importante monitorizar estos nodos y añadir más en caso de que estén sobrecargados.
Elasticsearch proporciona una API para obtener información relevante de cada nodo. Puedes obtener los roles de cada nodo de tu cluster de Elasticsearch mediante el siguiente comando:
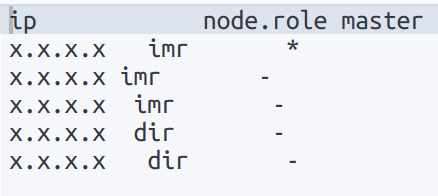
GET _cat/nodes?v=true&h=ip,node.role,masterLa siguiente imagen muestra el output de la consulta para un clúster con cinco nodos. En la columna node.role las siglas m y d hacen referencia a los roles de elegible como maestro y de datos respectivamente. Por lo que el clúster tiene tres nodos elegibles como maestro (uno de ellos el nodo maestro, indicado con *) y dos nodos de datos.
Fragmentos
Es común que la capacidad de almacenamiento de un nodo no sea suficiente para guardar todos los documentos de un índice. Por ello, Elasticsearch permite distribuir un índice en los nodos del clúster mediante técnicas de fragmentación (sharding).
Básicamente, se dividen todos los documentos de un índice en un número fijo de fragmentos (shards) y el fragmento es la unidad en la que Elasticsearch distribuye los datos en el clúster. La distribución de los fragmentos por los diferentes nodos se realiza de forma automática por Elasticsearch. Esta división proporciona dos ventajas principales; posibilidad de escalar horizontalmente (añadir más nodos al clúster) y paralelizar consultas en los diferentes nodos.
Hay dos tipos de fragmentos: primarios y réplicas. Cada documento en un índice pertenece a un fragmento primario. Un fragmento de réplica es una copia de un fragmento primario. Las réplicas proporcionan copias redundantes de sus datos para protegerse contra fallos de hardware y aumentar la capacidad para atender peticiones. Elasticsearch se encarga de colocar en nodos diferentes del fragmento principal, ya que dos copias de los mismos datos en el mismo nodo no agregarían protección si el nodo fallase.
El número de fragmentos primarios de un índice solo se puede configurar en el momento de la creación del índice y no se puede cambiar después. Sin embargo, la cantidad de fragmentos de réplica se puede cambiar en cualquier momento.
Haciendo uso de la API de Elasticsearch, el siguiente comando crea el índice persona con tres shards primarios y dos réplicas para cada uno (en total 6 fragmentos):
PUT /persona
{
"mappings": {
"properties": {
"nombre": { "type": "text" },
"apellido": { "type": "text" }
}
},
"settings": {
"index": {
"number_of_shards": 3,
"number_of_replicas": 2
}
}
}Para cambiar el número de fragmentos de réplica del índice, se utiliza el siguiente comando:
PUT /persona/_settings
{
"index" : {
"number_of_replicas" : 3
}
}Supongamos que tenemos un clúster con 3 nodos elegibles como maestros dedicados a ello y 4 nodos de datos. Además, tenemos el índice persona con 4 fragmentos y 4 réplicas. La siguiente imagen muestra cómo distribuiría Elasticsearch los 16 fragmentos entre los nodos del clúster:
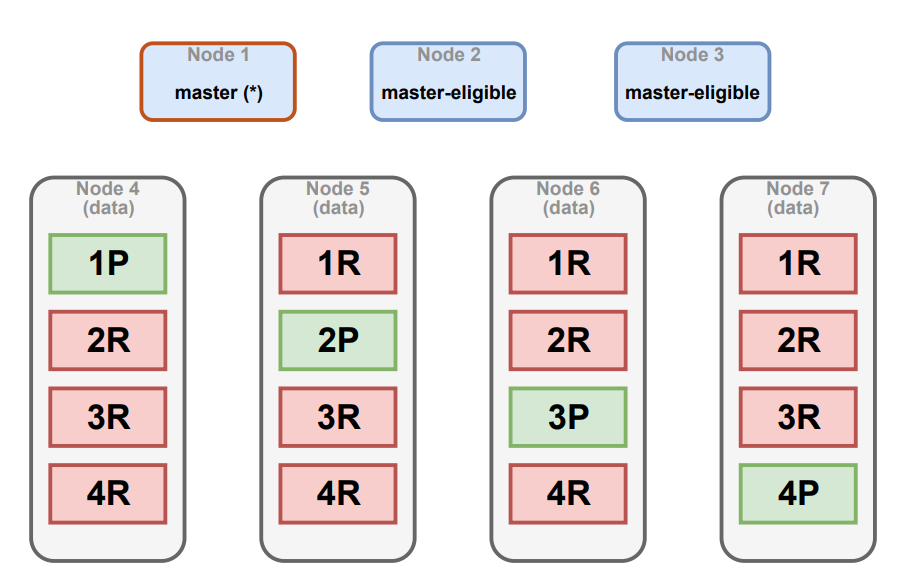
Los tres nodos superiores son los nodos elegibles como maestro (siendo uno de ellos el maestro) encargados de administrar el clúster. Los cuatro nodos inferiores son nodos de datos. Las cajas verdes y rojas hacen referencia a los fragmentos primarios y réplicas respectivamente. Cada nodo de datos contiene cuatro fragmentos, uno primario y tres réplicas.
Observamos que, en caso de que un nodo de datos se pierda, por ejemplo el nodo 7, el clúster podrá seguir funcionando sin problemas ya que estos datos están replicados en otra parte del clúster. Esta configuración podría soportar la pérdida incluso de dos nodos de datos.
Configurar un clúster de Elasticsearch
El diseño del clúster es una parte crítica a la hora de utilizar Elasticsearch. ¿Cuántos nodos necesito? ¿Es mejor tener pocos nodos muy potentes, o aumentar el número de nodos pero utilizar instancias con menos capacidad? ¿Un índice grande o dividir los datos en muchos índices pequeños? ¿Cuántos fragmentos primarios y réplicas utilizar?
Estas son algunas de las preguntas que pueden surgir a la hora de configurar un clúster de Elasticsearch. El hecho de que Elasticsearch sea adaptable a muchos tipos de escenarios, también hace que su configuración pueda ser compleja.
De hecho, no hay forma de que alguien pueda decirte cómo diseñar un clúster perfecto. Sin embargo, sí hay una lista de cosas y consejos que se deberían tener en cuenta cuando se configura un cluster para que se adapte a las necesidades.
- Conoce tu escenario: Hay que conocer en profundidad cuál será la carga de trabajo, número de búsquedas/escriturar por segundo, qué tan rápido crecerán sus índices y qué tipo de consultas ejecutarán sus usuarios, con qué tipo de contenido, etc. La realidad es que conocer esto en el vacío es difícil, y probablemente se tenga que iterar 2 o 3 veces en el diseño del clúster antes de obtener el clúster perfecto.
- Número de shards: Cada query se ejecuta en un solo thread por fragmento, pero se pueden procesar varios fragmentos en paralelo. Consultar muchos fragmentos pequeños hará que el procesamiento por fragmento sea más rápido, pero como se deben poner en cola y procesar muchas más tareas en secuencia, no necesariamente será más rápido que consultar una cantidad menor de fragmentos más grandes. En resumen: depende. Un consejo suele ser tratar de mantener el tamaño de los fragmentos entre unos pocos GB y algunas decenas de GB. Es común ver fragmentos en el rango de 20 GB a 40 GB. Es decir, si tienes un índice con 100 fragmentos de 100MB probablemente necesites menor número de fragmentos. La mejor manera de determinar el número ideal de fragmentos de un índice es hacer benchmarking con una carga representativa de lo que se va a encontrar el nodo en producción.
- Número de réplicas: Como las réplicas siempre se asignan a diferentes nodos que el fragmento principal, para que un sistema sea capaz de soportar n réplicas, tendrá que tener al menos n+1 nodos. Por ejemplo, si tenemos un clúster de 2 nodos y el número de réplicas es 6, solamente una de las réplicas será asignada el estado del cluster será naranja). Sin embargo, un clúster con 7 nodos puede perfectamente soportar un fragmento primario y 6 réplicas. Es decir, el número de nodos del clúster nos pone un límite superior de réplicas que podemos soportar. El factor de réplica predeterminado de Elasticsearch es 1, pero puede ser interesante tener un factor de replicación más alto. Por ejemplo, un factor de réplica alto puede ser muy interesante en caso de tener un dataset pequeño (que todo el índice entre en un nodo) y gran número de queries. Supongamos que tenemos 10 nodos, asignando un fragmento primario y un factor de réplica de 9 conseguimos que en cada uno de los nodos esté el dataset completo, lo que ayudará a paralelizar las queries de búsqueda. Este es un ejemplo en el que el número de réplicas puede afectar directamente al rendimiento del clúster. Sin embargo, las réplicas no son gratis. Estas consumen memoria y espacio en disco, al igual que los fragmentos primarios por lo que también es importante no tener demasiados. La gestión de las réplicas puede sobrecargar al nodo maestro, que podría dejar de responder.
- Número de nodos: Disponer de al menos 3 nodos maestros elegibles. Preferiblemente no asignar más roles al nodo maestro y a los nodos elegibles como maestros para permitirles centrarse en la gestión del clúster. Respecto a los nodos de datos, cuanto más grande se vuelve el clúster y más datos contiene, más nodos de datos se necesitarán. El número de nodos está muy relacionado con la regla de mantener los fragmentos con un tamaño de algunas decenas de GB.
- Número de índices: Por lo general, el problema no es tanto en términos de número de índices sino del número de fragmentos, que son las unidades físicas de almacenamiento de datos. Muchos índices pequeños y fragmentos son muy ineficientes, por lo que casi siempre es mejor consolidar.
Conclusión
Elasticsearch es una herramienta muy potente que se utiliza en diversos escenarios gracias a su adaptabilidad. En este artículo hemos presentado los principales componentes y cómo mediante el modelo de fragmentación se consiguen distribuir los documentos y las queries a lo largo del clúster. También hemos presentado algunos aspectos importantes que hay que tener en cuenta a la hora de diseñar un cluster de Elasticsearch.
Sin embargo, esto no es más que la punta del iceberg, ya que Elasticsearch es una herramienta muy compleja que requiere de gran conocimiento técnico para sacarle todo el partido y hay todo un ecosistema de tecnologías montadas en torno a Elasticsearch.
Si te ha parecido útil este post, te animamos a ver otros artículos de la categoría Software en nuestro blog. No olvides compartirlo con tus contactos para que ellos también puedan leerlo y opinar. ¡Nos vemos en redes!
