
The idea of this article is to save some time for those interested in Elasticsearch and to share some useful concepts and resources.
What is Elasticsearch?
Elasticsearch is a free, open source, distributed search engine developed in Java capable of handling all types of data including text, numerical data, geospatial, structured and unstructured data.
To interact with the search engine, Elasticsearch provides an extensive API REST to integrate, query and manage the data. The first version of the tool was published by Shay Banon in 2010. There are two basic concepts that define the essence of Elasticsearch: elasticity (elastic) and search (search).
Elasticsearch is a search engine. Elasticsearch was not created to be a database and does not replace relational database management systems (RDBMS). Elasticsearch has amazing capabilities to perform advanced, fast and near real-time searches.
Elasticsearch is highly adaptable to different scenarios. The required search engine features depend directly on the workload in the production environment. A search engine for a small project is not the same as a search engine for a large enterprise that ingests multiple terabytes of data and receives millions of search requests per day. Elasticsearch, through its distributed model and data fragmentation, allows the search engine to adapt to both scenarios.
Main components
This section introduces the main components that define Elasticsearch.
Index
In Elasticsearch a document contains information from a single object and is stored as a JSON object, that is, a document is a set of keys (field names) and values (strings, numbers, booleans, dates, arrays, etc.). In this way, objects with complex structures are supported. Elasticsearch is designed to be able to make advanced queries on this kind of documents. An index is nothing more than a collection of related documents.
When Elasticsearch receives a raw object, the object is parsed, metadata is added to it creating the corresponding document, and it is indexed. You could say that an index in Elasticsearch is analogous to a table in a relational database. In practice, the index model turns out to be more flexible. For example, indexes are used to organise data and increase performance. A very common use of Elasticsearch is to manage log data, and a standard format is to assign a new index to each day. Indexes are very lightweight structures internally, creating and destroying indexes is cheap for Elasticsearch, so a cluster can contain hundreds of indexes with no problem.
Elastic provides an API for creating, managing and deleting indexes. For example, the following command creates an index with the name person containing documents with the fields name and last name, both of type text.
PUT /person
{
"mappings": {
"properties": {
"name": { "type": "text" },
"lastname": { "type": "text" }
}
}
} The following command adds a document to the index:
POST person/_doc/1
{
"name": "Test",
"lastname": "Test"
}To delete the index, simply execute DELETE /person.
Cluster
A cluster in Elasticsearch is nothing more than a set of nodes (either a physical server, a virtual server, etc.) physically separated but connected to each other through a network. Any node in the cluster can handle HTTP traffic and forward client requests to any other node. This is what gives Elasticsearch the property of being a distributed search engine. For example, if you are running Elasticsearch locally on a single node, then you have a one-node cluster.
Elasticsearch assigns each node in a cluster one or multiple roles. The main roles are:
- Master Node: This is the most important node in the cluster, and there can only be one. Its responsibility is to perform actions at the cluster level. For example, creating/deleting an index, tracking which nodes form the cluster, or deciding which node to assign each shard to. It is important for the health of the cluster to have a stable master node.
- Master-eligible node: This node is a candidate to become the master node in the future. Elasticsearch chooses a new master node from among the eligible nodes if necessary, for example, when the master node is out of service. Elasticsearch chooses the new master node by a voting process among the nodes. It may be the case that the master node or nodes eligible as master are busy and cannot perform certain tasks that are important for the health of the cluster. Therefore, in practice, it is very common not to assign more roles to the master node and master-eligible nodes to allow them to focus on cluster management. A small or lightly loaded cluster can function well if its master-eligible nodes have other roles and responsibilities. However, once the cluster is of a certain size, it usually makes sense to use the master nodes exclusively for cluster management. The number of master-eligible nodes is usually 3, and the only reason you would go beyond 3 is if you need to be able to support the failure of more than one master-eligible node at any one time.
- Data node: These are the nodes that contain the documents. These nodes handle data-related operations such as CRUD, search and aggregations, that is, I/O operations that are demanding on memory and CPU. It is therefore important to monitor these nodes and add more in case they are overloaded.
Elasticsearch provides an API to obtain relevant information from each node. You can get the roles of each node in your Elasticsearch cluster using the following command:
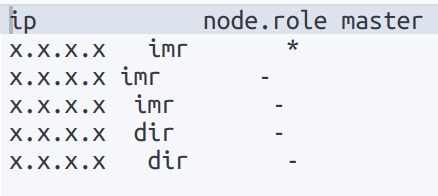
GET _cat/nodes?v=true&h=ip,node.role,masterThe following image shows the output of the query for a cluster with five nodes. In the node.role column, the acronyms m and d refer to the roles of master-eligible and data-eligible respectively. So the cluster has three master-eligible nodes (one of them the master node, indicated with *) and two data nodes.
Fragments
It is common that the storage capacity of a node is not enough to store all the documents of an index. For this reason, Elasticsearch allows to distribute an index on the cluster nodes by means of sharding techniques. Basically, all the documents of an index are divided into a fixed number of shards and the shard is the unit in which Elasticsearch distributes the data in the cluster. The distribution of the shards across the different nodes is done automatically by Elasticsearch. This division provides two main advantages; the possibility to scale horizontally (adding more nodes to the cluster) and to parallelise queries on the different nodes.
There are two types of shards: primary and replica. Each document in an index belongs to a primary shard. A replica shard is a copy of a primary shard. Replicas provide redundant copies of your data to protect against hardware failures and increase capacity to handle requests. Elasticsearch is responsible for placing on different nodes from the primary shard, as two copies of the same data on the same node would not add protection if the node failed.
The number of primary shards in an index can only be configured at the time of index creation and cannot be changed afterwards. However, the number of replica shards can be changed at any time.
Using the Elasticsearch API, the following command creates the index person with three primary shards and two replicas for each (in total 6 shards):
PUT /person
{
"mappings": {
"properties": {
"name": { "type": "text" },
"lastname": { "type": "text" }
}
},
"settings": {
"index": {
"number_of_shards": 3,
"number_of_replicas": 2
}
}
}To change the number of index replica fragments, the following command is used:
PUT /person/_settings
{
"index" : {
"number_of_replicas" : 3
}
}Let’s assume we have a cluster with 3 dedicated master eligible nodes and 4 data nodes. In addition, we have the person index with 4 shards and 4 replicas. The following image shows how Elasticsearch would distribute the 16 shards among the cluster nodes:
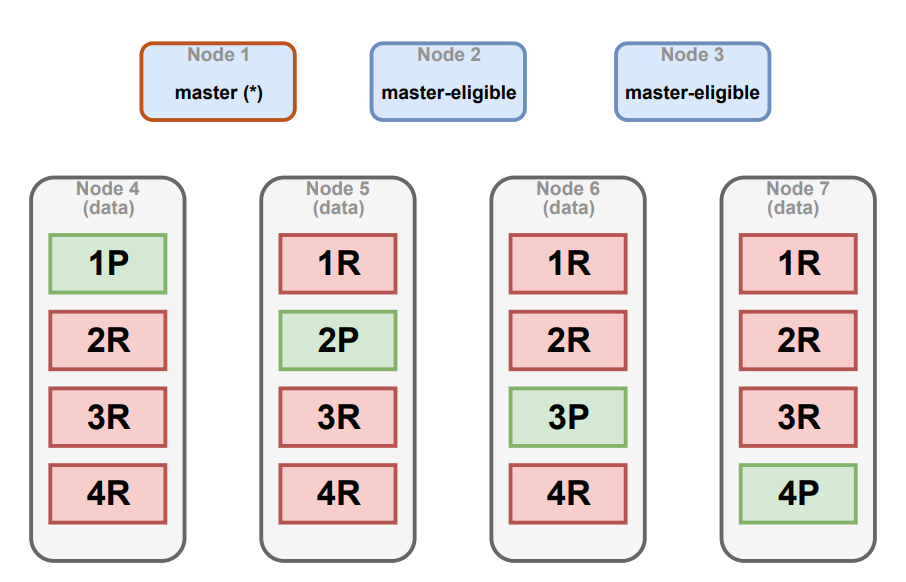
The top three nodes are the master-eligible nodes (one of them being the master) in charge of managing the cluster. The bottom four nodes are data nodes. The green and red boxes refer to the primary shards and replicas respectively.
Each data node contains four shards, one primary and three replicas. You notice that in case a data node is lost, for example node 7, the cluster can continue to function without problems as this data is replicated elsewhere in the cluster. This configuration could support the loss of even two data nodes.
Setting up an Elasticsearch cluster
Cluster design is a critical part of using Elasticsearch. How many nodes do I need? Is it better to have a few very powerful nodes, or increase the number of nodes but use instances with less capacity? One large index or split the data into many small indexes? How many primary shards and replicas to use?
These are some of the questions that may arise when setting up an Elasticsearch cluster. The fact that Elasticsearch is adaptable to many types of scenarios also means that its configuration can be complex.
In fact, there is no way anyone can tell you how to design a perfect cluster. However, there is a list of things and tips that should be taken into account when configuring a cluster to suit your needs.
- Know your scenario: You need to know in depth what the workload will be, number of searches/types per second, how fast your indexes will grow and what kind of queries your users will run, with what kind of content, etc. The fact is that knowing this in a vacuum is difficult, and you will probably have to iterate 2 or 3 times on the cluster design before you get the perfect cluster.
- Number of shards: Each query is executed in a single thread per shard, but multiple shards can be processed in parallel. Querying many smaller shards will make per shard processing faster, but since many more tasks must be queued and processed in sequence, it will not necessarily be faster than querying a smaller number of larger shards. In short… it depends. One tip is to try to keep the size of the shards between a few GB and a few tens of GB. It is common to see shards in the range of 20 GB to 40 GB. That is, if you have an index with 100MB shards you probably need fewer shards. The best way to determine the ideal number of shards for an index is to benchmark with a load representative of what the node will encounter in production.
- Number of replicas: As replicas are always assigned to different nodes than the main shard, for a system to be able to support n replicas, it will have to have at least n+1 nodes. For example, if we have a 2-node cluster and the number of replicas is 6, only one of the replicas will be assigned (the cluster state will be orange). However, a cluster with 7 nodes can perfectly well support a primary shard and 6 replicas. That is, the number of nodes in the cluster puts an upper limit on the number of replicas we can support. The default replication factor of Elasticsearch is 1, but it can be interesting to have a higher replication factor. For example, a high replication factor can be very interesting in case you have a small dataset (the whole index goes into one node) and a large number of queries. Suppose we have 10 nodes, by assigning a primary fragment and a replication factor of 9 we get the complete dataset in each of the nodes, which will help to parallelise the search queries. This is an example where the number of replicas can directly affect the performance of the cluster. However, replicas are not free. They consume memory and disk space, as do primary shards, so it is also important not to have too many of them. Managing replicas can overload the master node, which may become unresponsive.
- Number of nodes: Have at least 3 eligible master nodes. Preferably do not assign more roles to the master node and eligible nodes as masters to allow them to focus on cluster management. Regarding the data nodes, the larger the cluster becomes and the more data it contains, the more data nodes will be needed. The number of nodes is closely related to the rule of keeping shards with a size of a few tens of GB.
- Number of indexes: Usually, the problem is not so much in terms of the number of indexes but in terms of the number of shards, which are the physical units of data storage. Many small indexes and shards are very inefficient, so it is almost always better to consolidate.
Conclusion
Elasticsearch is a very powerful tool that can be used in a variety of scenarios thanks to its adaptability. In this article we have presented the main components and how the fragmentation model is used to distribute the documents and queries throughout the cluster. We have also presented some important aspects to take into account when designing an Elasticsearch cluster.
However, this is only the tip of the iceberg, as Elasticsearch is a very complex tool that requires a lot of technical knowledge to get the most out of it and there is a whole ecosystem of technologies built around Elasticsearch.
If you found this post useful, we encourage you to see other articles in the Software category on our blog. Don’t forget to share it with your contacts so that they can also read it and give their opinion. See you in networks!
