
En un artículo anterior detallamos qué es el RAG (Retrieval Augmented Generation) y cómo aprovechar los modelos de embedding para ampliar el conocimiento de un LLM con nuestra propia base documental.
En este post, hablaremos de la implementación de un sistema de RAG en la práctica, además de algunas extensiones que se pueden realizar para dotar a sistemas basados en grandes modelos de lenguaje (LLMs, por sus siglas en inglés) de herramientas y extensiones.
El framework LlamaIndex
Un proyecto actual que implementa RAG es LlamaIndex. En sus inicios fue concebido como una librería que facilitase la implementación de sistemas de RAG y su puesta en servicio para aplicaciones.
LlamaIndex proporciona clases y métodos específicos de alto y bajo nivel para los numerosos pasos de una aplicación RAG: ingesta de datos documentales en muy diversos formatos, interpretación de los documentos, división de los mismos en nodos, enriquecimiento con metadatos, embebimiento en vectores y almacenamiento en bases de datos dedicadas, construcción de un índice (la clase central en la librería que relaciona documentos con sus vectores asociados) y realización de consultas al índice, pudiendo establecer qué LLM (con proveedores externos vía API o instancias locales) usar en cada paso.
La estructura a alto nivel posibilita la construcción de demostraciones sencillas de RAG en muy pocas líneas de código. Por otro lado, la estructura a bajo nivel permite afinar el desarrollo para situaciones particulares y lo hace viable como librería para aplicaciones en producción.
Otro proyecto similar a LlamaIndex es LangChain. Esta librería proporciona los componentes necesarios para construir aplicaciones de RAG de una manera más accesible, implementando a alto nivel muchas herramientas similares a las de LlamaIndex. Sin embargo, LlamaIndex es más flexible al tener métodos de más bajo nivel. Además, posee una enorme participación comunitaria que se traduce en numerosas extensiones de la librería, como por ejemplo para la ingestión de formatos variados de documentos.
Versión mínima de demo
Podemos ilustrar la versión mínima de un chatbot aumentado con una documentación en apenas 5 líneas de código Python, y es el primer tutorial ofrecido en la documentación de LlamaIndex. El siguiente bloque de código ilustra las capacidades a alto nivel de esta librería. Como prerrequisito, es necesario exportar la clave de OpenAI que da acceso a los LLMs y modelos de embedding que se requieren (aunque es posible configurarlo para utilizar otros modelos ya sean locales o provistos por terceros), además de crear la carpeta “data” con archivos de texto sobre los que ejecutar el RAG.
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)
chat_engine = index.as_chat_engine()
chat_engine.chat()Desgranando paso a paso, la anterior demo hace lo siguiente:
- Lee e interpreta todos los documentos de la carpeta local “data”. Los convierte en objetos de la clase de LlamaIndex “Document”, dotándolos de un ID y metadatos adicionales.
- Crea un índice, el objeto central de la librería. En este paso, se trocean los documentos en nodos, y se calculan los vectores o embeddings correspondientes dichos nodos. Este índice almacena en memoria tanto los vectores como la referencia a los nodos y documentos originales. El modelo de embedding usado por defecto es text-embedding-ada-002, ofrecido por OpenAI.
- Se inicializa un chatbot con ChatGPT 3.5 (el modelo por defecto) cuyas capacidades quedan aumentadas con el índice de RAG creado en el paso anterior.
Esta minúscula demostración ilustra muy bien algunos pasos que serían necesarios diseñar e implementar en una aplicación de RAG para producción. Por una parte, tenemos la ingestión (paso 1). Es decir, la carga y gestión de una base documental con la cual queremos ampliar las capacidades del LLM. En este caso, disponemos de los documentos en local. Trabajando con clases y métodos a bajo nivel, es posible programar pipelines de ingestión complejas a partir de diversas fuentes. También conviene realizar un preprocesado de dichos documentos.
En un segundo paso, la carga del índice se puede personalizar en muchos aspectos: qué modelo de embedding queremos utilizar, qué metadatos se quieren añadir a los vectores, dónde guardarlos. En este ejemplo quedan en la memoria RAM, en producción es necesario guardarlos en una base de datos dedicada. También es posible construir un flujo de trabajo que cargue un índice precomputado y recalcule embeddings solo de documentos nuevos o cuyo contenido haya cambiado.
Por último, el uso del índice es en este caso el despliegue de un chatbot, pero es posible el uso de un sistema de RAG con muy distintos objetivos. Aquí podríamos afinar el prompt que recibe el LLM, convertirlo en un agente capaz de ejecutar funciones, darle más de un índice sobre el que hacer RAG, etc.
La librería ofrece muchas herramientas a bajo nivel que permite implementar cada uno de estos pasos de manera flexible, adaptándose a muy diversos casos de uso.
De lenguaje natural a SQL
Una interesante variante del RAG permite además consultar datos estructurados a partir de lenguaje natural. La idea básica es proporcionar a un LLM como contexto el esquema de una base de datos relacional, junto con una pregunta que pueda ser respondida lanzando una consulta a dicha base de datos.
Un ejemplo a sencillo sería, considerando una base de datos de compras en una tienda online, lanzar la siguiente pregunta:
User: ¿Cuál es el producto que más ha vendido en el año 2023 entre los jóvenes de 15 a 25 años?
Un sistema de RAG conectado a una base de datos (que suponemos cuenta con tablas como para responder a dicha pregunta) procesaría la pregunta de la siguiente manera, pasándole a un LLM el siguiente enriquecimiento con la información contextual.
User: A continuación sigue una pregunta, y posteriormente, un esquema de una base de datos. Tu tarea es escribir una consulta SQL sintácticamente correcta y que solo involucre tablas y columnas del esquema dado y que permita resolver la pregunta.
Pregunta: ¿Cuál es el producto que más ha vendido en el año 2023 entre los jóvenes de 15 a 25 años?
Esquema:
- table “historic_sales”: (timestamp, product_id, quantity, user_id)
- table “product_catalogue”: (id, product_name, description)
- table “users”: (id, full_name, age, email)
LLM:
SELECT product_catalogue.product_name FROM historic_sales
JOIN product_catalogue ON historic_sales.product_id = product_catalogue.id
JOIN users ON historic_sales.user_id = users.id
WHERE users.age BETWEEN 15 AND 25 AND EXTRACT(YEAR FROM historic_sales.timestamp) = 2023 GROUP BY product_id ORDER BY SUM(quantity)
LIMIT 1El sistema puede ser complementado con una componente que se encargue de ejecutar dicha consulta a base de datos. Así, permitiría resolver de manera exacta la consulta del usuario. Una ventaja de este acercamiento es que los datos permanecen siendo privados al LLM en caso de requerir el uso de una API externa, solo el esquema de la base de datos es enviado al LLM. Una extensión habitual del ejemplo anterior es la provisión al LLM de las claves primarias y secundarias y, en caso de permitirlo la base de datos, de descripciones de las columnas y qué representa cada una de ellas, aumentando la calidad de las consultas SQL sugeridas.
LlamaIndex cuenta con su propia implementación de un sistema de RAG-SQL a través de la clase NLSQLTableQueryEngine. Esta clase efectúa RAG en varios pasos: trae la información esquemática de la base de datos, la ofrece a un LLM que construye la consulta SQL, la ejecuta y usa la información obtenida para dar una respuesta final al usuario.
El primer paso de RAG sobre los esquemas de la base de datos es necesario para rescatar únicamente los esquemas requeridos para la construcción de la consulta SQL. De utilizar todos los esquemas, esta información podría salirse de la ventana contextual que acepta el LLM.
Agentes
El ejemplo anterior pone de manifiesto la utilidad de utilizar LLMs o sistemas de RAG como componentes de sistemas de información más complejos. En este sentido, tanto LlamaIndex como Langchain permiten la construcción de “agentes”. Este concepto fue ya desarrollado por OpenAI al permitir en su API la “llamada a funciones”: una consulta a un modelo GPT junto con la estructura de una función permite al modelo, dada una pregunta, devolver qué inputs de entrada necesitaría la función para poder responder a la misma.
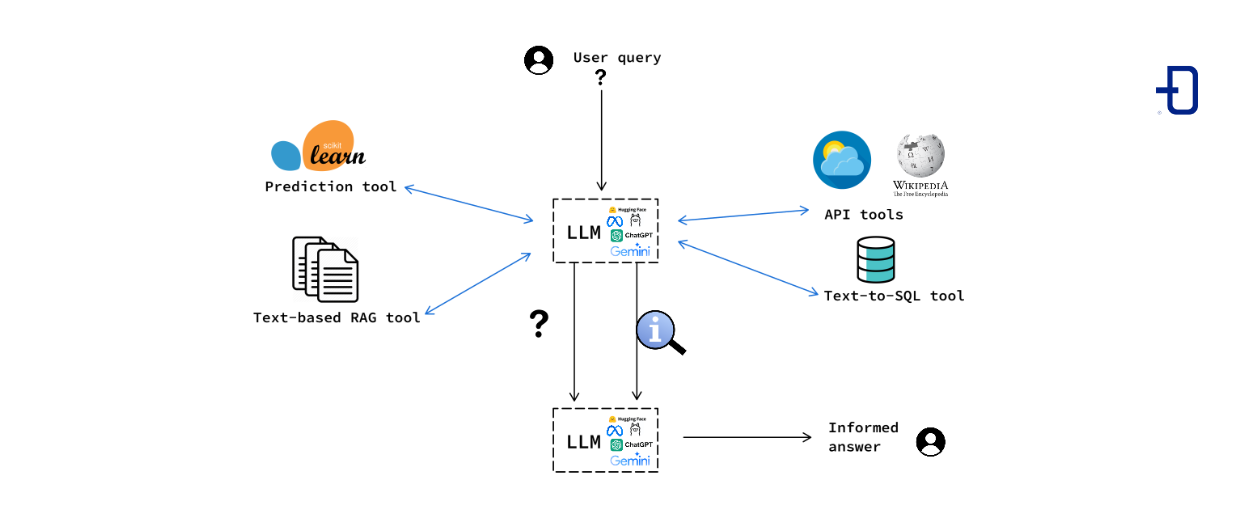
Un agente, en este contexto, se compone de un LLM y una serie de herramientas, que pueden ser de muy diversa naturaleza, acompañadas de una descripción de su funcionalidad. Como ejemplos de estas herramientas podemos considerar funciones de Python, llamadas externas a APIs, sistemas de RAG, sintetizadores de consultas SQL desde lenguaje natural, modelos de predicción, etc.
El componente central del agente es un LLM que, a partir del prompt (consulta) del usuario, el historial de conversación y el conjunto de herramientas acompañadas de sus correspondientes descripciones, decide si ejecutar alguna o varias de estas herramientas y con qué parámetros de llamada. El resultado de estas ejecuciones es proporcionado, junto con el input original, de nuevo al LLM, que sintetiza el resultado del proceso en un mensaje de vuelta al usuario.
Conclusión
Las técnicas de RAG permiten de una manera efectiva disponer simultáneamente de la potencia de los modelos de lenguaje y de una base de conocimiento interna sin la necesidad de costoso reentrenamiento. Como casos de uso podemos identificar apoyo al desarrollo de software a partir de documentación (LlamaIndex cuenta con un sistema de RAG para navegar y consultar su documentación de su librería), complemento para asistencia a usuarios, enriquecimiento de chatbots, gestión de sistemas de trabajo y ticket, etc.
Desplegar una aplicación de RAG requiere un trabajo preliminar de exploración y estructuración de los datos y la naturaleza de los mismos dicta qué estrategias de indexado y enriquecimiento requiere la base de datos vectorial. Estas técnicas no constituyen una solución universal a todo tipo de problemas pero se perfilan como buenos complementos de flujos de trabajo ya existentes.
Si este artículo te ha parecido interesante, te animamos a visitar la categoría Data Science para ver otros posts similares a este y a compartirlo en redes. ¡Hasta pronto!
