
En el ámbito del Machine Learning existen múltiples modelos cuya estructura interna hace que no sea trivial comprender el por qué detrás de las decisiones que toma. Este conjunto de modelos son ampliamente conocidos como modelos de caja negra y suelen disponer de una gran potencia para detectar patrones complejos en los datos. Sin embargo, presentan un comportamiento que no es transparente para el usuario, como por ejemplo, las redes neuronales.
Entender al detalle los motivos por los que un modelo ha hecho una predicción concreta o un conjunto de predicciones es un requisito cada vez más demandado en el mundo de la inteligencia artificial. Especialmente, cuando justificar dichas decisiones es un requisito legal o corporativo infranqueable debido a motivos tan importantes como la discriminación de determinados segmentos de la población.
Es en este contexto donde aparecen diferentes técnicas de explicabilidad que nos permiten arrojar luz sobre las decisiones que ha tomado nuestro modelo, de forma que sea interpretable por cualquier usuario, desde el propio científico de datos que ha desarrollado el modelo hasta el último stakeholder del proyecto.
En este post, vamos a ver desde un punto de vista teórico-práctico el uso de una técnica de explicabilidad que permite extraer conclusiones a partir de un modelo cualquiera previamente entrenado, los valores SHAP.
Tipos de explicabilidad
Este conjunto de técnicas orientadas a la explicabilidad de modelos de caja negra pueden ser clasificadas siguiendo varios criterios. El primero de ellos reside en que la técnica empleada dependa o no del modelo de machine learning utilizado. Hablaremos de técnicas agnósticas cuando dichas técnicas sean completamente independientes del modelo utilizado, pudiendo ser aplicadas en cualquier escenario. Por el lado contrario, si la técnica sólo puede ser utilizada para un modelo concreto o una familia de ellos, diremos que estamos ante una técnica específica del modelo.
Otra clasificación útil para categorizar este tipo de técnicas es la distinción entre técnicas locales y técnicas globales. Las técnicas locales son aquellas que nos permiten entender una predicción por parte de nuestro modelo de una instancia concreta. Por otro lado, las técnicas globales están orientadas a que entendamos de forma más general el efecto de las diferentes características de entrada sobre la salida del modelo.
Tras introducir el concepto de explicabilidad y conocer los diferentes tipos de técnicas para interpretar la salida de modelos de caja negra, vamos a ver en detalle una técnica de explicabilidad específica, los valores SHAP.
Valores SHAP
Los valores SHAP (SHapley Additive exPlanations) son una técnica de explicabilidad local agnóstica del modelo presentada en 2017 por Scott M. Lundberg y Su-In Lee en su paper “A Unified Approach to Interpreting Model Predictions”. Estos valores SHAP provienen de la teoría de juegos, concretamente, de la teoría detrás de medir el impacto de un subconjunto de jugadores (características de entrada a nuestro modelo) en el resultado de un juego cooperativo (la predicción final hecha por el modelo).
Para calcular estos valores SHAP, primero se selecciona una instancia o registro concreto en el dato a explicar Dichas perturbaciones. onsisten en variaciones de la instancia original en las que el valor de una o varias características ha sido reemplazado por un valor aleatorio del conjunto de datos de entrenamiento.
Posteriormente, los elementos de este nuevo conjunto de datos son ponderados utilizando una metodología compleja que da más peso a aquellas instancias en las que se han perturbado o muchas o muy pocas características, basándose en la teoría de juegos para cuantificar el valor que aportan dichos ejemplos a la interpretación final. Por último, se ajusta una regresión lineal sobre este conjunto de datos utilizando la predicción de nuestro modelo como variable objetivo, obteniendo un modelo cuyos coeficientes nos permiten entender el efecto de cada característica sobre la predicción de la instancia elegida, lo que llamamos valores SHAP.
Ejemplo práctico
Tras explicar la teoría detrás de estos valores SHAP, vamos a aplicarlos a un caso de uso real para entender un poco mejor lo que nos pueden aportar a nivel de explicabilidad. Para esto, se ha seleccionado un conjunto de datos de Kaggle, Predict Online Gaming Behavior Dataset, que captura diversas métricas y datos demográficos relacionados con el comportamiento de individuos en videojuegos en línea. En él, se presenta una variable objetivo que indica el grado en el que el juego retiene al jugador con motivo de analizar los factores que pueden influir en una dependencia extrema a los videojuegos.
Para este ejemplo práctico se filtraron algunas características del conjunto de datos y se dejaron únicamente aquellos usuarios que tenían una retención alta o baja para tratar el problema desde un punto de vista de clasificación binaria, obteniendo un dataset que posteriormente fue dividido en dos conjuntos de datos independientes, uno para entrenar el modelo y otro para evaluarlo. En la siguiente imagen se puede ver dicho conjunto de datos antes de dividirlo en dos conjuntos independientes, conformado por un total de 20.658 individuos diferentes y 7 características más la variable objetivo high_engagement.
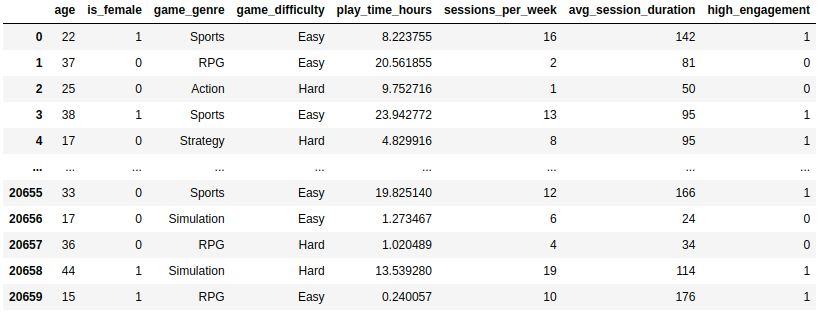
Como podemos observar, en nuestros datos disponemos de dos variables categóricas, game_genre y game_difficulty, las cuales tuvieron que ser transformadas en un conjunto de variables numéricas mediante un One Hot Encoding para poder entrenar un modelo que no maneja variables categóricas. Tras esto, se instanció y entrenó a partir de este conjunto de datos un Random Forest compuesto por 500 estimadores débiles, el cual obtuvo un accuracy del 93.44% sobre el conjunto de datos de evaluación y será el modelo cuya explicabilidad exploraremos en detalle mediante el uso de los valores SHAP.

Una vez tenemos nuestro modelo objetivo entrenado, sólo queda obtener y analizar los valores SHAP para un conjunto de instancias a explicar. En el código de la siguiente imagen se puede ver cómo seleccionamos una muestra de 500 individuos a explicar a partir del conjunto de datos de evaluación, para los cuales calculamos los valores SHAP utilizando la librería homónima. Para obtener estos valores SHAP, es necesario definir un explicador que conozca el método del modelo que genera las predicciones de salida y un conjunto de datos de entrenamiento del que obtendrá la distribución del dato para poder crear perturbaciones en la instancia a explicar.

Utilizando estos valores SHAP calculados, vamos a mostrar diversas gráficas con las que explicar el comportamiento del modelo de forma local y global. Primero, seleccionamos el primer individuo de nuestra muestra para explicar. Observamos qué ha predicho el modelo y cuál es el motivo por el que ha hecho esta predicción.
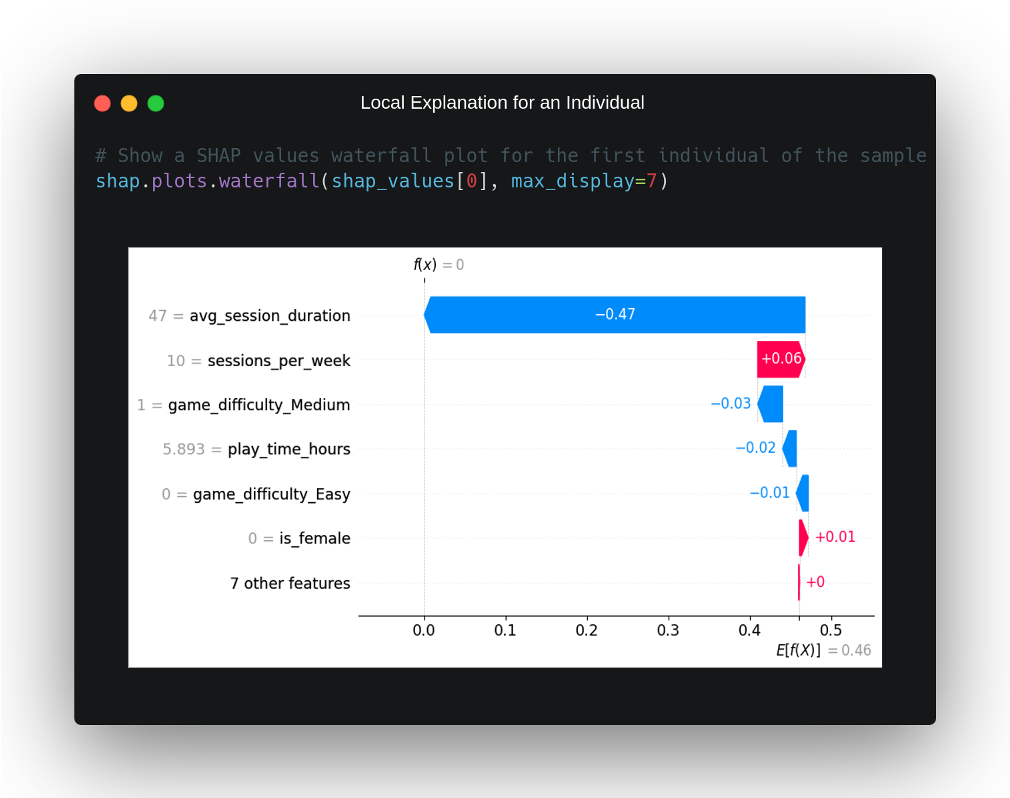
Este caso concreto pertenece a un individuo que no tiene un gran grado de retención por parte del videojuego en línea al que juega y nuestro modelo lo predice correctamente a partir de los datos de entrada. ¿Por qué ha tomado esta decisión? Para poder responder a esta pregunta, tenemos que recurrir a los valores SHAP que han sido representados para esta instancia en la gráfica en cascada de arriba. En ella, podemos ver en el eje X la probabilidad de que el modelo determine que el individuo pertenezca a la clase positiva, observando que, de promedio, dicha probabilidad es del 46%, algo normal teniendo en cuenta que el conjunto de datos está bastante balanceado.
Por otro lado, podemos observar ordenadas de mayor a menor impacto aquellas características que más peso han tenido en que el modelo tome la decisión de que esta instancia pertenece a la clase negativa. Claramente, se ve que el modelo parece haber tomado dicha decisión por una característica en concreto, la que cuantifica la duración media de sesión de juego en minutos, y que toma un valor bastante por debajo de la media del conjunto de datos, con un tiempo de 46 minutos por sesión de este individuo con respecto a los 99.43 minutos de media en el dataset de entrenamiento.
Por detrás de esta característica, vemos que la segunda con mayor impacto en la salida del modelo aportaba a dicha salida en dirección contraria, contribuyendo a que la salida de éste, en este caso, fuera perteneciente a la clase positiva. Dicha característica mide el número de sesiones de juego a la semana, y tiene un valor en este individuo de 10, lo cual está ligeramente por encima de la media del conjunto de entrenamiento. El impacto del resto de variables en este escenario no es muy significativo y, en general, no parece haber influido mucho en la salida del modelo.
Aunque los valores SHAP están considerados como una técnica de explicabilidad local, debido a que por naturaleza deben de ser calculados de forma independiente para cada una de las instancias a explicar, es posible sacar conclusiones de explicabilidad global al observar los valores SHAP de todas las instancias a explicar de forma conjunta. Para esto, la librería nos ofrece una gráfica denominada bee swarm que facilita esta labor y la cual podemos observar para el caso práctico en cuestión en la siguiente imagen:
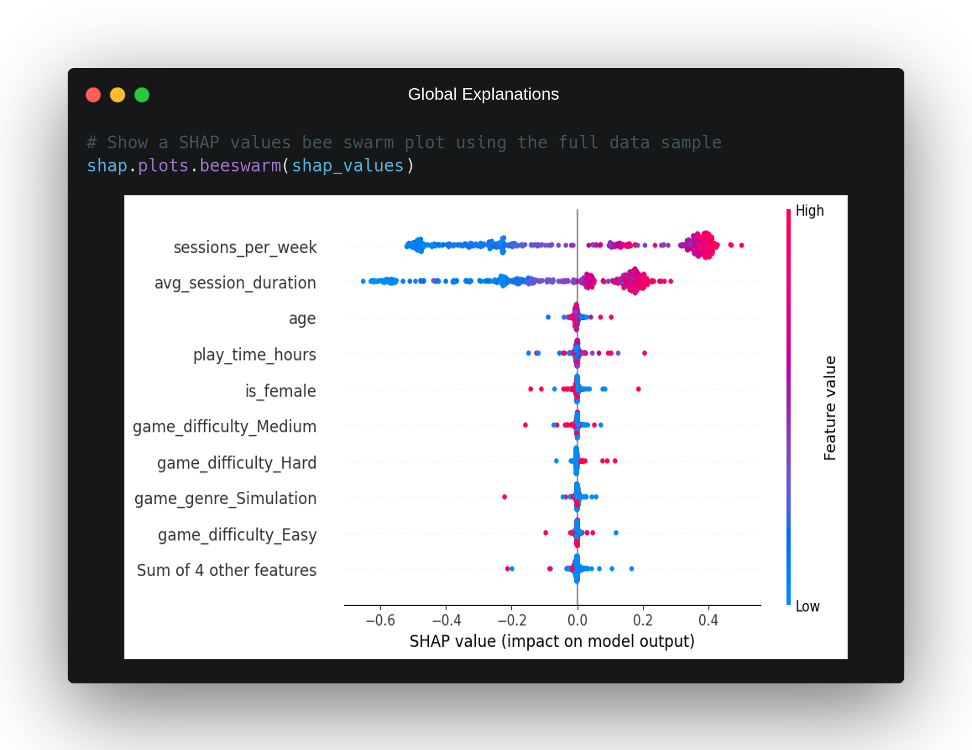
En esta gráfica, podemos ver cómo en el eje X tenemos el impacto sobre la salida del modelo de cada característica, en el eje Y las características que en promedio han tenido un mayor impacto sobre las predicciones del modelo y, por último, en un gradiente de color de rojo a azul, podemos observar para cada punto de la gráfica si se corresponde con un valor alto o bajo de dicha variable. A partir de esta representación, podemos sacar una serie de conclusiones sobre el comportamiento general del modelo:
- Existen claramente dos características que tienen un impacto en la salida del modelo mayor que el resto. El número de sesiones de juego a la semana,
sessions_per_week, y la media de la duración de dichas sesiones en minutos,avg_session_duration. Esto también está respaldado por la explicación local anterior, en la que estas dos características parecían ser las que determinaban la salida para dicho individuo. - Si nos fijamos de forma aislada en la variable
sessions_per_week, podemos ver que, normalmente, valores altos de esta variable se corresponden con un impacto hacia la clase positiva en la salida de nuestro modelo y viceversa. Además, este impacto parece ser equitativo en ambos escenarios. También se puede observar que existen algunos casos en los que valores no excesivamente altos han tenido bastante impacto en la salida del modelo. Probablemente, esto se deba a alguna interacción con alguna otra variable. - La característica
avg_session_durationse comporta de una forma similar asessions_per_week, aunque con una diferencia significativa. Los valores bajos de esta variable parecen tener mucho más impacto en la salida del modelo que los valores altos, no es tan simétrica en cuanto a su impacto dependiendo del valor. Incluso observamos que, en ciertos escenarios, esta variable tiene un impacto negativo mayor que la primera variable mencionada, pese a que, en promedio,sessions_per_weeksuele tener más impacto en la salida. - La tercera variable con mayor impacto es la relativa a la edad del individuo. Aunque como podemos ver, con un impacto promedio muchísimo menor que las otras dos características mencionadas. En la gráfica no se observa con la suficiente claridad el impacto de esta variable dependiendo de sus valores.
- El resto de variables tienen muy poco impacto en comparación en la salida del modelo en la mayoría de escenarios, aunque sí es cierto que parece que hay casos aislados en los que tienen un impacto para nada despreciable. Por ejemplo, podemos ver que cuando el juego tiene una dificultad elevada, existen varios casos en los que dicha dificultad tiene un impacto positivo de cara a predecir la clase positiva, indicando que una dificultad elevada puede influir, en ciertos casos, en la retención alta para un individuo.
Conclusión
En este post, hemos desarrollado una técnica de explicabilidad para modelos de caja negra denominada valores SHAP, analizando cómo son calculados y qué conclusiones nos permiten extraer a partir de las salidas de nuestro modelo.
Además, se ha visto un caso práctico sencillo en el que se han utilizado estos valores SHAP para analizar a nivel local y global la explicabilidad de un modelo caja negra, usando diferentes gráficas claras e intuitivas para poder sacar conclusiones efectivas.
¡Esto es todo! Si este artículo te ha parecido interesante, te animamos a visitar la categoría Data Science para ver todos los posts relacionados y a compartirlo en redes. ¡Hasta pronto!
