
En artículos anteriores de nuestro blog, hemos repasado las Novedades y mejoras de DBT 1.9 y algunos de los conceptos claves de DBT: modelos, snapshots y materializaciones.
En esta ocasión, veremos un ejemplo práctico consistente en una prueba funcional de cómo se integra la capa semántica con Google Sheets para poder realizar todo tipo de queries sobre nuestras métricas.
Capa Marts
En primer lugar, agregaremos algo de lógica de negocio para enriquecer el ejemplo. Para ello, revisaremos el código del repositorio de github y copiaremos los archivos correspondientes a la lógica de negocio.
A continuación, creamos una capa de datos llamada marts. Para realizar este proceso, añadimos una carpeta llamada marts dentro de models y copiamos los datos de la capa marts.
- models/marts/fct_orders.sql: esta tabla es de tipo «hechos». En ella, encontraremos los pedidos con la información de cada uno de ellos, como el día del pedido, el cliente o el total del coste.
- models/marts/dim_customers.sql: en esta tabla se identifica a cada cliente y se calcula su historial de compras. Se incluye la fecha de su primer y último pedido, el total de pedidos realizados y el valor total gastado. Al combinar esta información, se obtiene una visión completa de la compra de cada cliente, incluso si no han realizado ningún pedido aún.
Creación de métricas
Necesitamos agregar el paquete de dbt_utils como dependencia. En la raíz del proyecto creamos un archivo llamado packages.yml.
packages:
- package: dbt-labs/dbt_utils
version: 1.1.1Copiamos el archivo dentro de metrics en la ruta models/metrics/metricflow_time_spine.sql, que no es más que una proyección que tiene todos los días desde el 2000 hasta el 2027.
Ya tenemos todo preparado para empezar a fijar los componentes de la capa semántica. El primero que vamos a definir es fct_orders.yml y en este archivo inicializamos el modelo semántico.
models/metrics/fct_orders.ymlsemantic_models:
- name: orders
defaults:
agg_time_dimension: order_date
description: |
Order fact table. This table’s grain is one row per order
model: ref('fct_orders')En este trozo de código estamos definiendo un modelo semántico llamado orders que estructura y describe datos específicos de la tabla de hechos de pedidos fct_orders.
El modelo se basa en fct_orders (referido a través de ref('fct_orders')). La dimensión de tiempo de agregación predeterminada es order_date, es decir, las agregaciones (suma, promedio, conteo, etc.) usarán order_date como referencia temporal.
Recordemos cómo se veía el modelo fct_orders.
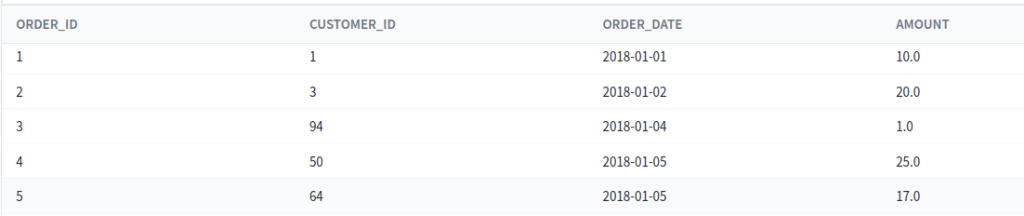
Vamos a comenzar a definir la capa semántica empezando por las entidades, que recordemos que las podemos reconocer fácilmente porque tienen un identificador propio. Encontramos order_id y customer_id, que agregaremos dentro de la categoría entities.
Las dimensiones son aquellas columnas que nos ayudan a filtrar el dato de manera más sencilla. En este caso, sería order_date, donde definimos una granularidad diaria.
Por último, definimos las medidas, que son los datos que proporcionan información a través de las agregaciones. En nuestro caso, vamos a definir un order_total con un tipo de agregación sum y que actuará sobre amount. (En el repositorio podremos encontrar alguna medida más).
entities:
- name: order_id
type: primary
- name: customer
expr: customer_id
type: foreign
dimensions:
- name: order_date
type: time
type_params:
time_granularity: day
measures:
- name: order_total
description: The total amount for each order including taxes.
agg: sum
expr: amountEl siguiente paso será añadir el bloque de métricas. Este bloque representa justamente lo que negocio necesita. Es la definición de las métricas tal y como negocio las verá y, por tanto, expresadas en un lenguaje que ellos podrán comprender.
Existen diferentes tipos de métricas que podremos configurar:
- Métricas de Conversión: rastrean eventos base y de conversión dentro de un periodo.
- Acumulativas: acumulan una medida en un periodo (requiere un modelo de fechas).
- Derivadas: realizan cálculos a partir de otras métricas.
- Simples: referencian una medida sin agregar otras.
- Métricas de Ratio: calculan la relación entre dos métricas (numerador y denominador).
metrics:
# Simple type metrics
- name: "order_total"
description: "Sum of orders value"
type: simple
label: "order_total"
type_params:
measure:
name: order_total
- name: "order_count"
description: "number of orders"
type: simple
label: "order_count"
type_params:
measure:
name: order_count
- name: large_orders
description: "Count of orders with order total over 20."
type: simple
label: "Large Orders"
type_params:
measure:
name: order_count
filter: |
{{ Metric('order_total', group_by=['order_id']) }} >= 20
# Ratio type metric
- name: "avg_order_value"
label: "avg_order_value"
description: "average value of each order"
type: ratio
type_params:
numerator: order_total
denominator: order_countAquí podemos ver la definición de algunas métricas. En el fichero original, fct_orders.yml, encontraremos más definiciones. En este punto, ya tenemos nuestra capa semántica definida, con las métricas que negocio nos ha pedido. El siguiente paso será poder proveer a negocio de herramientas sencillas para poder consultar toda esta información.
Configuración de la Capa Semántica de DBT
Para poder ejecutar y configurar la capa semántica, necesitaremos crear un Environment y un Job con una ejecución en dicho job. En el menú lateral izquierdo, accediendo a Deploy, encontraremos los dos apartados para crearlos.
El environment lo podemos crear como Staging seleccionando la conexión con Snowflake. Ya tendríamos todo lo necesario para este proceso.
El job, por su lado, no necesita de ninguna configuración especial. Lo creamos sobre nuestro environment y el comando a ejecutar puede ser el que hay por defecto, dbt build.
Por último, haciendo click en Account Settings y en nuestro proyecto, veremos un apartado para configurar la Capa Semántica. Dentro, deberemos rellenar los datos para la integración de la Capa Semántica de DBT. En este proceso, se generarán unas credenciales quedarán enlazadas con la integración que estamos configurando. No pierdas el token que se genera en este paso porque lo usaremos más adelante.
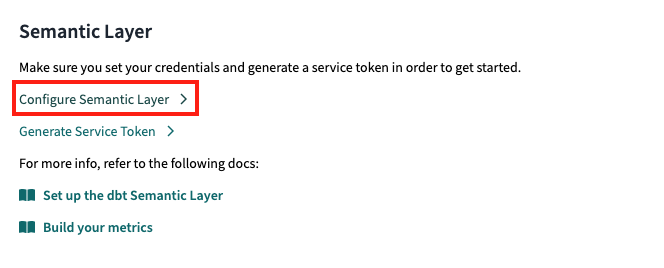
Peticiones e integración con la Capa Semántica
Si has podido llegar hasta aquí, ya has conseguido configurar todo un proyecto desde cero con la Capa Semántica de DBT. Ahora llega el turno de la explotación.
En la documentación de DBT Cloud podrás encontrar las diferentes integraciones disponibles que ofrece para esta feature. Vamos a utilizar Google Sheets para terminar nuestro caso práctico.
Abrimos un nuevo documento de Google Sheets e instalamos el complemento dbt Semantic Layer for Sheets.
En el menú de extensiones nos aparecerá el complemento instalado y lo podremos abrir.
Nos pedirá el host, el environment ID y el Service Token que hemos generado anteriormente. Dentro de nuestro proyecto, en Account Settings, encontraremos los datos necesarios.
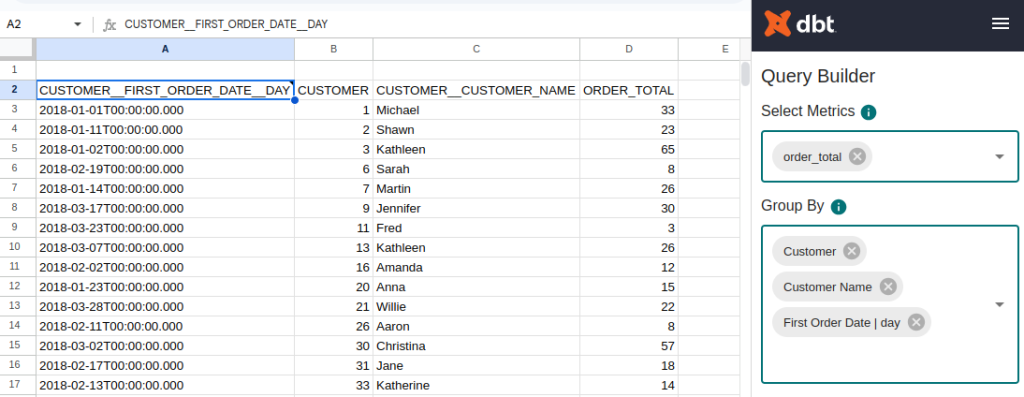
Una vez configurado, nos aparecerá la siguiente ventana que nos permite realizar queries directamente sobre las métricas establecidas en nuestra organización.
Si desplegamos las métricas, veremos que vienen definidas todas aquellas que hemos establecido en DBT Cloud. Además, podemos agrupar por las entidades y dimensiones que hemos definido en nuestro proyecto.
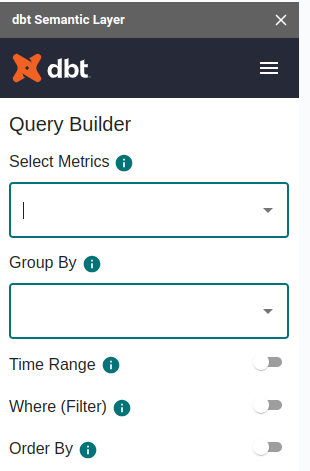
Esta capa es muy cómoda de usar para aquellos perfiles más administrativos y no técnicos, ya que siempre trabajarán sobre métricas calculadas genéricas para toda la organización.
Conclusión
En este post, hemos desarrollado un caso práctico de la Capa Semántica de DBT desde 0. Además, hemos podido ver la capacidad que tiene DBT para bajo este enfoque generar nuevas métricas unificadas. Por último, se han integrado las métricas y la API de DBT con Google Sheets, permitiendo explorar de manera práctica y sin conocimientos técnicos los datos gestionados por el equipo apropiado.
Esperamos que te haya sido útil el contenido de este post. Te recomendamos visitar la categoría Data Engineering para ver más artículos como este y te animamos a compartirlo con tus contactos para que ellos también puedan leerlos y opinar. ¡Nos vemos en redes!
