
Apache Spark Streaming es una tecnología ampliamente utilizada para el procesamiento de datos en tiempo real. En Introducción teórica a Spark Streaming pudimos conocer los conceptos clave y el funcionamiento de esta solución del ecosistema de Apache. Además, vimos algunos Ejemplos prácticos con Apache Spark Structured Streaming que nos ayudaron a implementar nuestro primer pipeline de procesamiento de datos.
En esta ocasión, analizaremos cómo trabajan Python y PySpark con las aplicaciones en streaming. Repasaremos las principales diferencias a día de hoy entre las dos APIs desde el punto de vista del tiempo real. Veremos ejemplos y explicaremos el código para que todos podamos entender y realizar nuestras pruebas con un lenguaje como Python, que está en auge y acoge a la mayoría de la comunidad de ingenieros de datos.
¿Cómo funciona Spark Streaming?
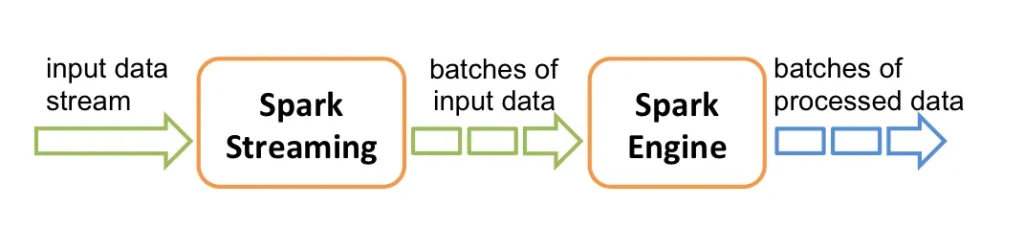
Antes de comenzar me gustaría aclarar que, cuando pensamos en streams o en tiempo real, imaginamos una cola que procesa los elementos uno por uno. Para completar la información ya analizada en otros posts, Spark Streaming recibe un input en tiempo real de los data streams y divide los datos en lotes (batches). Estos batches son procesados por el Spark Engine para generar un stream de lotes con la lógica ya aplicada.
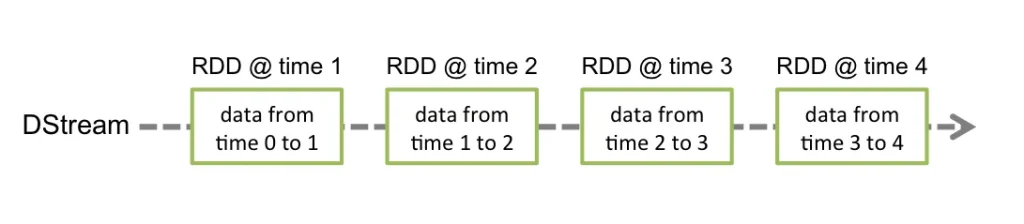
Spark Streaming se basa en una abstracción llamada discretized stream (DStream). Un DStream representa un flujo continuo de datos, que en realidad es una serie continua de RDDs. Cada RDD contiene datos correspondientes a un intervalo de tiempo específico, desde un momento hasta otro.
Spark Streaming: De StreamContext a StructuredStream
Esta, por supuesto, es la forma clásica en la que Spark trabaja con los streams. De hecho, continúa haciéndolo aunque a un nivel más bajo. Desde la versión 3.4, el uso de StreamContext (sistema para el uso directo de DStreams) ha quedado deprecado, dando paso a StructuredStream.
A continuación, analizaremos cómo se utiliza Spark Streaming en PySpark.
Ejemplo con StreamingContext
En primer lugar, empezaremos con un ejemplo de lectura de un csv en PySpark streaming.
from pyspark import SparkContext
from pyspark.streaming import StreamingContext, DStream
sc = SparkContext("local[*]", "EjemploStreamContext")
ssc = StreamingContext(sc, 1)
input:DStream[str] = ssc.socketTextStream("localhost", 9999
def transform_text(text):
return text.upper()
transformed_lines = input.map(transform_text)
transformed_lines.pprint()
ssc.start()
ssc.awaitTermination()En este caso, estamos abriendo una conexión contra un puerto en localhost. La aplicación estará escuchando dicho puerto y todo lo que envíe a él lo mostrará en pantalla pero en mayúsculas.
Para probar la aplicación, deberemos abrir una conexión de socket con dicho puerto:
nc -lk 9999Todo lo que escribamos después de ese comando se reflejará en nuestra aplicación.
En este ejemplo, vemos que input es un DStream[str]. Esto nos brinda una serie de métodos que StructuredStream no nos facilita. Algunos de los más famosos serían map, flatMap y reduceByKey. Todos ellos desaparecen al utilizar StructuredStream.
Spark Streaming con Pandas
from pathlib import Path
from pyspark.sql import SparkSession, DataFrame
from pyspark.sql.functions import avg, count
from pyspark.sql.types import StructType, IntegerType, StringType
abs = Path(__file__).resolve()
cities_path = abs.parent.parent / 'var' / 'cities'
spark = SparkSession.builder.appName("EjemploPandas").getOrCreate()
cities_schema = StructType() \
.add("LatD", IntegerType()) \
.add("LatM", IntegerType()) \
.add("LatS", IntegerType()) \
.add("NS", StringType()) \
.add("LonD", IntegerType()) \
.add("LonM", IntegerType()) \
.add("LonS", IntegerType()) \
.add("EW", StringType()) \
.add("City", StringType()) \
.add("State", StringType())
df:DataFrame = spark.readStream.option("sep", ",").option("header", "true").schema(cities_schema).csv(
str(cities_path))
def filter_func(iterator):
for pdf in iterator:
yield pdf[pdf.State == 'GA']
filtered_df = df.mapInPandas(filter_func,df.schema,barrier=True)
result = filtered_df.groupBy("State").agg(avg("LatD").alias("latm_avg"), avg("LatM").alias("latm_avg"),
avg("LatS").alias("lats_avg"), count("State").alias("count"))
query = result.writeStream.outputMode("complete").format("console").start(truncate=False
query.awaitTermination()En este caso, cargamos un csv con una estructura determinada y le aplicamos un filtrado y una agregación.
Lo más interesante es que empezamos a ver diferencias entre las APIs. Podemos observar que resaltado en color tenemos la función filter_func, que se llama mediante el método mapInPandas. Esta es una diferencia notable. Desde PySpark, a pesar de tener alguna que otra desventaja con su hermana mayor, tiene integración tanto con Pandas como con Arrow.
Esta característica puede llegar a ser útil, sobre todo si estamos en un contexto donde hay una funcionalidad que viene implementada con integración con Pandas y podemos explotar este recurso.
Con Arrow ocurre lo mismo, es posible hacer uso de la función mapInArrow. Gracias a ella, se reduce significativamente el overhead de serialización y deserialización entre Spark y Pandas. El funcionamiento vendría a ser lo mismo que mapInPandas, pero utilizando Arrow por debajo.
Ejemplo con StructuredStream
Este es probablemente el ejemplo más sencillo que podremos realizar. El código completo, incluyendo el csv leído, puedes descargarlo en el Git de Damavis.
from pathlib import Path
from pyspark.sql import SparkSession
from pyspark.sql.functions import *
abs = Path(__file__).resolve()
reader_path = abs.parent.parent / 'var' / 'lorem'
spark = SparkSession.builder.appName("EjemploStructuredStream").getOrCreate()
df:DataFrame
= spark.readStream.format("text").load(str(reader_path))
word_counts = df \
.select(explode(split(df.value, " ")).alias("word")) \
.groupBy("word").count()
query = word_counts.writeStream \
.outputMode("complete") \
.format("console") \
.start()
query.awaitTermination()En este ejemplo, estamos haciendo uso de la API StructuredStream. Esta API nos provee un objeto tipo DataFrame y aquí podemos encontrar otra diferencia con Scala. Cuando profundizamos en el método readStream que trabaja con el objeto DataStreamReader, vemos que en Scala existen ocasiones en las que en lugar de devolver un DataFrame, devuelve un Dataset. Por ejemplo, en el caso del método readStream.textFile.
Esta característica es propia de la diferencia entre lenguajes y es que Dataset no está contemplado dentro de PySpark. Esto es debido a que Python es un lenguaje de tipado dinámico y esta implementación necesita de un tipo de tipado estático, ya que se aprovecha precisamente de este tipado para realizar optimizaciones.
Conclusión
En conclusión, en este post hemos aprendido a utilizar streams en Pyspark. Después de una investigación, hemos visto las principales diferencias con respecto a la versión en Scala. También hemos podido ver ejemplos prácticos que muestran las variaciones entre las dos APIs.
A pesar de que PySpark posee ciertas limitaciones frente a Scala, (como no contar con Datasets), compensa con la flexibilidad que aporta el lenguaje. Además de ventajas como la integración con Pandas y Arrow, que hacen más fácil y eficiente trabajar con datos. Ahora queda a tu elección elegir qué lenguaje te gusta más para tus aplicaciones en streaming.
¡Esto es todo! Si este artículo te ha parecido interesante, te animamos a visitar la categoría Data Engineering para ver todos los posts relacionados y a compartirlo en redes. ¡Hasta pronto!
