
Dentro del sector hotelero, las cancelaciones son uno de los problemas más frustrantes a los que se enfrentan los Revenue Managers. Las habitaciones reservadas por huéspedes que luego no acuden suponen una pérdida de ingresos y estropean las previsiones. ¿Qué ocurriría si los hoteles pudieran predecir, con bastante exactitud, qué reservas se van a cancelar? Esta cuestión no solo es interesante desde el punto de vista académico. Además, influye en la forma en la que los hoteles deben pensar sobre los precios, el inventario y la rentabilidad.
En los Sistemas de Gestión de Ingresos (RMS), donde se toman decisiones clave sobre precios, overbooking y gestión de inventarios, esta problemática adquiere especial importancia. Estos sistemas se basan en suposiciones sobre el comportamiento de los clientes, como ya vimos en las Características esenciales en un RMS.
Sin embargo, si es probable que una reserva se cancele (y esta probabilidad no se tiene en cuenta), el RMS podría cometer fallos. Por ejemplo, infravalorar o sobrevalorar una habitación, asignar mal el inventario o perder a un cliente dispuesto a pagar mucho dinero por una habitación. Si tuvieran en cuenta el número de cancelaciones en la política de gestión de ingresos, los hoteles podrían conseguir el equilibrio perfecto entre ocupación y precio.
Técnicas para predecir cancelaciones de reservas de hotel
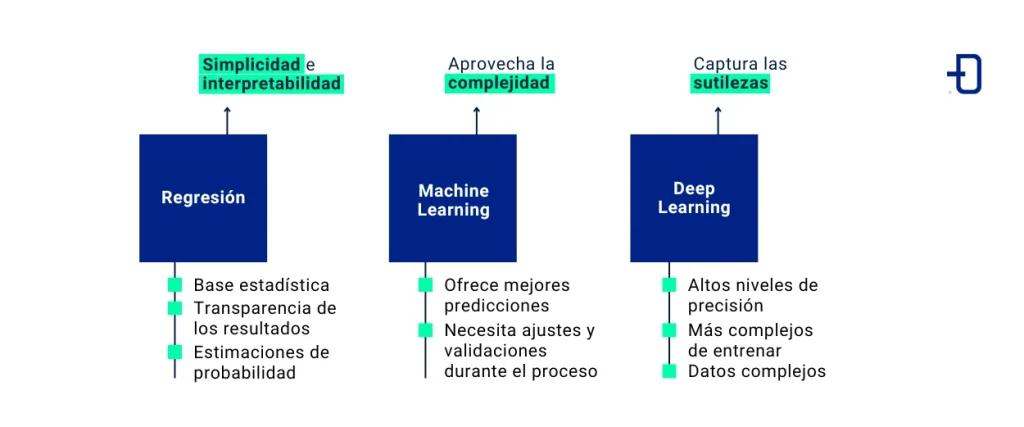
Existen distintas técnicas que los científicos de datos utilizan para predecir si un cliente cancelará una reserva. Los tres métodos principales son los modelos de Regresión, los algoritmos de Machine Learning y las redes de Deep Learning. A continuación, analizaremos cada uno de ellos y lo que aporta.
Regresión: Simplicidad e interpretabilidad
La regresión logística suele ser el primer escalón en este grupo de técnicas. Es sencilla, tiene base estadística y ofrece estimaciones de probabilidad. A partir de datos pasados (como, por ejemplo, cuándo se hizo la reserva, quién es el cliente y en qué canal se hizo), puede generar la probabilidad de que se cancele la reserva.
La ventaja de las regresiones es la transparencia de los resultados. Los hoteleros pueden interpretar de una forma muy fácil qué papel juega cada característica en la predicción final. Por ejemplo, pueden descubrir que las reservas de última hora realizadas desde dispositivos móviles tienen una mayor tasa de cancelación. Esta interpretabilidad genera confianza. Además, contribuye a que las percepciones del negocio se tengan en cuenta a la hora de elaborar modelos predictivos.
Por otro lado, la regresión también tiene sus limitaciones. Por ejemplo, asume relaciones lineales y no funciona bien con relaciones complejas entre variables. Es posible que se necesiten modelos más sofisticados para los problemas que muestran patrones no lineales y tienen una mayor dimensionalidad.
Machine Learning: Aprovechando la complejidad
Las técnicas de random forest y gradient boosting captan las no linealidades y las interacciones entre elementos sin necesidad de tanto preprocesamiento. Aprovechan un conjunto de características más amplio y rico (por ejemplo, condiciones meteorológicas, estacionalidad, eventos locales…) para generar mejores predicciones.
El aprendizaje automático suele ofrecer mejores predicciones que un simple modelo de regresión aplicado en la práctica. También se ocupa de los valores que faltan de forma más elegante y selecciona automáticamente las características importantes. Además, puede reunir un gran conjunto de datos con bastante soltura.
Existe una ventaja que merece la pena: la complejidad. Esta es una de las principales razones por las que este tipo de modelos son menos intuitivos. Es necesario ajustarlos correctamente y validarlos durante el proceso. De lo contrario, nos despediremos de todas las leyes de generalización entre diferentes segmentos de clientes y ventanas de reserva.
Deep Learning: Captura las sutilezas
Si los conjuntos de datos presentan patrones muy complejos, la alternativa es el aprendizaje profundo. Las redes neuronales pueden aprender patrones muy sutiles en el comportamiento de los huéspedes y las tendencias de las reservas. Los modelos de aprendizaje profundo no solo ingieren datos de texto conceptual de distintas fuentes. También lo hacen con historiales de estancias de los huéspedes e incluso reseñas de clientes. Todo ello, añade nuevos ángulos a la predicción de las cancelaciones.
En teoría, estos modelos son capaces de alcanzar los niveles más altos en cuanto a precisión. Sin embargo, la otra cara de la moneda es que adolecen de un grave inconveniente. Carecen de transparencia, son complejos de entrenar y, a menudo, se acercan más al terreno de la ciencia espacial (a menos que haya muchos datos y soporte de infraestructura detrás de dicho modelo). Las respuestas no solo serían más inestables. Además, son aún más difíciles de justificar en un contexto empresarial donde se busca la explicabilidad.
Esto puede resultar perjudicial para toda la ecuación del RMS. Es habitual que las decisiones de fijación de precios deban comunicarse y justificarse a las partes interesadas. Es posible que las redes neuronales puedan rechazarse categóricamente debido a su opacidad, a menos que se combinen con alguna técnica de explicabilidad.
Cómo elegir la metodología óptima
En líneas generales, no es posible elegir un enfoque de modelización como el mejor. La respuesta dependerá de las necesidades de la empresa, de los datos que posea y del riesgo que esté dispuesta a asumir. Para la mayoría de los hoteles, un modelo de gradient boosting afinado será adecuado. Si tienes interés en saber cómo funciona, aquí está todo lo que necesitas saber sobre el algoritmo Gradient Boosting.
Este modelo proporciona resultados probabilísticos útiles y comprensibles integrados en los flujos de trabajo del RMS. Además, es lo suficientemente flexible como para representar los matices del comportamiento de los huéspedes.
Sea cual sea el enfoque de modelización que se adopte, hay una verdad universal que se mantiene. Predecir las probabilidades de cancelación ya no solo se trata de un reto de la ciencia de datos, es una importantísima cuestión de negocio. En entornos en los que los márgenes son escasos y la competencia feroz, un hotel que comprenda la intención del huésped potencial en el momento de la reserva tiene una poderosa herramienta en sus manos.
Aquellos hoteles que sigan aceptando este reto, recuperarán los ingresos perdidos y tomarán mejores decisiones optimizando precios. De esta forma, lograrán ofrecer una mejor experiencia a los huéspedes.
Conclusión
La regresión, el aprendizaje automático y el aprendizaje profundo son tres de los métodos más usados por los equipos de ciencia de datos para realizar predicciones. En este post, hemos profundizado en cada uno de ellos para conocer cómo se podrían aplicar de forma práctica en la previsión de cancelaciones de reservas dentro del sector hotelero.
Si este artículo te ha parecido interesante, te animamos a visitar la categoría Data Science para ver otros posts similares a este y a compartirlo en redes. ¡Hasta pronto!
