
En el campo del Data Engineering, el diseño eficiente de bases de datos es esencial para manejar grandes volúmenes de datos y proporcionar análisis efectivos. A lo largo de mi experiencia como Data Engineer, he trabajado con los principales sistemas de relación de datos y he observado cómo los modelos de relación entre tablas juegan un papel crucial en la organización, mejorando el mantenimiento y la optimización de las consultas en nuestro Data Warehouse.
Entre los modelos más destacados se encuentran el modelo estrella, el modelo copo de nieve y el modelo galaxia. Cada uno de ellos tiene sus propias características, ventajas y desventajas, y se eligen en función de las necesidades específicas del negocio y las características de los datos.
En este post, exploraremos en detalle estos tres modelos, proporcionando una guía clara sobre cuándo debemos elegir uno u otro dependiendo de nuestras necesidades funcionales y no funcionales.
Hechos, dimensiones y normalización
Podemos dividir todos nuestros datos en dos categorías: tablas de hechos o tablas de dimensiones (maestros).
Tablas de hechos
Las tablas de hechos contienen datos sobre eventos ocurridos. Un hecho suele presentarse como un dato cuantitativo y transaccional, representando una métrica clave o una medida de negocio.
Ejemplo
En un Data Warehouse donde estemos almacenando información de facturación, la tabla invoice_line que contiene la información detallada de cada línea dentro de una factura, sería una tabla de hechos.

Vemos que es una tabla de hechos porque es una tabla transaccional, representa una medida detallada de un hecho pasado, se utiliza para la operativa de la empresa y su existencia depende de que el evento ocurra.
Tablas de dimensiones o maestras
Estas tablas son las encargadas de proporcionar un contexto descriptivo dentro de las tablas de hechos. Tienden a ser mucho más estáticas que una tabla de hechos, es decir, no crecen tanto como las tablas de hechos y se modifican poco. En la operativa de la empresa suelen ser transversales y se utilizan en diferentes contextos.
Ejemplo
En nuestro ejemplo, vemos cómo la dimensión “article” es la definición para el negocio de qué es un artículo de venta. En nuestro caso, tiene una descripción, una foto asociada, un precio, etc.

Tablas normalizadas y desnormalizadas
Cuando hablamos de tablas normalizadas nos referimos a aquellas tablas que evitan el almacenamiento de datos repetitivos.
Tabla normalizada:
| id_line | id_invoice | id_article | amount | total_price |
| line_1 | invoice_1 | article_a | 2 | 100 |
| line_2 | invoice_1 | article_b | 1 | 100 |
| line_3 | invoice_1 | article_a | 4 | 200 |
Tabla desnormalizada:
| id_line | id_invoice | article_description | article_dimensions | article_photo | amount | total_price |
| line_1 | invoice_1 | rectangle box | 100 x 200 | uri://photo_a | 2 | 100 |
| line_2 | invoice_1 | square box | 100 x 100 | uri://photo_b | 1 | 100 |
| line_3 | invoice_1 | rectangle box | 100 x 200 | uri://photo_c | 4 | 200 |
Vemos que en la tabla desnormalizada tenemos el dato repetido mientras que en la tabla normalizada todo el contexto queda relacionado mediante el id_article.
Modelos Estrella, Copo de nieve y Galaxia
Modelo Estrella
El modelo estrella es sin duda el más intuitivo y uno de los más extendidos. El nombre le viene de que morfológicamente parece una estrella cuando se plasma el modelo UML relacional de las tablas.
El sistema sigue algunas restricciones:
- En el centro de la estrella solamente puede haber una tabla de hechos.
- En los picos debemos tener tablas de tipo dimensión.
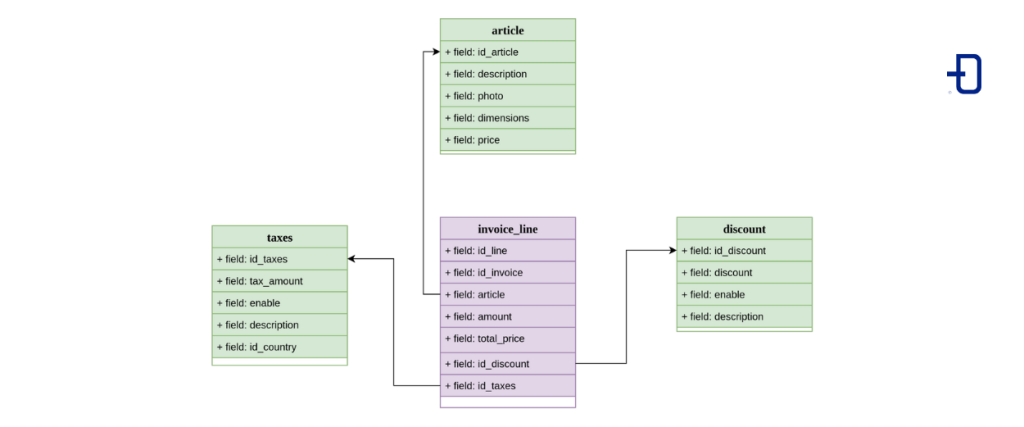
El modelo en código
SELECT
il.*, a.description, d.discount,t.tax_amount
FROM
invoice_line il
INNER JOIN article a ON a.id_article = il.id_article
INNER JOIN discount ON d.id_discount = il.id_discount
INNER JOIN taxes t ON t.taxes = il.taxesPROS
- Es el más simple de todos los modelos, esto lo hace muy fácil de integrar en la organización, ya que es fácilmente comprensible.
- Es un modelo que tiene muy buen rendimiento en las consultas, ya que solamente involucramos un salto entre los datos. Siempre hay casos en los que dichas consultas pueden involucrar una cardinalidad de datos que puede hacer que este modelo sea ineficiente, pero por lo general suelen ser muy rápidas desde el punto de vista computacional.
CONTRAS
- La escalabilidad puede ser peor, ya que existe un uso más ineficiente del almacenamiento.
- Trabajar con tablas desnormalizadas.
Modelo Copo de nieve
Este modelo es una extensión del modelo estrella, donde las dimensiones que orbitan alrededor de la tabla de hechos se relacionan con otras dimensiones, añadiendo complejidad al modelo pero también permitiendo generar un contexto más rico. Este modelo se suele utilizar en modelos analíticos OLAP; cuando se trabaja con cubos, se tiende a construir este modelo para terminar normalizando el dato en una sola tabla.
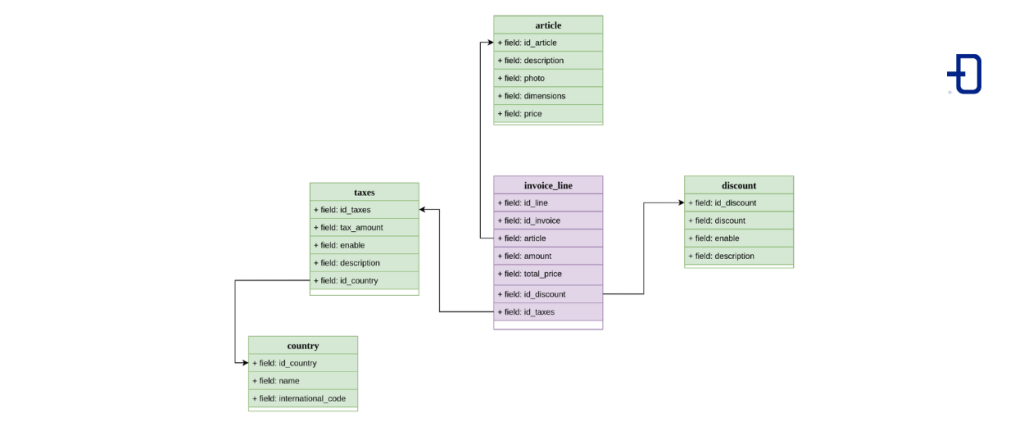
El modelo en código
SELECT
il.*, a.description, d.discount,t.tax_amount, t.tax_country
FROM
invoice_line il
INNER JOIN article a ON a.id_article = il.id_article
INNER JOIN discount ON d.id_discount = il.id_discount
INNER JOIN (
SELECT t.*,c.name as taxes_countryFROM taxes t
INNER JOIN country c ON t.id_country = c.id_country
) t ON t.id_taxes = il.id_taxesPROS
- Permite generar más contexto alrededor de una tabla de hechos.
- Trabajas con tablas normalizadas, se evita la redundancia de datos añadiendo más capas de contexto.
CONTRAS
- El código es mucho más complejo ya que pasamos a dos niveles de join a la hora de trabajar con una dimensión.
Modelo Galaxia
Por último vemos el modelo galaxia, es una extensión del modelo estrella donde encontramos que la tabla de hechos se relaciona con otra tabla de hechos nueva, la cual puede estar relacionada a su vez con más dimensiones.
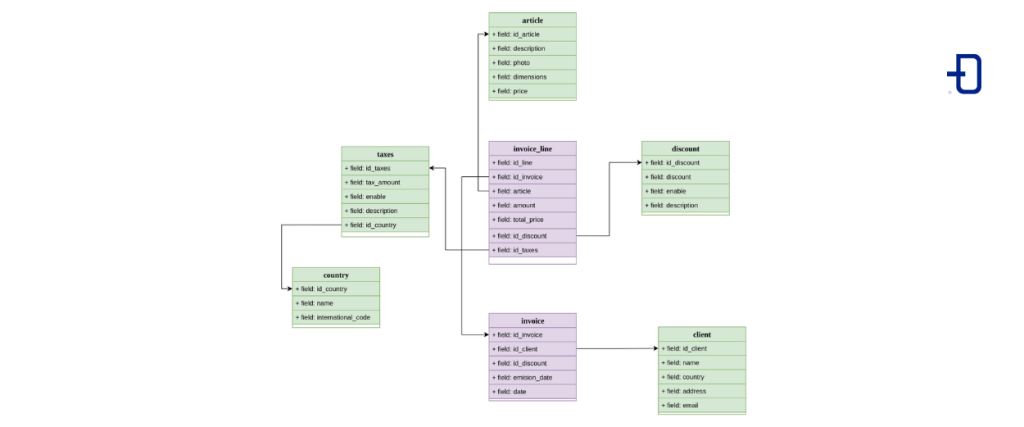
El modelo en código
SELECT
il.*, a.description, d.discount, t.tax_amount, t.tax_country, ic.client_email
FROM
invoice_line il
INNER JOIN article a ON a.id_article = il.id_article
INNER JOIN discount ON d.id_discount = il.id_discount
INNER JOIN (
SELECT t.*,c.name as taxes_countryFROM taxes t
INNER JOIN country c ON t.id_country = c.id_country
) t ON t.id_taxes = il.id_taxes
INNER JOIN (
SELECT i.*,c.email as client_email FROM invoice i
INNER JOIN clients c ON c.id_client = i.id_client
) ic ON ic.id_invoice = il.id_invoicePROS
- Permite generar un contexto mucho más rico.
CONTRAS
- Más complejidad a la hora de entender todo el modelo del Data Warehouse.
- Peor rendimiento que el modelo estrella.
Conclusión
El modelo más utilizado hoy en día en la construcción de un Data Warehouse suele ser el modelo estrella. En mi experiencia, no hay un ejercicio purista de ninguno de los modelos y, muchas veces, se termina aplicando un modelo mixto, ya que en ocasiones los beneficios de agregar niveles de profundidad en los joins son mayores que los de modificar tablas existentes durante la vida de las mismas.
Por lo general, el mayor pro de utilizar modelos como el copo de nieve y el galaxia es que ahorramos más espacio en disco, ya que tenemos menos datos repetidos. Además, el mantenimiento de las tablas de segundo orden es más sencillo. Sin embargo, este no es un gran beneficio si consideramos que el coste del almacenamiento es lo más barato hoy en día y que soluciones de Data Warehouse como Snowflake separan directamente el coste del cómputo del almacenamiento, permitiendo escalar ambos de manera independiente.
Si el tiempo de respuesta es un factor crítico para tu sistema, sin duda, un modelo estrella te ayudará.
Si este artículo te ha parecido interesante, te animamos a visitar la categoría Data Engineering para ver más posts como este y a compartirlo en redes con todos tus contactos. ¡No olvides mencionarnos (@DamavisStudio) para conocer tu opinión!
