
Una de las novedades más destacadas de Airflow 2.3.0 ha sido la llamada Dynamic Task Mapping. Esta nueva funcionalidad añade la posibilidad de crear tareas de manera dinámica en tiempo de ejecución. Gracias a esto podemos variar el número de dichas tareas en nuestro DAG en base a los datos manejados durante una ejecución.
El resultado es similar a tener un bucle for, donde para cada elemento se invoca una tarea.
Sintaxis
Para realizar el mapping simplemente hay que utilizar el método expand() de una tarea y pasarle una lista o un diccionario.
@task
def add_one(x):
return x + 1
add_one.expand(x=[1, 2, 3]) # Result: task1 -> 2, task2 -> 3, task3 -> 4También es posible establecer argumentos constantes utilizando el método partial().
@task
def add(x, n):
return x + n
add.partial(n=2).expand(x=[1, 2, 3])# Result: task1 -> 3, task2 ->4,task3-> 5Limitaciones
Actualmente, solo es posible expandir una lista o diccionario que pueden ser pasados como parámetro de entrada en nuestro DAG o como resultado de una tarea anterior que ha sido guardado en XCOM. En caso de que se pase un tipo de dato diferente, una excepción UnmappableXComTypePushed será lanzada en tiempo de ejecución.
Por otra parte, si falla una tarea dinámica todo el conjunto de tareas quedan marcadas como fallidas. Es posible que en futuras actualizaciones se añadan funcionalidades que mejoren la gestión de errores en tareas dinámicas.
Ejemplo simple
Un campo que se puede ver beneficiado del uso de esta nueva funcionalidad es el procesamiento de logs debido a su alta variabilidad. A continuación se muestra un DAG con el cual se lee un fichero de logs (generado de manera aleatoria para este ejemplo), filtra los logs con estado de error y realiza un mapping sobre este conjunto para procesar cada uno de estos en una tarea diferente:
import time
from airflow.decorators import task, dag
from datetime import datetime
from pathlib import Path
logs_file = Path("/data/dummy_logs/random_logs.log")
def get_process_id(line: str) -> str:
return line.split(" ")[-1]
@dag(start_date=datetime(2022, 5, 16),
schedule_interval="@daily",
dag_id="repair_components_dummy",
catchup=False)
def my_dag():
@task
def get_failed_processes(log_file: Path) -> list[str]:
failed_processes = []
with open(log_file, 'r') as f:
for line in f:
if line.startswith("ERROR"):
failed_processes.append(get_process_id(line))
return failed_processes
@task
def repair_process(process_id: str):
time.sleep(0.5) # Simulate computation time
print(f"process {process_id} repaired")
repair_process.expand(process_id=get_failed_processes(logs_file))
repair_logs_dummy = my_dag()MapReduce
Crear mapeos para distribuir tareas y permitir su ejecución en paralelo es muy potente, pero si además encadenamos los nodos generados dinámicamente a otro podemos realizar operaciones map reduce. Para ello, simplemente se necesita que la tarea posterior al mapeo tenga como argumentos una lista o diccionario que se ajuste a la salida de las tareas mapeadas.
Ejemplo de MapReduce
En el siguiente ejemplo mostraremos un DAG para contar el número de mensajes de error en varios ficheros de logs. Cada uno de estos ficheros se debe de procesar en una tarea diferente para poder obtener el máximo paralelismo posible.
Para ello, la primera tarea devuelve una lista con los elementos de una carpeta de logs, después se crea de manera dinámica una tarea para cada uno de estos ficheros que se encargan de contar el número de logs de error para su respectiva entrada y finalmente una tarea utiliza la operación suma para reducir los resultados de las tareas dinámicas anteriores.
import time
import glob
from airflow.decorators import task, dag
from datetime import datetime
from pathlib import Path
logs_folder = Path("/data/dummy_logs/random_logs")
def get_process_id(line: str) -> str:
return line.split(" ")[-1]
@dag(start_date=datetime(2022, 5, 16),
schedule_interval="@daily",
dag_id="map_reduce_logs_dummy",
catchup=False)
def my_dag():
@task
def get_log_files(log_folder: Path | str) -> list[str]:
return glob.glob(str(log_folder) + "/*")
@task
def get_num_of_failed_processes(log_file: str) -> int:
failed_processes = 0
with open(log_file, 'r') as f:
for line in f:
time.sleep(0.05) # Simulate computation time
if line.startswith("ERROR"):
failed_processes += 1
return failed_processes
@task
def sum_processes(n: list[int]):
print(sum(n))
sum_processes(get_num_of_failed_processes.expand(log_file=get_log_files(logs_folder)))
repair_logs_dummy = my_dag()Interfaz gráfica
En la vista de cuadrícula (la vista de árbol ha sido eliminada en Airflow 2.3.0) las tareas dinámicas se ven como si se tratase de una sola tarea, aunque su nombre aparece con dos corchetes:
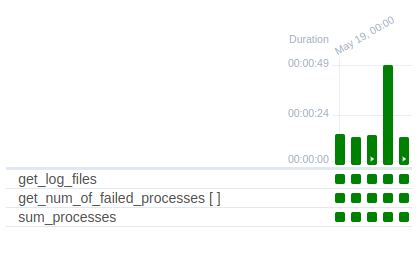
Por otra parte, en la vista de grafo también se ve como una sola tarea. Sin embargo, si se ha ejecutado correctamente, se pueden observar el número de tareas dinámicas que han sido ejecutadas.

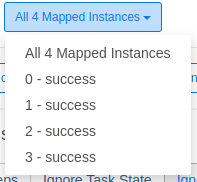
Si seleccionamos la tarea dinámica, nos aparece un desplegable para seleccionar la tarea concreta para obtener detalles de esta.
Parámetros de configuración
Se pueden limitar ciertas funcionalidades del mapeo dinámico modificando los siguientes parámetros en el archivo de configuración de airflow:
- max_map_length: Máximo número de tareas que el método expand puede crear.
- max_active_tis_per_dag: Número máximo de tareas en paralelo creadas por una misma llamada a
expand().
Conclusión
En conclusión, el mapeo de tareas dinámico introducido en Airflow 2.3.0 nos permite crear tareas en tiempo de ejecución para poder adaptar nuestro DAG a entornos con entradas variables como podría ser el procesamiento de logs. Además, al combinarlo con una operación de reducción, se pueden crear grafos que sigan el modelo MapReduce de manera sencilla pudiendo así ejecutar tareas de forma paralela.
Videotutorial
Echa un vistazo al videotutorial en nuestro canal de YouTube:
Si te ha parecido interesante este artículo, te animamos a que visites la categoría de Software de nuestro blog para ver posts similares a este y a que lo compartas en redes con todos tus contactos. No olvides mencionarnos para hacernos llegar tu opinión @Damavisstudio. ¡Hasta pronto!
