
A través de distintas entradas de nuestro blog, hemos analizado qué son y cómo funcionan los grafos desde una perspectiva tanto teórica como práctica. En el post Bases de datos de grafos: Análisis y ejemplos ya abordamos cómo esta tecnología es capaz de modelar relaciones que serían una misión imposible si utilizamos SQL clásico.
Cuando hablamos de bases de datos de grafos, lo habitual es que las opciones se limiten a Neo4J. Sin embargo, BigQuery ha añadido recientemente en Preview la compatibilidad para tratar grafos, lo cual supone un importante hito en el uso de esta tecnología.
A lo largo de este artículo, exploraremos esta nueva funcionalidad y veremos cómo funciona mediante un ejemplo práctico.
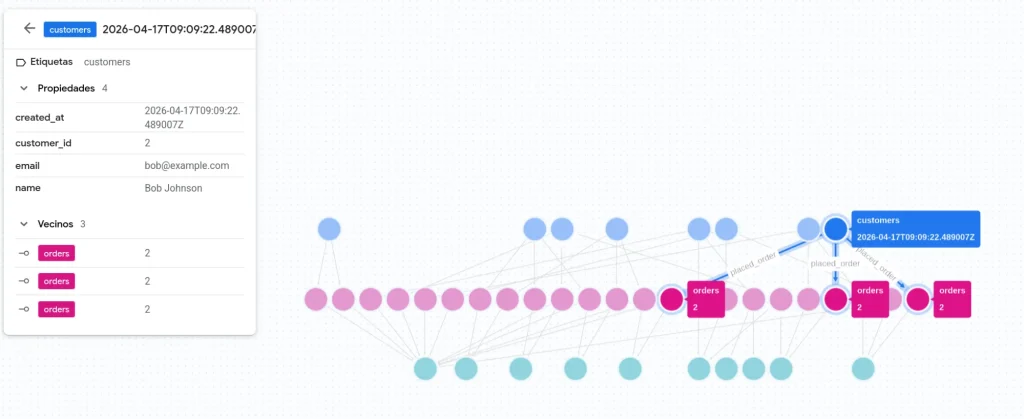
Cómo funciona la visualización de grafos en BigQuery
En primer lugar, generaremos unos datos de ejemplo para mostar el funcionamiento de esta herramienta. Para ello, usaremos la siguiente consulta en BigQuery:
CREATE OR REPLACE TABLE `graph_testing.customers` (
customer_id INT64 NOT NULL,
name STRING,
email STRING,
created_at TIMESTAMP,
PRIMARY KEY (customer_id) NOT ENFORCED
);
CREATE OR REPLACE TABLE `graph_testing.items` (
item_id INT64 NOT NULL,
product_name STRING,
unit_price FLOAT64,
PRIMARY KEY (item_id) NOT ENFORCED
);
CREATE OR REPLACE TABLE `graph_testing.orders` (
order_id INT64 NOT NULL,
customer_id INT64,
order_date TIMESTAMP,
total_amount FLOAT64,
PRIMARY KEY (order_id) NOT ENFORCED,
FOREIGN KEY (customer_id)
REFERENCES `graph_testing.customers` (customer_id) NOT ENFORCED
);
CREATE OR REPLACE TABLE `graph_testing.order_items` (
order_item_id INT64 NOT NULL,
order_id INT64,
item_id INT64,
quantity INT64,
price FLOAT64,
PRIMARY KEY (order_item_id) NOT ENFORCED,
FOREIGN KEY (order_id)
REFERENCES `graph_testing.orders` (order_id) NOT ENFORCED,
FOREIGN KEY (item_id)
REFERENCES `graph_testing.items` (item_id) NOT ENFORCED
);
INSERT INTO `graph_testing.customers` VALUES
(1,'Alice Smith','alice@example.com',CURRENT_TIMESTAMP()),
(2,'Bob Johnson','bob@example.com',CURRENT_TIMESTAMP()),
(3,'Charlie Brown','charlie@example.com',CURRENT_TIMESTAMP()),
(4,'Diana Prince','diana@example.com',CURRENT_TIMESTAMP()),
(5,'Ethan Hunt','ethan@example.com',CURRENT_TIMESTAMP()),
(6,'Fiona Gallagher','fiona@example.com',CURRENT_TIMESTAMP()),
(7,'George Martin','george@example.com',CURRENT_TIMESTAMP()),
(8,'Hannah Baker','hannah@example.com',CURRENT_TIMESTAMP()),
(9,'Ian Malcolm','ian@example.com',CURRENT_TIMESTAMP()),
(10,'Julia Roberts','julia@example.com',CURRENT_TIMESTAMP());
INSERT INTO `graph_testing.items` VALUES
(1,'Laptop',1200),
(2,'Mouse',25),
(3,'Keyboard',75),
(4,'Monitor',200),
(5,'Desk',300),
(6,'Chair',150),
(7,'Headphones',90),
(8,'Printer',120),
(9,'Smartphone',800),
(10,'Tablet',400);
INSERT INTO `graph_testing.orders` VALUES
(101,1,CURRENT_TIMESTAMP(),120),(102,1,CURRENT_TIMESTAMP(),80),(103,1,CURRENT_TIMESTAMP(),45),
(104,2,CURRENT_TIMESTAMP(),75),(105,2,CURRENT_TIMESTAMP(),150),(106,2,CURRENT_TIMESTAMP(),85),
(107,3,CURRENT_TIMESTAMP(),200),(108,3,CURRENT_TIMESTAMP(),50),(109,3,CURRENT_TIMESTAMP(),60),
(110,4,CURRENT_TIMESTAMP(),50),(111,4,CURRENT_TIMESTAMP(),90),(112,4,CURRENT_TIMESTAMP(),140),
(113,5,CURRENT_TIMESTAMP(),300),(114,5,CURRENT_TIMESTAMP(),40),(115,5,CURRENT_TIMESTAMP(),210),
(116,6,CURRENT_TIMESTAMP(),180),(117,6,CURRENT_TIMESTAMP(),60),(118,6,CURRENT_TIMESTAMP(),35),
(119,7,CURRENT_TIMESTAMP(),90),(120,7,CURRENT_TIMESTAMP(),110),(121,7,CURRENT_TIMESTAMP(),400),
(122,8,CURRENT_TIMESTAMP(),60),(123,8,CURRENT_TIMESTAMP(),130),(124,8,CURRENT_TIMESTAMP(),55),
(125,9,CURRENT_TIMESTAMP(),500),(126,9,CURRENT_TIMESTAMP(),75),(127,9,CURRENT_TIMESTAMP(),75),
(128,10,CURRENT_TIMESTAMP(),220),(129,10,CURRENT_TIMESTAMP(),95),(130,10,CURRENT_TIMESTAMP(),180);
INSERT INTO `graph_testing.order_items` VALUES
(1001,101,1,1,1200),(1002,101,2,1,25),
(1003,102,2,2,25),
(1004,103,3,1,75),
(1005,104,3,1,75),(1006,104,2,1,25),
(1007,105,4,1,200),(1008,105,2,2,25),
(1009,106,7,1,90),
(1010,107,5,1,300),(1011,107,6,1,150),
(1012,108,2,1,25),
(1013,109,10,1,400),
(1014,110,2,2,25),
(1015,111,7,1,90),(1016,111,3,1,75),
(1017,112,4,1,200),
(1018,113,6,2,150),
(1019,114,2,1,25),
(1020,115,5,1,300),(1021,115,2,1,25),
(1022,116,10,1,400),
(1023,117,2,3,25),
(1024,118,3,1,75),
(1025,119,8,1,120),
(1026,120,4,1,200),(1027,120,2,1,25),
(1028,121,1,1,1200),
(1029,122,2,2,25),
(1030,123,7,1,90),
(1031,124,3,1,75),
(1032,125,1,1,1200),(1033,125,2,1,25),
(1034,126,8,1,120),
(1035,127,9,1,800),
(1036,128,9,1,800),(1037,128,2,1,25),
(1038,129,2,2,25),
(1039,130,10,1,400),(1040,130,7,1,90);
CREATE OR REPLACE TABLE `graph_testing.placed_orders` (
source_customer_id INT64,
destination_order_id INT64,
order_date TIMESTAMP,
total_amount FLOAT64,
PRIMARY KEY (destination_order_id) NOT ENFORCE
) AS
SELECT
customer_id AS source_customer_id,
order_id AS destination_order_id,
order_date,
total_amount
FROM `graph_testing.orders`;Como apunte de interés, las tablas han de tener definida una clave primaria con PRIMARY_KEY. De lo contrario, no podrán ser utilizadas para definir el grafo.
De esta manera, crearemos un total de cinco tablas. Tres de ellas representan nodos en el grafo Customers, Orders e Items. Por otra parte, dos son tablas puente que enlazan elementos: Order Items enlaza Orders con Items y Placed Orders que une Customer con Orders.
Si observamos la forma de este grafo, es la misma que la del grafo de ejemplo mostrado en la primera imagen del post, pero enriquecido con más datos.
Cómo crear un grafo de propiedades en BigQuery
Crear un grafo de propiedades requiere definir el grafo, sus nodos y sus aristas. Cada uno de los elementos está representado por una tabla en BigQuery.
Para definir nuestro grafo, indicamos los nodos de Customers, Orders e Items y las aristas de Placed Orders, que enlaza Customers con Orders y Contains Items, que une Orders con Items.
Por otra parte, es necesario indicar para cada tabla nodo una tabla arista que contiene la ID de cada nodo al que enlaza. Si no existe la tabla arista, no hay conexión entre los nodos.
CREATE OR REPLACE PROPERTY GRAPH `graph_testing.commerce` --Nombre grafo
--Tablas nodo
NODE TABLES (
`graph_testing.customers` LABEL customers,
`graph_testing.orders` LABEL orders,
`graph_testing.items` LABEL items
)
--Tablas arista
EDGE TABLES
(`graph_testing.placed_orders`
SOURCE KEY (source_customer_id) REFERENCES `graph_testing.customers` (customer_id)
DESTINATION KEY (destination_order_id) REFERENCES `graph_testing.orders` (order_id)
LABEL placed_order,
`graph_testing.order_items`
SOURCE KEY (order_id) REFERENCES `graph_testing.orders` (order_id)
DESTINATION KEY (order_item_id) REFERENCES `graph_testing.items`(item_id)
LABEL contains_items
);Graph Query Language
El lenguaje que se usa para las queries es Graph Query Language (GQL). Es un lenguaje muy similar a Cypher (el que usamos en el artículo mencionado anteriormente), así que no profundizaremos en cómo funciona para definir matches.
SELECT DISTINCT customer_id, name
FROM GRAPH_TABLE(
`reportingonline-dev.graph_testing.commerce`
MATCH (c:customers)-[:placed_order]-(o:orders)
-[:contains_items]-(i:items)
COLUMNS (c.customer_id, c.name, o.order_id, i.item_id)
)
GROUP BY customer_id, name, order_id
HAVING COUNT(*)>1En esta query de ejemplo, se obtienen todos los Customer que tienen un pedido o más con más de un elemento. Si ejecutamos dicha query, obtendremos:
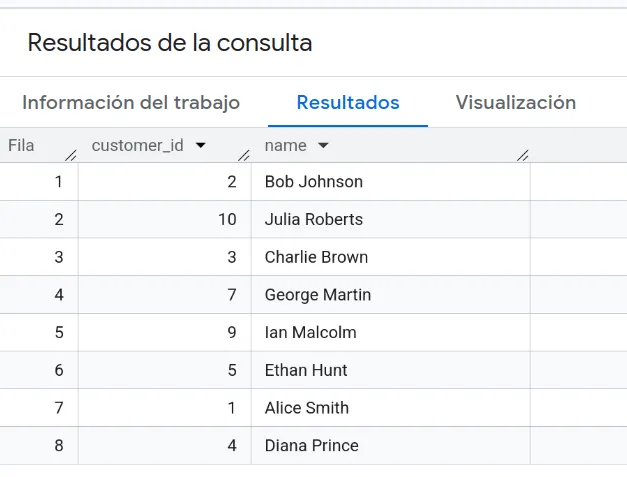
Además, si queremos visualizar el resultado de una consulta, BigQuery implementa un visualizador automático.
GRAPH `reportingonline-dev.graph_testing.commerce`
MATCH p =(c1:customers)-[:placed_order]-(o1:orders)
-[:contains_items]-(i:items)
RETURN
TO_JSON(p) AS path LIMIT 10;Si ejecutamos este código, obtendremos el siguiente resultado:
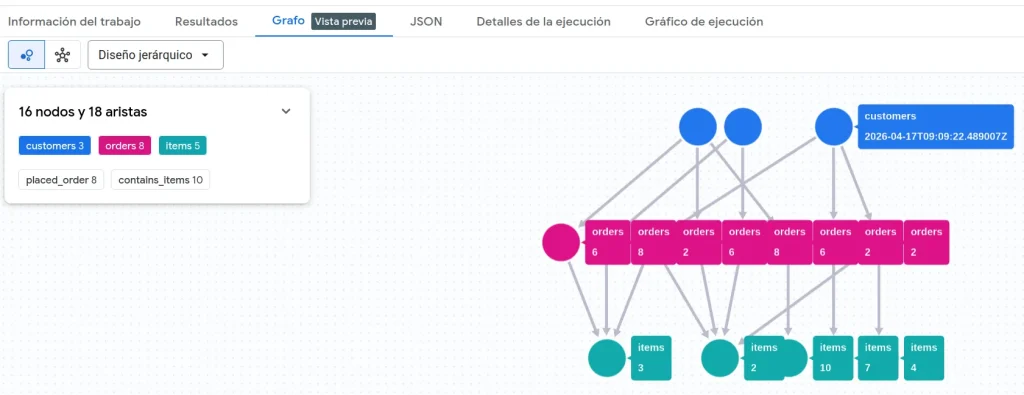
Conclusión
Con el nuevo soporte añadido a grafos de propiedades que BigQuery ha desarrollado, será posible expandir los análisis que podemos hacer sobre los datos en esta misma plataforma. Esto nos permitirá incrementar la cantidad de conocimiento que podemos obtener de los datos con poca fricción.
Si este artículo te ha parecido interesante, te animamos a visitar la categoría Data Engineering para ver otros posts similares a este y a compartirlo en redes. ¡Hasta pronto!
