
La API Structured Streaming de Apache Spark es una poderosa herramienta para procesar flujos de datos en tiempo real. En este contexto, existen ciertos casos de uso en los que asegurar la exactitud del dato procesado no es trivial debido a la dimensión temporal que afecta inherentemente a un flujo de datos en streaming, por lo que resulta necesario disponer de herramientas que nos permitan controlar y gestionar los tiempos de manera eficiente.
En este post, se explorarán las herramientas de las que la API dispone y los conceptos relacionados con ellas que ofrece esta API.
Además, veremos algunas de las mejoras que se han incorporado tras la aparición de las nuevas versiones de Apache Spark.
Gestión de tiempos con Structured Streaming
En el procesamiento de datos en tiempo real cabe diferenciar entre tiempo del evento (cuándo el evento realmente ocurrió, típicamente una marca temporal en el mismo dato) y el tiempo de procesado (cuándo el evento es procesado por el sistema). En el mundo real, los eventos pueden llegar a procesarse con retraso o de manera desordenada por causas relacionadas con la localización de los centros de datos o con diferencias en las conexiones a través de las cuales se publican los eventos, por poner algunos ejemplos.
Operando únicamente según el tiempo de procesado, estas contingencias son susceptibles de desvirtuar métricas y agregaciones si lo que se desea es obtenerlas a nivel de tiempo del evento. Una mejora adicional de la API Structured Streaming con respecto de la API DStream es que permite precisamente eso: señalando un campo del dato como tiempo del evento y definiendo una watermark, pueden efectuarse con precisión cálculos como agregaciones por ventanas temporales.
Qué son las watermarks en Spark
Las watermarks son un mecanismo que permite a Spark limpiar datos antiguos almacenados en un estado interno y que ya no se consideran relevantes para las agregaciones basadas en ventanas temporales. Esto es útil para manejar datos que han entrado con retraso de manera eficiente sin acumular un estado innecesariamente grande. Visto desde otro punto de vista, debido al retraso o el desorden con el que entran los datos en el sistema, si van a procesarse los datos en función del tiempo del evento, Spark necesita algún mecanismo para decidir cuándo puede dar una agregación por concluida.
Por ejemplo, imaginemos un caso en el que están entrando eventos con una marca temporal (timestamp) y una clave (key). Se ha decidido (1) desechar todo el dato que entre con más de 10 minutos de retraso (o, lo que es lo mismo, definir una watermark de 10 minutos) y (2) se tiene que agrupar el dato según la clave y en ventanas fijas de 10 minutos con el fin de contar el número de eventos en cada ventana de tiempo.
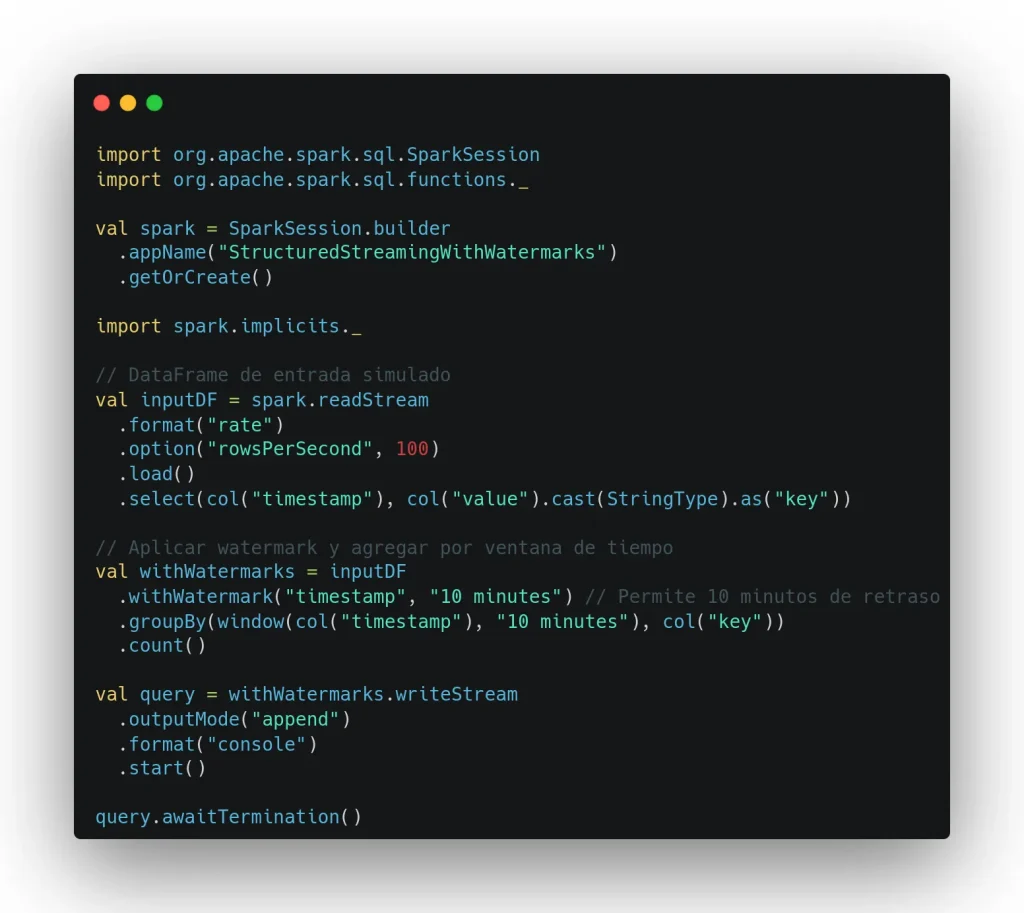
Por definición, las watermarks ofrecen garantías de agregación en una sola dirección. Esto quiere decir que, dada una watermark de 10 minutos, se garantiza que se procesará todo evento con un retraso de menos de 10 minutos. Sin embargo, no se garantiza que dejarán de procesarse los eventos que lleguen con más de 10 minutos de retraso.
Watermarks y deduplicación
En general, el concepto de watermarks no ha evolucionado de manera significativa a lo largo del tiempo. No obstante, y dado que este post originalmente fue publicado hace unos años, añadiremos una pequeña actualización a fecha de 2026 para hablar de esta funcionalidad en las nuevas versiones de Spark.
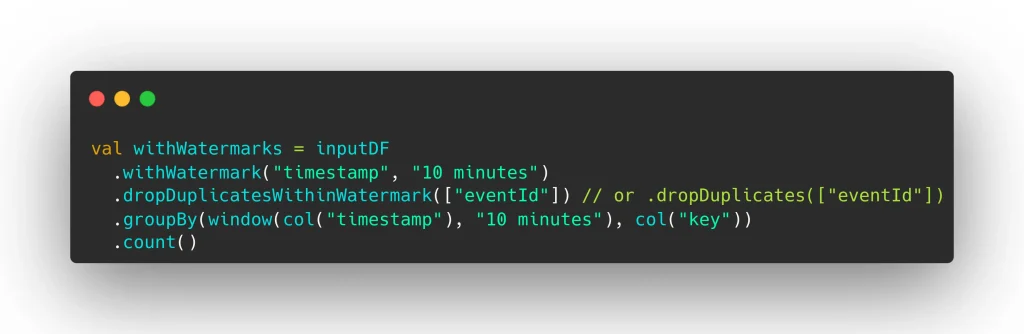
Desde Spark 3.5, es un patrón muy común añadir un método de deduplicación inmediatamente después de establecer la watermark.
Usando el método .dropDuplicates, Spark descarta registros repetidos de acuerdo con un estado global sin límite. No se recomienda esta aproximación para tareas de duración indeterminada debido a que el estado puede crecer hasta causar problemas de memoria. La alternativa en estos casos es usar .dropDuplicatesWithinWatermark. De esta manera, se descartan registros duplicados hasta el momento en que expira la watermark, tras lo cual la referencia se elimina del estado.
Agregaciones con watermarks y ventanas temporales
Las ventanas temporales permiten agrupar datos en intervalos de tiempo para realizar agregaciones como conteos, sumas, promedios, etc.

Existen tres tipos de ventanas:
- Ventanas de desplazamiento (Tumbling Windows): Ventanas de tiempo fijas y no solapadas, como en el ejemplo anterior. Estas ventanas son siempre fracciones de tiempo puntuales (00:00-00:10, 00:10-00:20, 00:20-00:30, etc.).
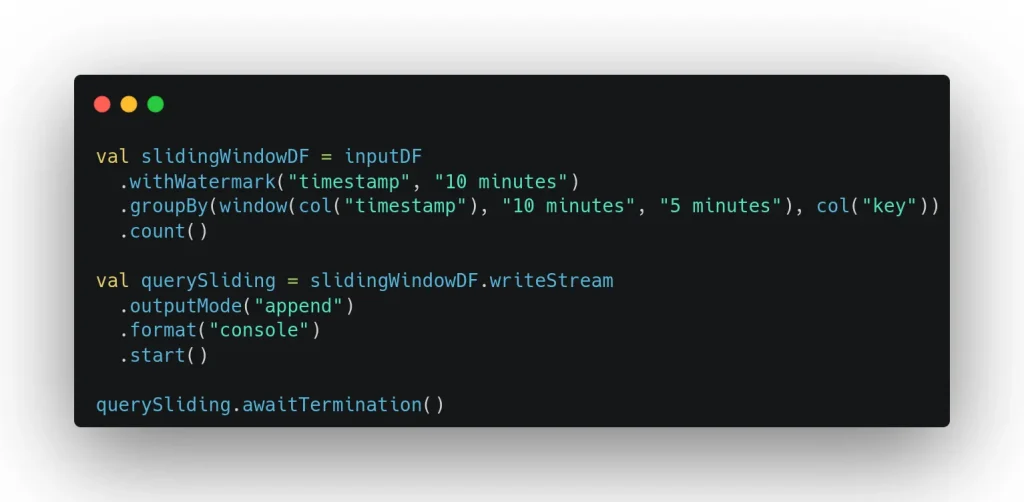
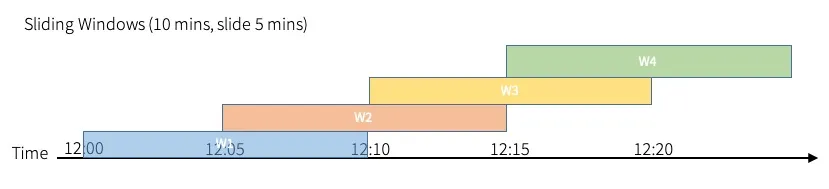
- Ventanas deslizantes (Sliding Windows): Ventanas de tiempo como las de desplazamiento, pero que se solapan.
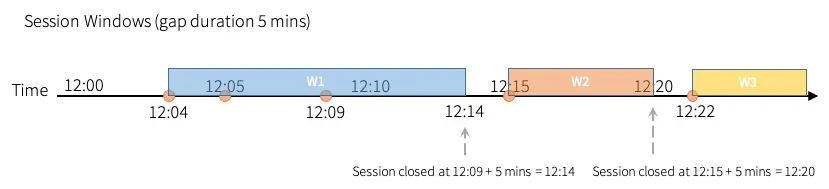
- Ventanas de sesión (Session Windows): Ventanas que se basan en la actividad de los eventos y pueden ajustarse dinámicamente.
Con la misma lectura en streaming que en el ejemplo anterior, en el siguiente se crean ventanas de 10 minutos que se solapan cada 5 minutos, lo que permite capturar eventos que podrían estar repartidos a través de múltiples ventanas fijas.
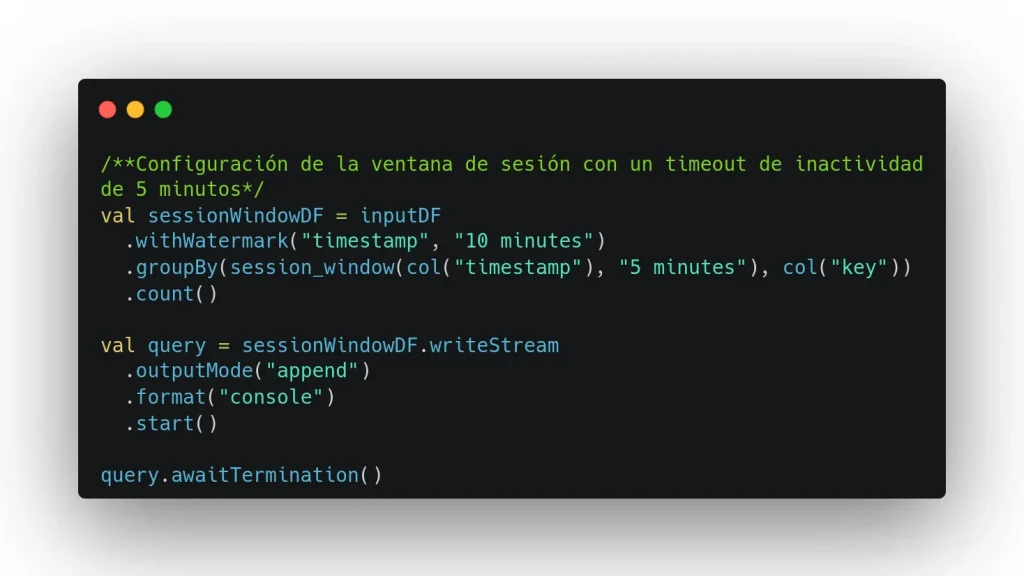
Otra vez con el mismo ejemplo para la lectura, este puede entenderse como un flujo de eventos que representan interacciones de un usuario. Se agrupan los eventos en sesiones basadas en su actividad con una duración máxima de 10 minutos con un tiempo de inactividad máximo (timeout) de 5 minutos. Esto significa que, iniciada una sesión, esta durará 10 minutos a no ser que, dentro de esos 10 minutos desde el inicio, se produzca un periodo de inactividad de más de 5 minutos.
Unión de datos y watermarks
La unión de eventos mediante operaciones de tipo join puede efectuarse con limitaciones. No hay ninguna unión Stream-Estático que permita manejar estados, así que las watermarks no tienen ningún sentido en este contexto. Sin embargo, sí que lo tienen en uniones Stream-Stream.
En las uniones Stream-Stream, además de poder definir una watermark para cada flujo de datos, es interesante establecer un tercer factor temporal relacionado con la diferencia temporal con que entran dos registros que van a hacer match. Es en este sentido que se habla de restricción temporal o retraso máximo.
En estos casos, el procedimiento es el siguiente:
- Se definen ambas lecturas en streaming con sus propias watermarks. En algunos casos puede ser opcional.
- Para el conjunto de eventos a emparejar, se decide qué retraso máximo se permite entre la llegada por uno y otro lado. Es siempre recomendable, cuando no obligatorio.
- Se unen los registros, con las limitaciones siguientes:
- Para las uniones en modo Inner, las watermarks son opcionales y se recomienda definir un retraso máximo para limpiar el estado.
- Para el resto de uniones, la watermark es obligatoria por el lado contrario a la definición del modo (izquierda para Right Outer, derecha para Left Semi, etc.) y opcional, aunque recomendado para el otro, para limpiar completamente el estado. El retraso máximo es siempre obligatorio. Para el modo Full Outer los requisitos son idénticos, siendo cualquiera de los lados el obligatorio.
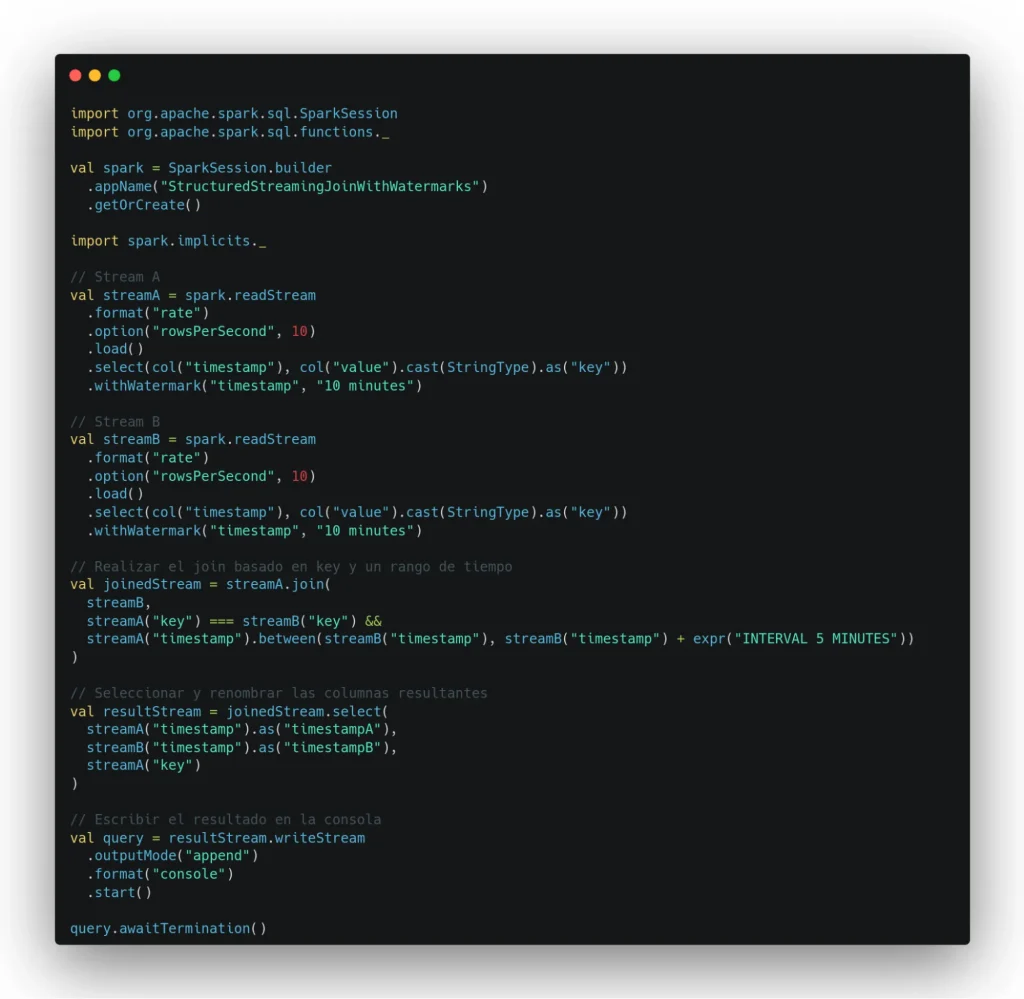
En este ejemplo se unen dos flujos de datos con una watermark de 10 minutos cada uno, con un retraso máximo de 5 minutos entre emparejamientos.
Novedades en la versión 2.4
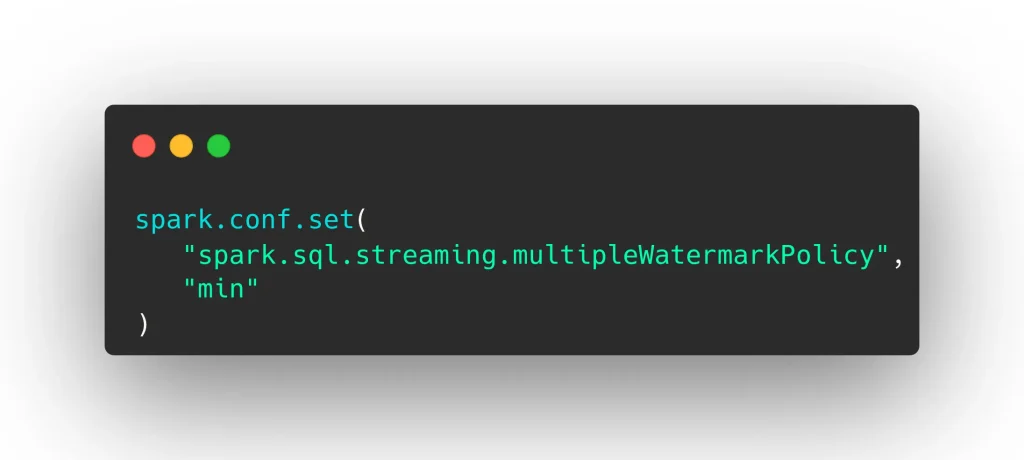
Desde Apache Spark 2.4, al gestionar múltiples fuentes con watermarks o uniones stream-stream, Spark combina los watermarks en una política global para limpiar el estado.
El valor min es el valor por defecto y que garantiza mayor consistencia. Sin embargo, también implica mantener un estado más grande. Por su parte, max permite mayor velocidad pero entraña mayor riesgo de pérdida de datos.
Modos de escritura y watermarks
De los tres modos de escritura posibles en Spark, solamente pueden usarse watermarks con dos de ellos: append y update. Para el tercer modo, complete, no tiene sentido porque requiere guardar todas las agregaciones sin posibilidad de eliminar los estados intermedios.
Usando el modo append, cada agregado se escribe una sola vez. Esto implica que solo va a escribir las agregaciones una vez que haya empezado a recibir eventos con una marca temporal de evento posterior al cierre de la ventana más el tiempo de la watermark. Tras escribir, se borra el estado de esa ventana. Los eventos pertenecientes a ella que entrasen posteriormente, potencialmente se ignorarían.
Con el modo update los agregados se producen con cada ingesta de datos. Aunque la watermark no es necesaria para producir el output, su importancia radica en que borra los estados de las ventanas cerradas con el mismo criterio que con el modo append.
Véase el siguiente ejemplo para observar la escritura en cada modo para ventanas fijas de 10 minutos donde la agregación es un sencillo recuento de los eventos.
| Tiempo procesado | Tiempo del evento | Valor | Escritura (append) | Escritura (update) |
| 01:02 | 01:01 | 1 | 01:00-01:10 -> 1 | |
| 01:04 | 01:02 | 1 | 01:00-01:10 -> 2 | |
| 01:09 | 01:07 | 1 | 01:00-01:10 -> 3 | |
| 01:11 | 01:09 | 1 | 01:00-01:10 -> 4 | |
| 01:13 | 01:11 | 1 | 01:00-01:10 -> 4 01:10-01:20 -> 1 | |
| 01:18 | 01:09 | 1 | 01:00-01:10 -> 5 01:10-01:20 -> 1 | |
| 01:21 | 01:17 | 1 | 01:00-01:10 -> 5 01:10-01:20 -> 2 | |
| 01:22 | 01:21 | 1 | 01:00-01:10 -> 5 | 01:00-01:10 -> 5 01:10-01:20 -> 2 01:20-01:30 -> 1 |
| 01:25 | 01:08 | 1 | (evento ignorado) | (evento ignorado) |
| 01:32 | 01:31 | 1 | 01:10-01:20 -> 2 | 01:10-01:20 -> 2 01:20-01:30 -> 1 01:30-01:40 -> 1 |
Conclusión
La gestión del tiempo de evento en la API Structured Streaming de Spark es esencial para mantener la exactitud y relevancia de eventos casi en tiempo real. Utilizando watermarks se pueden manejar los eventos atrasados para realizar las agregaciones, transformaciones y cálculos requeridos en los flujos de datos, a la vez que se van optimizando los estados en memoria.
Además, en este post hemos explorado algunos conceptos complementarios y particularidades del uso de watermarks, como las ventanas temporales, los retrasos máximos en la unión de flujos de datos y los modos de escritura soportados.
Por último, hemos añadido una breve actualización para conocer las mejoras que se han incorporado y que vale la pena resaltar con la llegada de las últimas versiones de Spark.
Hasta entonces, si te ha parecido útil este post, puedes pasarte por la categoría Data Engineering para ver más artículos como este y compartirlo con tus contactos para que ellos también puedan leerlo y opinar. ¡Nos vemos en redes!
