
En la primera parte del Tutorial sobre CUDA, hablamos sobre la unidad de ejecución más pequeña de la GPU: los warps. Los warps son el equivalente a un núcleo en una CPU. Sin embargo, solo con ellos no es posible aprovechar todo el poder de la GPU. Por eso, es necesario hacer uso de las abstracciones que hay por encima de estos elementos: bloques y grids.
No obstante, este modelo de ejecución sólo tiene sentido si el código es divisible en pequeñas tareas que ejecutan el mismo código, pero contribuyen a la tarea global. Por tanto, para los ejemplos que se describirán en este artículo, continuaremos con el caso de uso del kernel que suma elementos que vimos en el tutorial del post anterior.
Todo el código que invoca kernels CUDA es en Python usando Pycuda.
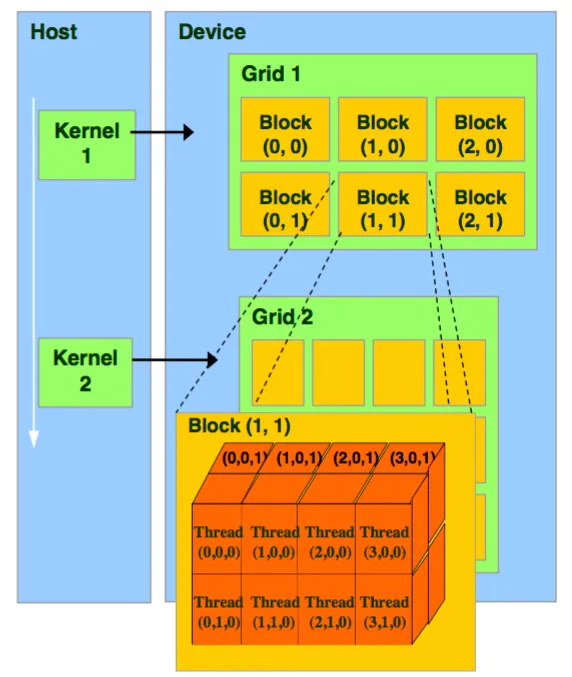
Cómo funcionan los Bloques en CUDA
Un bloque es un grupo ordenado de threads ejecutados por un SM (Streaming Multiprocessor). Cada thread está identificado por un ID único basado en su posición dentro de este bloque y, estos bloques, a su vez, no pueden tener nunca más de 1024 threads.
Como ejemplo tenemos un kernel perfectamente válido que, usando una reducción, obtiene la suma de un vector y se ejecuta sin generar ningún error con 256 threads.
__global__ void sum(float *a)
{
int idx = blockDim.x*blockIdx.x+threadIdx.x;
float val = a[idx];
__shared__ float shared_mem[8];
for (int offset = 16; offset > 0; offset /= 2) {
val += __shfl_down_sync(0xffffffff, val, offset);
}
if(threadIdx.x%32==0) {
shared_mem[threadIdx.x>>5]=val;
}
__syncthreads();
if (threadIdx.x<=8) {
val=shared_mem[threadIdx.x];
val += __shfl_down_sync(0xffffffff, val, 4);
val += __shfl_down_sync(0xffffffff, val, 2);
val += __shfl_down_sync(0xffffffff, val, 1);
if (threadIdx.x==0) {
a[0]=val;
}
}
}A continuación, invocamos el kernel con las siguientes llamadas a Pycuda.
func = mod.get_function("sum") # Obtain kernel
func(a_gpu, block=(256,1,1)) # Execute kernel with a single block of specified sizeSi realizamos el proceso con 256 threads, se ejecuta sin dar ningún error.
func = mod.get_function("sum") # Obtain kernel again
func(a_gpu, block=(2048,1,1)) # Execute with single block of 2048 threadsAhora, indicaremos que un bloque contiene 2048 threads en el eje X. Probablemente, lo que ocurrirá es que CUDA será incapaz de ejecutar el kernel arrojando el siguiente mensaje de error:
LogicError: cuFuncSetBlockShape failed: invalid argument
Por lo tanto, si queremos ejecutar más de 1024 threads a la vez, necesitamos ejecutar el kernel usando más bloques. Sin embargo, antes de añadir más bloques, primero debemos recordar algunas propiedades de que poseen estos elementos.
Arquitectura de Bloques en CUDA
Como parte de la arquitectura, un bloque tiene una memoria compartida a la que todo thread que pertenece a este bloque puede acceder, la shared memory. Esta memoria es, en esencia, una caché administrada por el usuario que además se puede usar para comunicar entre threads.
Por ejemplo, puede darse el caso en el que un warp escribe un resultado a un vector en shared memory. Entonces, otro warp podría leer ese valor siendo extremadamente más rápido que si la escritura se hubiera hecho en memoria global. Esta es una estrategia común en algoritmos de reducción y se puede ver en el kernel anterior donde declaramos con __shared__ un vector que pasa a estar en la shared memory. También podemos observar cómo en el kernel usamos esta shared memory para comunicar entre warps mientras hacemos una suma por reducción, al forzar solo un thread de cada warp a escribir su resultado de forma secuencial en memoria.
shared_mem[threadIdx.x>>5]=valLos bloques también vienen con un mecanismo de sincronización, la función __syncthreads(), que permite que todo thread perteneciente sólo y exclusivamente a este bloque y esté sincronizado en el momento que esa función se llama.
Los threads dentro de un bloque se organizan como una matriz de 3 dimensiones, X, Y y Z. Por otro lado, el usuario se encarga de dar las dimensiones de esta matriz, teniendo en cuenta que no puede sobrepasar 1024 threads. En el kernel podemos observar esto con el uso de threadIdx.x, que nos indica la posición de ese thread en la dimensión X de esta matriz.
¿Qué son las Grids en CUDA?
Se puede definir un grid como un grupo ordenado de bloques y cada bloque tiene un ID único basado en su posición dentro de la grid. Su organización es similar a cómo los bloques organizan threads.
La grid permite ejecutar algoritmos que usan más de 1024 threads, ya que, si no, sería imposible debido al límite de threads en bloque.
Los bloques de la grid se organizan como una matriz de 3 dimensiones, X, Y y Z, donde el usuario tiene que asignarle las dimensiones teniendo en cuenta que cada bloque contiene a su vez una matriz de threads.
func = mod.get_function("sum")
func(a_gpu, block=(256,1,1), grid=(8,2,10))Por ejemplo, aquí ejecutamos un kernel con 256 threads y una grid de 160 bloques, 8 en dimensión X, 2 en Y y 10 en Z. En total, un kernel con 40.960 threads.
Al contrario que en el caso del bloque, la grid no tiene ningún mecanismo para sincronizarse. Lo que ocurra entre bloques diferentes de una grid es independiente y no se pueden coordinar dentro de una misma llamada.
func = mod.get_function("sum")
func(a_gpu, block=(256,1,1), grid=(8,1,1))
a_sum = numpy.empty_like(a)
cuda.memcpy_dtoh(a_sum, a_gpu)Por ejemplo, en este código ejecutamos el kernel anterior en 8 bloques diferentes, pero como el código no tiene manera de hablar del trabajo entre bloques, nos encontramos que ha escrito 8 veces el resultado de la suma de un bloque en la misma posición de memoria. A su vez, no podríamos simplemente sumar en esa posición de la memoria global, ya que, al no existir sincronización, podríamos estar sobrescribiendo los diferentes bloques.
Sincronización de Grids
Por tanto, una manera común para conseguir un efecto similar a sincronizar bloques es encadenar diferentes llamadas a funciones, ya que si éstas son enviadas a la misma stream de CUDA, serán ejecutadas en orden, por lo que el resultado estará sincronizado antes de ejecutar la siguiente función.
__global__ void sum(float *a)
{
int idx = blockDim.x*blockIdx.x+threadIdx.x;
float val = a[idx];
__shared__ float shared_mem[8];
for (int offset = 16; offset > 0; offset /= 2) {
val += __shfl_down_sync(0xffffffff, val, offset);
}
if(threadIdx.x%32==0) {
shared_mem[threadIdx.x>>5]=val;
}
__syncthreads();
if (threadIdx.x<=8) {
val=shared_mem[threadIdx.x];
val += __shfl_down_sync(0xffffffff, val, 4);
val += __shfl_down_sync(0xffffffff, val, 2);
val += __shfl_down_sync(0xffffffff, val, 1);
if (threadIdx.x==0) {
a[blockIdx.x]=val;
}
}
}
Alterando el kernel anterior, ahora escribimos el resultado en posiciones diferentes de memoria global.
func = mod.get_function("sum")
func(a_gpu, block=(256,1,1), grid=(8,1,1))
cuda.memcpy_dtoh(a_sum, a_gpu)
print(sum(a_sum[0:8]) - sum(a))
# El resultado da cercano a 0 (imprecisiones de hardware)Con esto obtenemos los 8 elementos en su posición correcta, pero queremos sumar estos 8 elementos restantes en la GPU. Una manera de hacerlo sería, por ejemplo, con un pequeño kernel que se ejecutará después del que hemos definido previamente, en el bloque de código anterior.
__global__ void sum_small(float *a)
{
float val = a[threadIdx.x];
if (threadIdx.x<=8) {
val += __shfl_down_sync(0xffffffff, val, 4);
val += __shfl_down_sync(0xffffffff, val, 2);
val += __shfl_down_sync(0xffffffff, val, 1);
if (threadIdx.x==0) {
a[0]=val;
}
}
}
En este caso, tenemos un kernel simple que solo suma 8 elementos.
func(a_gpu, block=(256,1,1), grid=(8,1,1))
func_small(a_gpu, block=(8,1,1), grid=(1,1,1))
cuda.memcpy_dtoh(a_sum, a_gpu)
print (a_sum[0] - sum(a))
# El resultado da cercano a 0 (imprecisiones de hardware)Encadenando ambas invocaciones a kernels, ahora podemos obtener la suma completa.
Grids: Ejemplo práctico
Finalmente, podemos ver un ejemplo de cómo coordinar varias ejecuciones de kernel con diferentes grids para hacer una suma de un simple vector de 2^24 elementos, y compararlo con Numpy y Python puro en eficiencia.
__global__ void sum(float *a)
{
int idx = blockDim.x*blockIdx.x+threadIdx.x;
float val = a[idx];
__shared__ float shared_mem[8];
val += __shfl_down_sync(0xffffffff, val, 16);
val += __shfl_down_sync(0xffffffff, val, 8);
val += __shfl_down_sync(0xffffffff, val, 4);
val += __shfl_down_sync(0xffffffff, val, 2);
val += __shfl_down_sync(0xffffffff, val, 1);
if(threadIdx.x%32==0) {
shared_mem[threadIdx.x>>5]=val;
}
__syncthreads();
if (threadIdx.x<=32) {
val=shared_mem[threadIdx.x];
val += __shfl_down_sync(0xffffffff, val, 4);
val += __shfl_down_sync(0xffffffff, val, 2);
val += __shfl_down_sync(0xffffffff, val, 1);
if (threadIdx.x==0) {
a[blockIdx.x]=val;
}
}
}
El kernel es el kernel de siempre, pero con la ligera optimización de pasar el for a 5 instrucciones separadas.
func(a_gpu, block=(256,1,1), grid=(65536,1,1))
func(a_gpu, block=(256,1,1), grid=(256,1,1))
func(a_gpu, block=(256,1,1), grid=(1,1,1))Sumar todo el vector es tan simple como llamar a la función 3 veces con cantidades diferentes de bloques.
Comparando con el tiempo que requiere sumar en Numpy y Python, tenemos que la GPU es 8.1 veces más rápida que Numpy con esta implementación y 2295.5 veces más rápido que Python puro. Hay que tener en cuenta que estos resultados dependen del hardware usado, en este caso, usando una GPU poco potente.
Es solo 8 veces más rápida que la implementación en Numpy, ya que hace uso de código altamente optimizado usando incluso instrucciones AVX para operar de forma más eficiente sobre vectores.
Conclusión
Hemos visto qué son los bloques y las grids, permitiéndonos así organizar threads por encima de los warps y dividiendo el trabajo en pequeñas tareas que cada thread ejecuta dependiendo de su posición dado su bloque en la grid y su thread dentro del bloque.
Este sistema para organizar threads nos permite diseñar programas altamente paralelos de forma nativa que, comparados incluso con código altamente optimizado que hace uso de todo posible beneficio que el hardware ofrece, como instrucciones AVX, sigue siendo más de 8 veces más rápido. A su vez, nos limita en el típico de tareas que pueden ejecutarse, ya que éstas tienen que ser compatibles con el modelo de ejecución de CUDA.
¡Esto es todo! Si este post te ha parecido interesante, te animamos a visitar la categoría Algoritmos para ver todos los posts relacionados y a compartirlo en redes. ¡Hasta pronto!
