
En este post hablaremos de los principales conceptos de DataHub a nivel funcional y estudiaremos los elementos fundamentales haciendo un tour por la aplicación. Para poder seguirlo, puedes apoyarte en la página de demo de DataHub.
En la top bar de la pantalla home de la demo, o de nuestro propio despliegue, podremos encontrar los siguientes apartados.

Haciendo click en Govern podemos encontrar tanto Glossary como Domains. Estos son dos conceptos principales de DataHub.
Qué es un Domain en DataHub
Un dominio, en pocas palabras, es una agrupación lógica de diferentes recursos dentro de nuestra plataforma. Puede pertenecer a otro dominio padre, por lo que podemos utilizar este concepto para modelar completamente la jerarquía de espacios dentro de nuestra organización.
Crear un dominio es una tarea que se puede realizar de manera muy sencilla, solamente necesitamos tener privilegios de Manage Domains.
Una vez que nos disponemos a crear un dominio, vemos que las opciones de creación son muy escuetas, prácticamente un nombre y un padre sobre el que ubicarlo. Cuando entramos dentro, observamos que tenemos más opciones, ya que no hay que olvidar que un dominio está pensado para poder relacionar recursos bajo el mismo contexto.
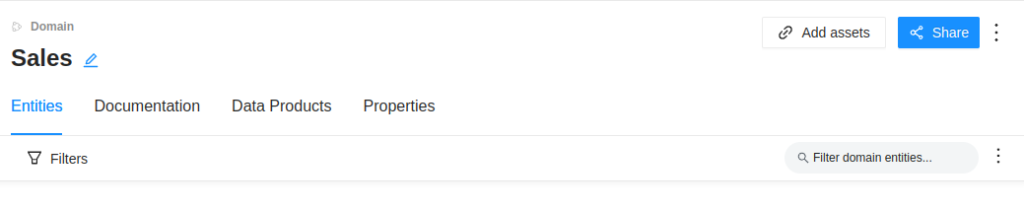
También es posible agregar recursos al dominio mediante el botón Add Assets, donde nos aparecerá un listado de todos los recursos para poder enlazarlos al dominio.
Por otro lado, se puede añadir documentación a nuestro dominio desde la pestaña Documentation. La documentación que se debería poner aquí, desde mi punto de vista, debe estar siempre relacionada con los datos, no sería conveniente incluir documentación general del dominio, ya que esta plataforma no es adecuada para ello.
Desde un punto de vista más práctico, pensaremos en un dominio como el espacio conceptual que engloba a todos esos recursos relacionados. En nuestra organización, podemos decidir gestionar los datos a través de sedes porque cada una es muy independiente de las otras y, por tanto, definir cada sede como un dominio diferente.
El concepto Glossary en DataHub
Hablar de una plataforma de Data Governance, significa hablar de un completo glosario de términos y DataHub no será una excepción. De hecho, este concepto es una de las piezas principales de la plataforma.
Lo primero y para los más nuevos: ¿Qué es un término? ¿Qué es un grupo de términos? Y, ¿qué es un glosario? La definición de cada uno de estos conceptos es muy sencilla e intuitiva, pero aquí lo más complicado, sin duda, es la aplicación práctica.
Un glosario es un conjunto de términos y grupos de términos. Todos juntos forman el glosario. Un término es una definición clara y concisa de un concepto dentro de nuestra organización. Esto que parece tan sencillo, a veces no lo es, sobre todo cuando tratamos con lo que, haciendo una referencia a la Arquitectura Hexagonal, se conoce como lenguaje ubicuo. Martin Fowler, desarrollador de software, profundiza en esta lectura en el concepto de lenguaje ubicuo.
Aterricemos con un ejemplo práctico de lo que es un término. Primero, ¿todo dentro de nuestra empresa es un término dentro de nuestro glosario? La respuesta es un rotundo NO. Tenemos que entender que estamos en una plataforma de Data Governance y, por tanto, los términos deben tratar con la gestión del dato.
Supongamos que nuestra organización se dedica a la logística y trabaja con paquetes. Nosotros estamos construyendo el ecosistema de datos de nuestra organización y, dentro de la capa de negocio, se utiliza mucho la palabra ‘bulto’. Un ‘bulto’ puede ser un término a usar dentro de nuestro glosario de datos, ya que veremos, por ejemplo, rutas de reparto y cantidad de bultos repartidos. Este concepto es muy importante y potente, porque es el que nos permitirá posteriormente construir un ecosistema de datos muy rico.
Ahora, supongamos que queremos ver un dashboard a través de Looker donde se muestran los bultos repartidos por la ciudad. Ese dashboard, que será alimentado mediante una tabla de nuestro Data Warehouse, deberá ser representado en nuestra plataforma y etiquetado con uno o varios términos. Seguramente, le aplicaremos la etiqueta del término ‘bulto’. Los términos podrán ser aplicados a diferentes recursos de datos. Por ejemplo, podríamos etiquetar el término ‘bultos’ a una columna que lleva la agregación de paquetes repartidos por día.
Una vez creado, podemos generar documentación asociada a dicho término o enlazar una página web al mismo.
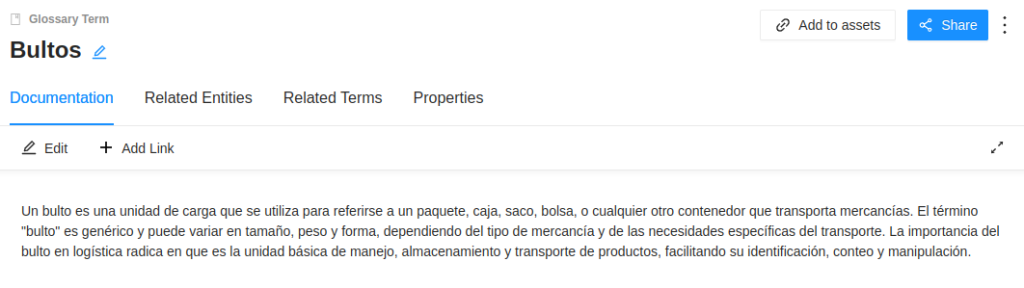
La segunda pestaña nos permite gestionar los recursos relacionados con el término. Cuando queremos relacionar un nuevo recurso, debemos hacer clic en el botón Add to Assets, donde aparecerá un modal que nos permitirá filtrar y buscar nuestro recurso.
Por último, y para mí la parte más relevante de la gestión de los términos, es que un término puede tener relación con otro término. DataHub nos permite establecer dos tipos de relaciones: Contains e Inherits. Esto es especialmente útil para poder enriquecer nuestro ecosistema de datos.
Volviendo a nuestro ejemplo, supongamos que queremos ver aquellos bultos que se han perdido en la organización. Podemos definir el término ‘perdido’, con su apropiada definición, y relacionarlo con ‘bulto’ para poder tener la representación de un bulto que se ha perdido. No deja de ser un bulto, pero es una especificación mayor a la de simplemente bulto.
Ingestión de fuentes de datos
Cuando hablamos de la ingestión de datos, nos referimos al proceso de reunir, importar y procesar datos desde diversas fuentes externas para almacenarlos, analizarlos y utilizarlos dentro de la plataforma. Este proceso es el que le da sentido a toda la plataforma, ya que, gracias a él, podremos disponer de diferentes fuentes de datos actualizadas y listas para su uso analítico, representadas dentro de DataHub.
DataHub no solo está orientada a la ingestión de una base de datos o un Data Warehouse. La plataforma nos brinda mecanismos para poder ingestar otros tipos de datos, como por ejemplo, procesos de transformación como los que suceden en una ELT, procesos de visualización del dato desde un dashboard de BI, o procesos de calidad y validación del dato.
La manera más sencilla de ingestar un nuevo dato es a través de la interfaz web de la plataforma.
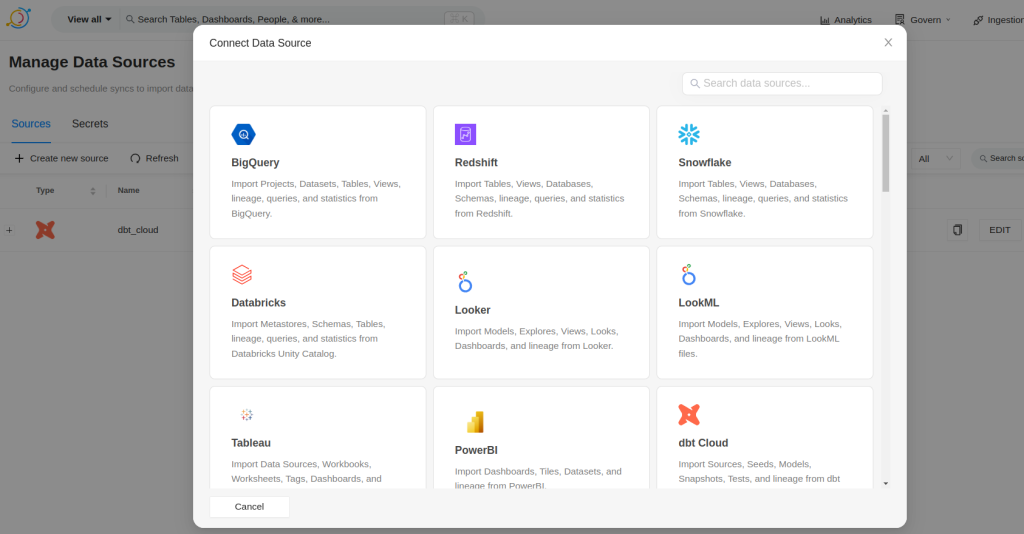
En ella, podremos encontrar los conectores soportados. Estos conectores funcionan con un sistema de pooling que irá consultando a la fuente acerca de los metadatos que contiene y refrescando la información dentro de DataHub. A este tipo de integraciones se las conoce como integraciones tipo Pull. Pero no son las únicas que existen, también podemos encontrar las llamadas integraciones tipo Push, como Airflow o Spark.
Básicamente, en las integraciones Push, son las propias fuentes las que emiten los cambios directamente sobre la plataforma, sin que ésta sea quien consulte. Esto normalmente ocurre cuando no hay una API clara o un esquema de consulta sólido sobre el que DataHub pueda trabajar.
Para entender la integración como fuente, nos centraremos en las tipo Pull.
En nuestro ejemplo, hemos integrado una cuenta de dbt cloud.

Vemos cómo aparece una columna tipo CRON con la configuración de cuándo se debe ejecutar la sincronización con la fuente. También podemos observar cómo ha ido la última ejecución para detectar si ha existido un fallo en la integración.
Data Assets y Entities en DataHub
Por último, veremos los recursos ingeridos en la fase anterior. En DataHub, todos los objetos de datos se ven relacionados de una forma u otra con otros objetos de datos. Aquí podemos ver una representación de estas relaciones.
Para abrir el explorador de datos haremos clic en Explore all en la pantalla home. Y se abrirá la siguiente pantalla.
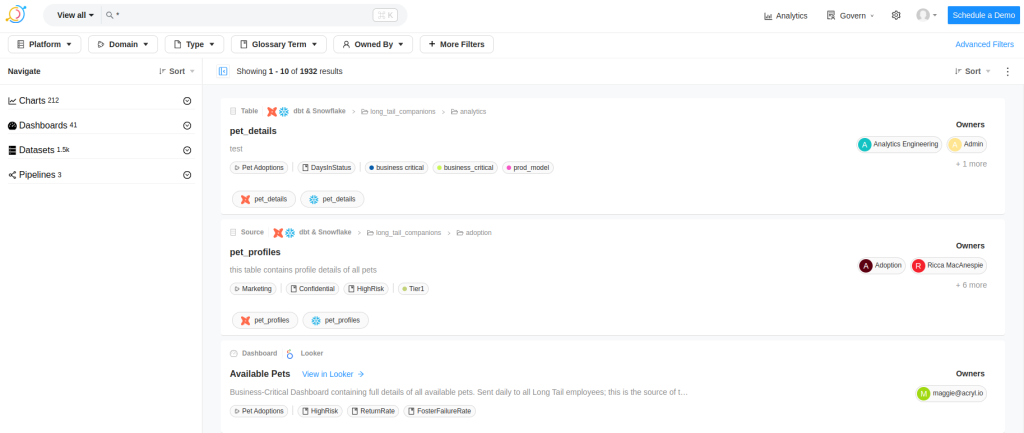
Esta pantalla es clave para la navegación a través de cualquier tipo de dato dentro de la plataforma. En la barra superior, encontramos la barra de filtrado, mientras que la barra lateral izquierda, nos permite navegar a través de la agrupación de los datos filtrados. En la parte central, tenemos la lista de recursos en detalle.
Cada uno de los ítems en la parte central muestra un resumen del recurso. Hagamos clic en el siguiente recurso.

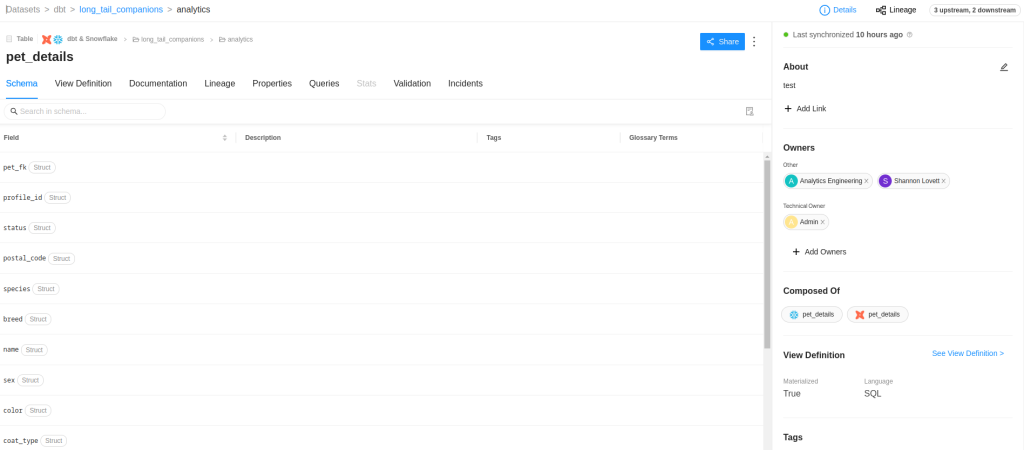
Observemos la pantalla de detalle. En este caso, se trata de una tabla de Snowflake llamada pet_details, que está modelada mediante dbt. Veremos la definición de los campos de la tabla y, si tuviéramos descripciones para cada columna, toda esta información se integraría con DataHub.
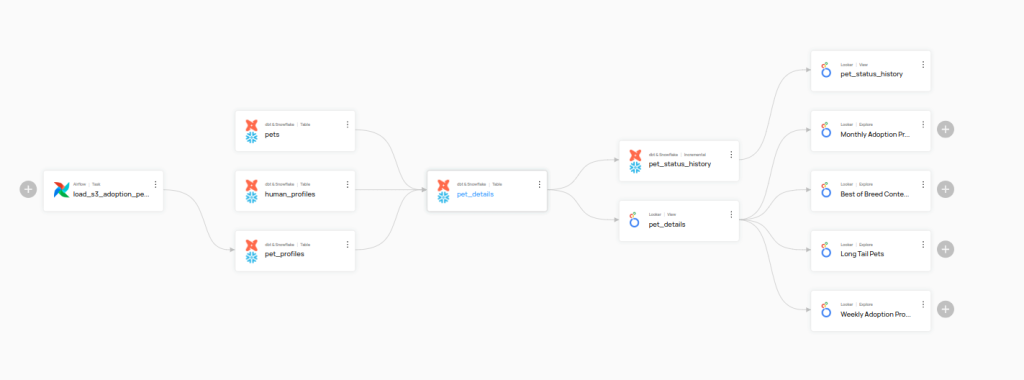
Es interesante hacer clic en Lineage para ver la relación de este recurso con otros recursos. Esta pantalla es clave para conocer la procedencia de cada uno de dichos recursos y cómo se pueden explotar.
Si el modelo contiene alguna restricción que debe cumplirse al cargarse, podremos verlo en la pestaña de validaciones. Esta pestaña nos ayuda a hacer un seguimiento de la calidad del dato. En este caso, con la integración con dbt cloud, DataHub es capaz de recoger el JSON generado como resultado de los datos y presentar las últimas ejecuciones de pruebas del modelo.
La última pestaña que encontramos está relacionada con la cooperación y la comunicación entre los usuarios. Si un usuario encontrara una incidencia, podría reportarla dentro del modelo para informar al equipo de datos. Esta capacidad está integrada con sistemas de tickets como Jira, de manera que, aunque las incidencias se creen mediante el sistema de DataHub, el equipo podrá seguir trabajando con su plataforma de gestión de tareas.
Conclusión
Esto es todo para este tutorial, recomiendo revisar las diferentes integraciones de ingesta que tiene DataHub y, si resulta de interés alguna en concreto, os recomiendo leer la documentación de DataHub porque encontraremos funcionalidades específicas entre cada una.
Si te ha parecido interesante este artículo, visita la categoría Data Engineering de nuestro blog para ver post similares a este y compártelo en redes con todos tus contactos. No olvides mencionarnos para poder conocer tu opinión @Damavisstudio. ¡Hasta pronto!
