
Comenzamos una colección de tutoriales sobre el uso y funcionamiento de DataHub, una plataforma Data Governance que ya mencionamos en el post qué es y en qué consiste un Data Catalog. En esta serie, exploramos el concepto de gobernanza de datos desde una perspectiva más práctica.
DataHub es una herramienta de código abierto, un aspecto crucial para entender por qué destaca entre las mejores plataformas de gobernanza de datos. Para tareas transversales como esta, las herramientas de terceros o de código abierto son la mejor elección. La razón es sencilla: muchos de los grandes competidores abordan el desafío de la gobernanza de datos desde una perspectiva sesgada e interesada, ofreciendo soluciones que integran principalmente sus propios productos, lo que a menudo resulta en un vendor lock-in. Esto no cubre la amplia variedad de arquitecturas reales, que pueden incluir soluciones híbridas entre múltiples nubes o arquitecturas «on-premise-cloud» compuestas en gran medida por tecnologías de código abierto.
DataHub ha creado una comunidad robusta que desarrolla sus propias integraciones con otras plataformas, lo que incentiva a los desarrolladores de dichas plataformas a integrar sus soluciones, como los data warehouses, con un esfuerzo mínimo.
Como plataforma de gobernanza de datos, DataHub ofrece una solución global para la integración de múltiples fuentes de datos, sistemas de transformación ETL/ELT y sistemas de visualización o consumo. Todo esto se gestiona desde una única plataforma web, lo que facilita la democratización de los datos dentro de la organización y permite compartirlos de manera sencilla. Además, DataHub incluye un sistema de reporte de incidencias sobre los datos, promoviendo la colaboración en la mejora de su calidad por parte de cualquier usuario.
Arquitectura de DataHub
DataHub es una plataforma desarrollada por LinkedIn, diseñada para ofrecer una solución integral de gobernanza de datos. Ello conlleva muchos aspectos que, en mi opinión, hacen que la arquitectura sea más compleja a cambio de cubrir funcionalidades extra a un simple Data Catalog. DataHub está orientada a resolver problemas de calidad de datos mediante un sistema integral de observabilidad de los mismos, que a menudo incluye integraciones en tiempo real con diversas fuentes de datos. Veamos desde una gran altura cómo se comunican los componentes de DataHub.
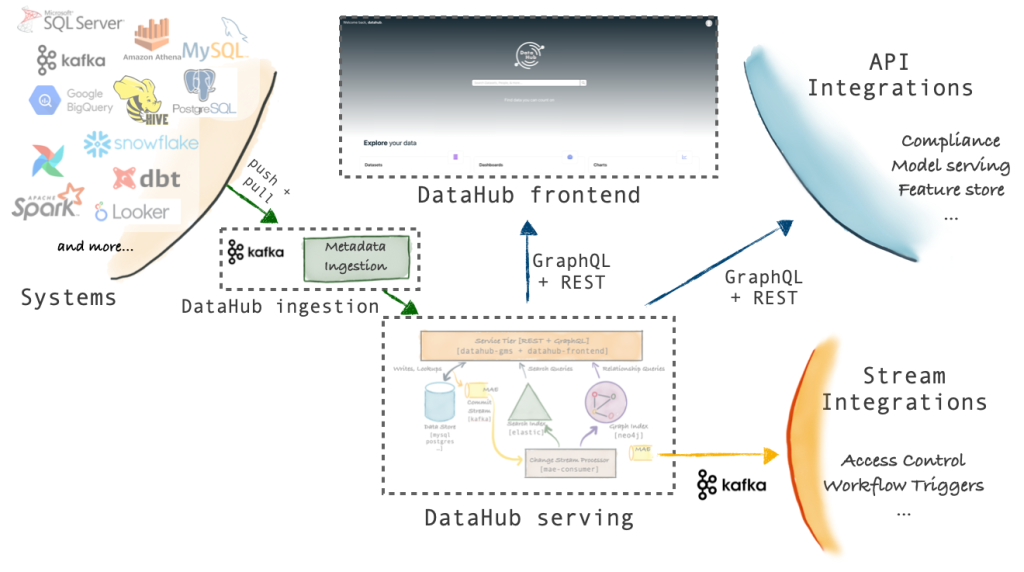
Como podemos ver, las diferentes fuentes soportadas en DataHub pueden ser ingestadas a través del sistema “Push / Pull DataHub Ingestion”, que permite mediante Api o Kafka la ingesta de información dentro DataHub. También podemos observar que DataHub expone un Api Rest con GraphQL para poder consultar y servir la información. Principalmente, este componente se conecta con el frontend.
DataHub under the hood
DataHub se apoya en MySQL y Elasticsearch como sus dos grandes componentes para la persistencia de toda la metainformación y esquemas de nuestra organización.
El servicio de metadatos, más conocido como GMS, es el corazón de DataHub y el encargado de conectarse con la capa de persistencia, la centralización de qué se debe guardar y cómo pasa por este componente. Contra el servicio GMS se conecta tanto el servicio de ingesta como el componente visual de DataHub en forma de web.
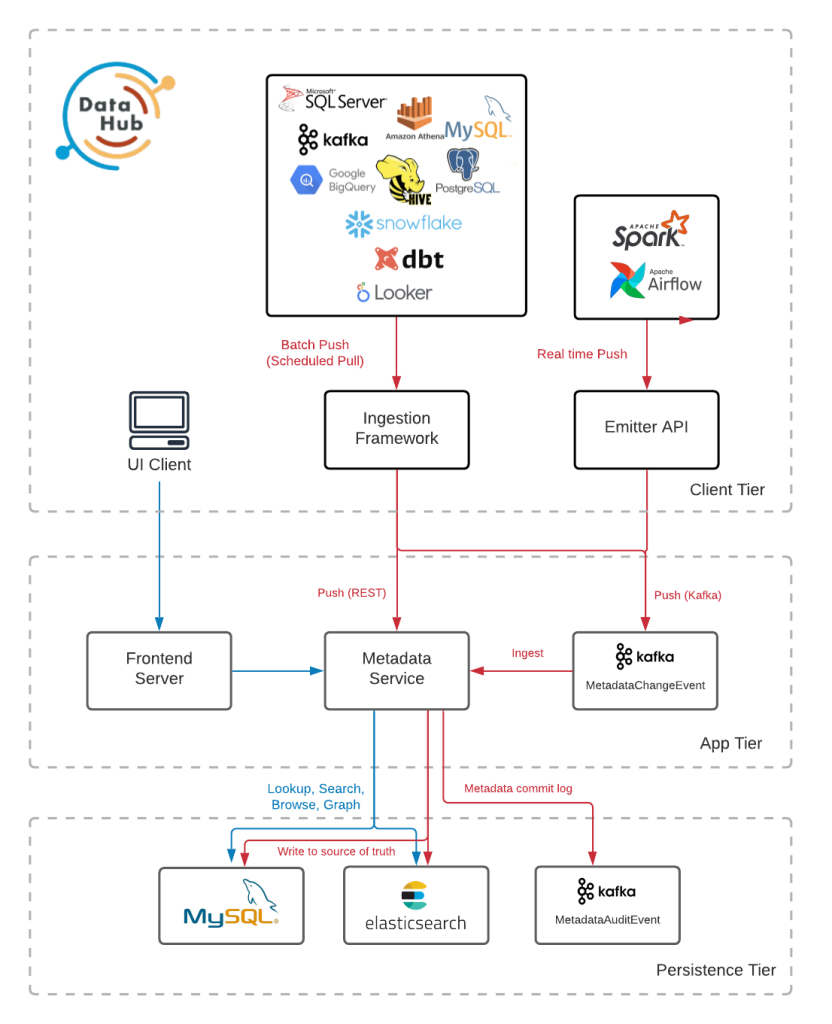
Servicio Metadata o GMS
Es el componente sobre el que todos los demás giran. Se trata de una aplicación desarrollada en Java. Se apoya en dos tecnologías:
- Api GraphQL, que sirve para la actualización y consulta de los metadatos de la aplicación. Esta api expone dos endpoints diferentes:
- localhost:8080/api/graphiql (metadata-service). Este endpoint sería el que podemos utilizar de manera pública. Más adelante veremos ejemplos de uso, ya que se suele utilizar con objetivos de ingesta de datos automatizados.
- localhost:9002/api/graphiql (datahub-frontend-react). Este servicio no es de acceso público, de hecho está protegido mediante una autenticación por defecto.
- Api Rest.li que se encarga de gestionar los modelos sin procesar en PDL. Esta api se utiliza de manera interna por el sistema, de ahí que el dato devuelto sea bruto.
Internamente, GMS utiliza PDL (Pegasus Data Language) para la definición de los esquemas de los diferentes metadatos. El proyecto de PDL también ha sido desarrollado por LinkedIn y facilita tanto la validación de datos respecto a esquemas como la generación e interoperabilidad de los mismos.
Servicio de Ingesta
La ingesta de metadatos dentro de DataHub, como ya hemos adelantado, se puede hacer de dos formas a través del servicio Api de Push/Pull.
Cuando utilizamos el sistema push, estamos enviando directamente los datos nosotros al servicio de metadatos, o bien a través de la Api Rest, o de un topic de Kafka que habilitamos para dicho fin. La responsabilidad del envío de los datos recae directamente en el emisor, esto tiene una ventaja clara, el dato se mantiene actualizado en tiempo real. La desventaja de este sistema, es que toda la lógica y responsabilidad recae en el emisor, por tanto trasladamos una responsabilidad extra a un microservicio que tal vez no debería tenerlo. Para ello, podemos hacer uso de patrones de arquitectura para limitar el impacto de tener dicha lógica en nuestras aplicaciones o sistemas.
El sistema pull es totalmente al contrario del push. En el anterior sistema, el emisor era quien tenía la iniciativa de mandar la información y, en este caso, la iniciativa la tiene DataHub que es quien solicita a la fuente los metadatos que necesitará. Este sistema funciona bastante bien con plataformas de DataWarehouse, ya que permite preguntar por los cambios en las tablas su contenido.
Alrededor de una tarea de ingesta existen cuatro conceptos clave que se relacionan entre sí.
- Recetas o “Recipes”: Se trata de los archivos de configuración para la ingesta de los metadatos. Básicamente, indica al sistema qué fuentes deben de ser ingestadas y dónde deben ser ingestadas.
- Fuentes o “Sources”: Una fuente no es más que un componente o servicio dentro de nuestra organización que será representada dentro de DataHub. En la documentación de DataHub Integrations se puede consultar una lista de las fuentes disponibles.
- Transformaciones o “Transformers”: Dentro de una receta podemos definir transformaciones que afectarán a las fuentes antes de llegar a su destino. Estas transformaciones están pensadas para personalizar las ingestas permitiendo definir, por ejemplo, tags, especificar el propietario, modificar algún campo clave de la fuente, etc.
- Destino o “Sink”: A la hora de definir el destino podemos elegir entre dos opciones. Que el destino sea el servicio datahub-rest, que sería el destino por defecto. O que el destino sea el servicio datahub-kafka. También existe la capacidad de enviar los datos a consola o un fichero, pero esto solamente se hace con fines de desarrollo y depuración de una ingesta.
Capa de persistencia
Por último, veremos la capa de persistencia. En ella, podemos encontrar dos bases de datos Mysql y Elasticsearch. La primera es la encargada de persistir toda la metainformación del sistema, para lo que utiliza el ya conocido PDL y los almacena en una única tabla dentro de la base de datos.
La tabla se llama metadata_aspects_v2. Veamos un ejemplo de registro:
| urn | urn:li:corpuser:datahub |
| aspect | corpUserEditableInfo |
| version | 0 |
| metadata | {«skills»:[],»teams»:[],»pictureLink»:»https://raw.githubusercontent.com/datahub-project/datahub/master/datahub-web-react/src/images/default_avatar.png»} |
| system_metadata | |
| created_on | 2024-07-09 11:51:32 |
| created_by | urn:li:corpuser:__datahub_system |
| created_for |
Todos los metadatos son almacenados con esta estructura, la información clave aquí son los campos urn, aspect y metadata. La manera en la que DataHub encuentra los datos es a través del campo URN, que funciona como el localizador de los recursos, y toda la información clave se encuentra dentro del campo metadata.
Elasticsearch, por el contrario, se encarga principalmente de mejorar la búsqueda de metadatos. Elasticsearch permite indexar los datos de manera que la búsqueda de los mismos y el autocompletado a la hora de utilizar el frontend web sean mucho más eficientes.
Conclusión
DataHub ofrece una solución completa y flexible para la gobernanza de datos. Su enfoque en la comunidad y las integraciones, lo convierte en una opción sólida para aquellos que buscan flexibilidad y escalabilidad en la gestión de datos.
Si este artículo te ha parecido interesante, te animamos a visitar la categoría Data Engineering para ver otros posts similares a este y a compartirlo en redes. ¡Hasta pronto!
