
Continuamos con lo ya descrito en la primera parte de esta serie de artículos sobre Sensitive data management en BigQuery. Trabajar con datos en esta herramienta puede requerir de un control sobre quién accede a ellos y cómo se presentan a los usuarios. Ya hemos visto cómo mediante el uso de etiquetas y una aplicación de políticas adecuada, podremos tener un gran control sobre qué columnas verán los usuarios, e incluso presentarlas de forma ofuscada si fuera necesario.
Sin embargo, este enfoque nos permite controlar sólo una dimensión de la tabla, a nivel vertical. En este post, veremos la solución que BigQuery nos ofrece para el control de estos datos en la dimensión horizontal, es decir, a nivel de fila.
Row level security en BigQuery
De manera análoga a como se comentó en el análisis de CLS (column level security), este proceso se puede enfocar de varias formas. Una opción cuando necesitamos de este tipo de filtrado, podría ser el uso de vistas autorizadas con un filtro apropiado. No obstante, esto puede ser una buena aproximación al problema para casos puntuales, pero difícilmente escalable. En este caso, veremos cómo realizar esto mediante políticas de acceso a nivel de fila (RLS).
El row level security es muy interesante para establecer políticas de acceso concretas donde definir qué cantidad de información de una tabla se mostrará al usuario/grupo en función de un filtro. Estos permisos podrán fijarse de forma independiente a la propia tabla, separando la definición de las políticas en sí.
En primer lugar, es necesario tener ciertos permisos para poder acceder a esta herramienta en BigQuery: BigQueryAdmin o BigQueryDataOwner.
Las políticas de acceso a nivel de fila se implementan mediante sentencias DDL muy similares a cómo se crean UDF, tablas, etc. La estructura a seguir es la siguiente:
CREATE ROW ACCESS POLICY
$filter_name
ON
$project_id.$dataset.table1
GRANT TO ("group:sales-us@example.com",
"user: jon@example.com",
"domain: example.com",
"serviceAccount:service@project.iam.gserviceaccount.com"
)
FILTER USING
($column_name=$value);La sentencia consta de 3 partes:
- Primero, nos encontramos con la definición del nombre y la tabla sobre la que va a tener efecto.
- En segundo lugar, un bloque donde indicaremos a quién o quiénes se le aplicará dicho filtro. Como se puede observar en el ejemplo, podremos incluir un usuario concreto, un grupo, un dominio o incluso un service account.
- Por último, nos encontraremos el filtro en sí. Éste funciona como una cláusula WHERE añadida tras la tabla, de manera que es totalmente personalizable. Podremos concatenar las distintas condiciones y/o referenciar a otras tablas mediante subqueries. También es interesante el uso de funciones como
SESSION_USER(), donde podremos comparar de forma dinámica nuestro usuario de sesión con los otros valores si es necesario.
Definición y aplicación de políticas de acceso
A continuación, definiremos algunas políticas y veremos cómo se aplican sobre una tabla concreta. Continuaremos trabajando con la misma tabla sobre la que ya gestionamos las políticas a nivel de columna.(Para facilitar los siguientes ejemplos, se ha eliminado el enmascaramiento presente para el campo email).
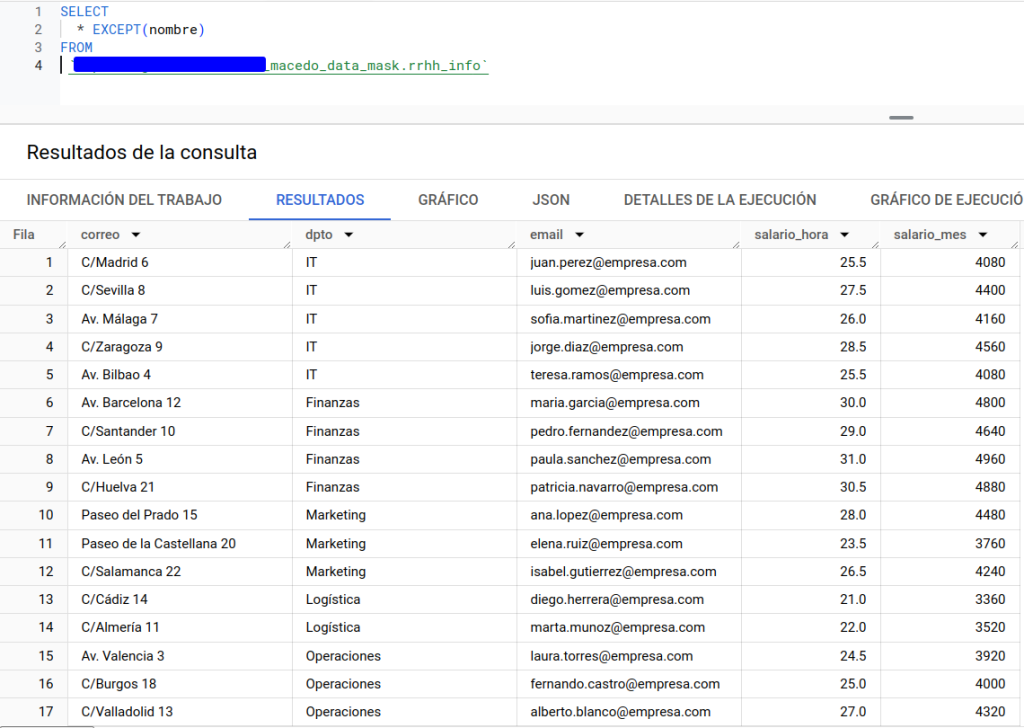
En este caso, creamos una política de acceso que realizará lo siguiente: mostrará a nuestro usuario únicamente aquellas filas correspondientes al departamento de IT. Esto podría ser un buen ejemplo de cómo controlar el acceso a un grupo. Por simplicidad, en el ejemplo solo se aplicará al usuario actual como vemos a continuación.
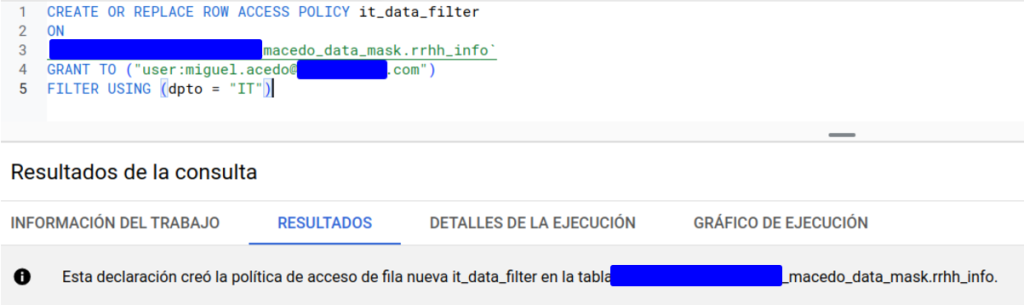
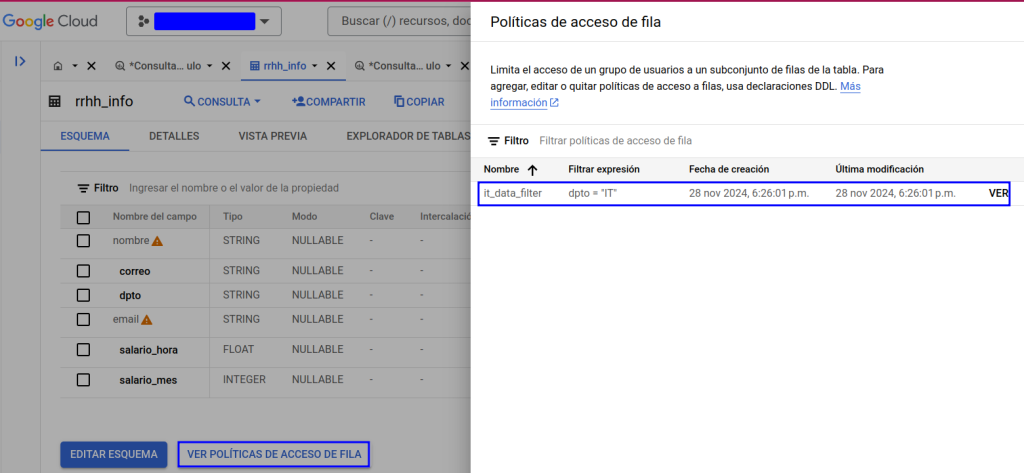
Si queremos comprobar qué filtros se están aplicando sobre nuestra tabla, lo podemos realizar desde la UI de BigQuery (también se podrán consultar mediante el cliente bq en la terminal) en la pestaña de esquema:
Si tratamos de acceder a los datos, veremos lo siguiente:
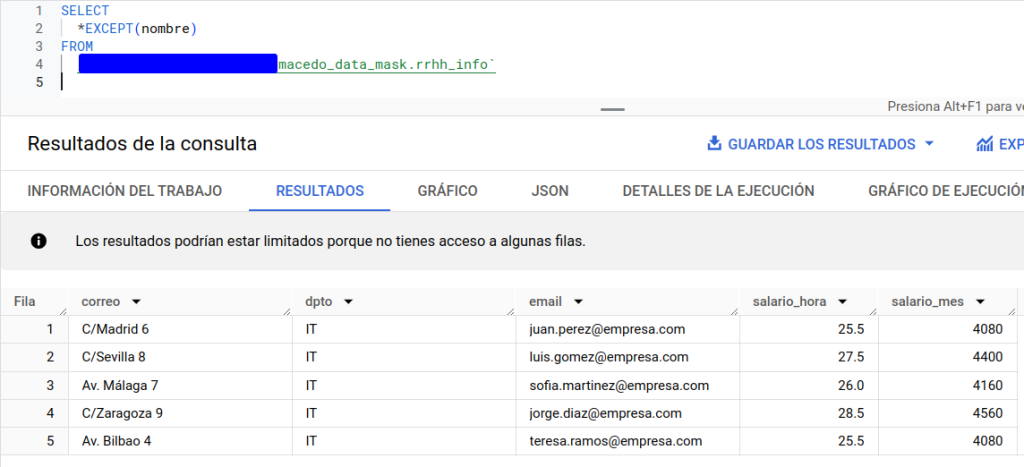
Como era de esperar, solo tenemos acceso al departamento de IT. A continuación, vamos a incluir otra condición en nuestro filtro, pero usaremos una subquery sobre una tabla de referencia. Esto puede ser un enfoque muy adecuado si necesitamos una lista de control de acceso en la que tengamos el conjunto de los usuarios que queremos que accedan a la tabla.
Vamos a tener, por ejemplo, una ACL que contendrá el nombre del supervisor de un conjunto de trabajadores. Estos trabajadores son los que encontramos en la tabla inicial. El supervisor solo podrá ver datos de sus empleados. A continuación, la tabla de ejemplo:
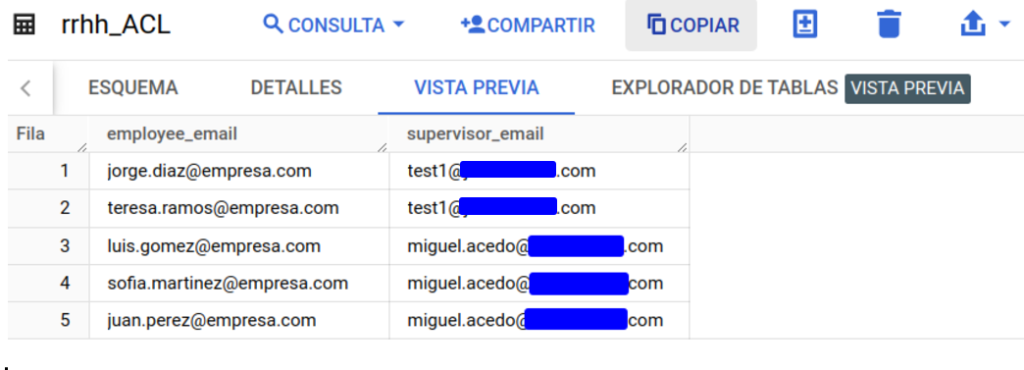
Procedemos a alterar el filtro que se aplica sobre nuestra tabla. Hemos agregado como condición una subquery que apunta a una tabla completamente distinta a la que estamos filtrando, usando, además, el filtro de session_user().
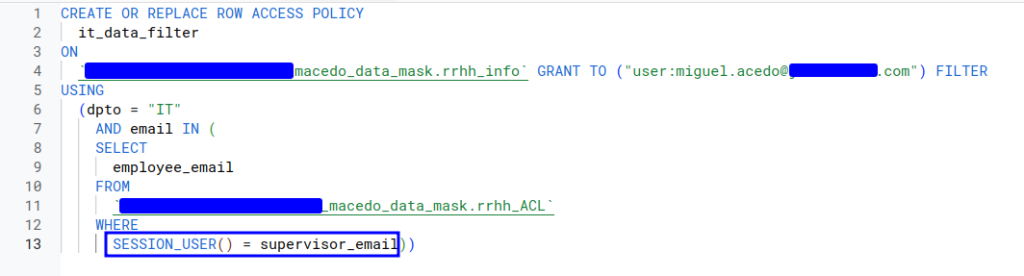
Si bien para este caso se ha realizado una concatenación de condiciones en cuanto al filtrado, es importante mencionar que, de igual manera, se podrían haber aplicado distintos filtros logrando el mismo comportamiento. O, por el contrario, se podría haber añadido mayor complejidad a dicho filtro. Todo esto dependerá de los requerimientos que tengamos.
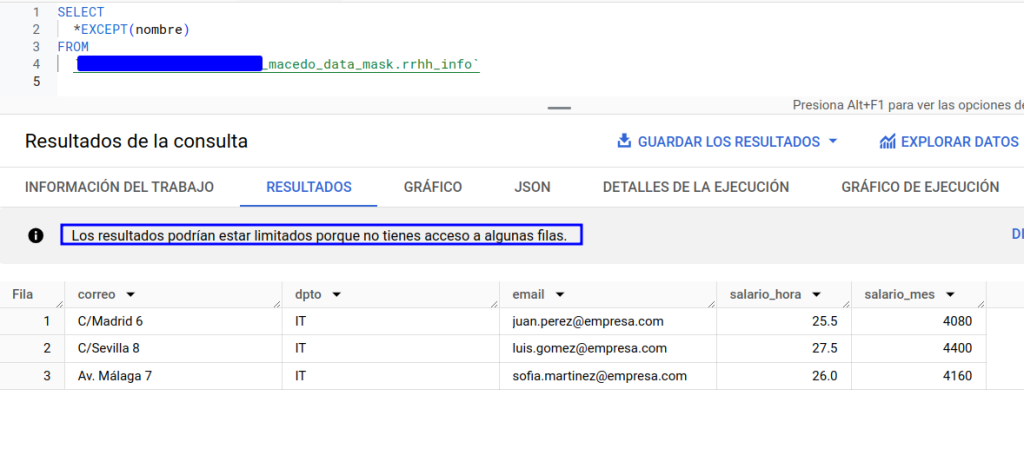
Si, de nuevo, ejecutamos la consulta, únicamente aparecen aquellos empleados cuyo supervisor coincide con el email al que pertenece la sesión de usuario.
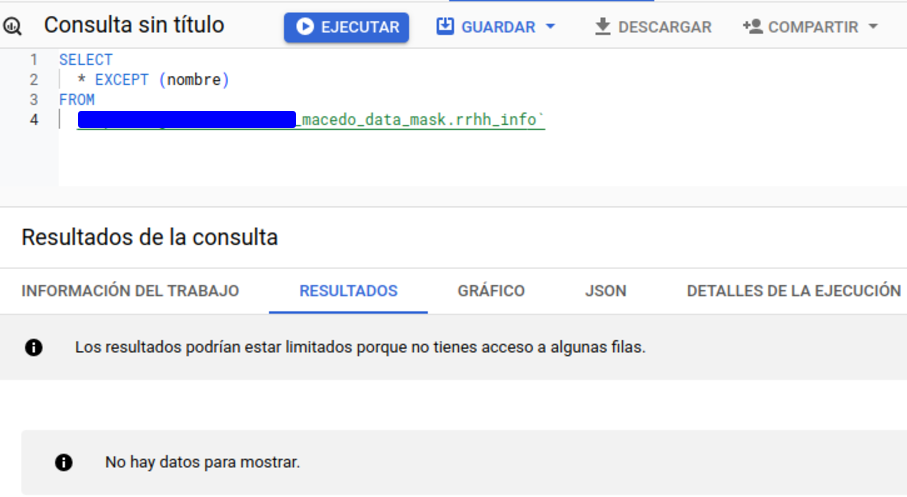
Se ha pedido a un usuario, cuyos permisos son los mismos que los del usuario de pruebas sobre la tabla, que acceda. Como podemos ver, al no haber más de un usuario en la lista de permisos, se muestran un total de 0 registros.
Borrado de políticas de acceso a los datos
En cuanto al borrado de dichas políticas, se realizan también mediante sentencias DDL del tipo:
DROP ROW ACCESS POLICY my_row_filter ON project.dataset.my_table;En caso de que solo exista una única política definida (o de necesitar eliminar todas), la sentencia de borrado será:
DROP ALL ROW ACCESS POLICIES ON project.dataset.my_table;Conclusión
Tal y como hemos visto, se puede controlar de una manera muy simple la cantidad de registros a los que el usuario puede acceder. La generación de estas políticas de acceso a fila permiten tener un gran control, soportar una gran complejidad de filtrado y complementar a la perfección nuestras políticas de acceso a columnas.
Hemos visto cómo podemos controlar de manera muy sencilla y con una granularidad total quién accede a cada uno de los registros de nuestra tabla sin necesidad de duplicidades, vistas, dataset separados, etc…
Si este artículo te ha parecido interesante, te animamos a visitar la categoría Data Engineering para ver otros posts similares a este y a compartirlo en redes. ¡Hasta pronto!
