
Process Discovery es una familia de técnicas empleadas para obtener información de logs de eventos y reconstruir el modelo subyacente que hayan generado. Dicho modelo, después puede utilizarse para diferentes tareas como la identificación de cuellos de botella, la monitorización de desviaciones respecto a un proceso ideal o, simplemente, para obtener información.
Mientras que procesos simples se pueden reconstruir sin dificultad puramente con los eventos que generan, una vez se añade la complejidad del mundo real, su descubrimiento se complica considerablemente. Por ejemplo, pueden existir dependencias implícitas entre tareas, que no aparecen en los eventos. A su vez, hay que añadir el ruido que todo proceso en el mundo real genera. Podría ocurrir que en ocasiones muy específicas el proceso sea diferente y, en ese caso, no desearíamos que el proceso de minado tuviera esas rutas de la misma manera que las rutas típicas.
Estas complejidades han llevado a múltiples soluciones para la recreación de procesos, cada una de ellas con sus ventajas y desventajas. En este artículo, nos centraremos en ellas y expondremos un ejemplo práctico.
Process Discovery o Descubrimiento de procesos
Todas las soluciones generan una representación del modelo, que típicamente suele ser una red de Petri o un modelo BPMN. Esto se debe a la capacidad de ambas representaciones gráficas de representar un modelo. Entre los métodos para generar dichos modelos, podemos encontrar algunas de las categorías más populares: Basados en abstracciones, basados en heurísticas y basados en algoritmos genéticos.
Process Discovery – Basados en abstracciones
Con este método se generan un set de reglas derivadas de las relaciones entre las tareas. Por ejemplo, si una tarea está en sucesión directa de otra (x > y), hay una relación de causalidad (x -> y), son paralelas (x||y), o no tienen relación (x#y). Usando estas relaciones, se genera una tabla con la relación de toda tarea a toda otra tarea y después es transformada en un modelo.
De las implementaciones de este método, la más popular es el algoritmo α, pero existen muchas variaciones del mismo como α+, α#, α∗, α++ o β. Todas las diferentes implementaciones buscan representar distintas relaciones que otros no pueden modelar, como son los bucles cortos en α. Por lo tanto, es importante fijarse en qué puede o no modelar cada algoritmo antes de usarlo.
Process Discovery – Basados en heurísticas
Un problema que aparece cuando se minan procesos usando el método de abstracción, es que es extremadamente sensible al ruido. Cualquier ruido podría destruir las relaciones entre las tareas, por lo que esta familia tiene en cuenta la frecuencia del evento y de sus relaciones. De estos algoritmos, los más populares serían Heuristics Miner y su familia de extensiones.
Process Discovery – Basados en algoritmos genéticos
Mientras que los métodos anteriores son capaces de modelar bastantes estructuras de modelos, hay varias construcciones que no pueden hacerlo. Por eso, existe el método genético, que intenta buscar en un espacio global no limitado por asunciones respecto a los datos y sus posibles relaciones. Un ejemplo de algoritmo implementando esta búsqueda sería Genetic Algorithm Miner, que, usando optimización por algoritmo genético, genera una modelo que mejor represente el modelo real subyacente.
El mayor problema con este método es que suele ser exponencial a la cantidad de tareas en el modelo y es afectado considerablemente por la cantidad total de eventos a analizar, siendo poco práctico para grandes logs de eventos.
Ejemplo práctico de Process Discovery
Para el ejemplo práctico, se emplea la librería de Python pm4py y un log de eventos falso creado a mano.
Como caso práctico simple tenemos el siguiente mapa de proceso. Los vértices indican el evento y, entre paréntesis, su frecuencia. Por otro lado, los ejes indican con qué frecuencia lleva a otro evento.

Minando con el algoritmo α obtenemos la siguiente red de Petri, que representa el mapa de proceso anterior perfectamente.

Si, en lugar de minar usando el algoritmo α, lo hacemos con uno heurístico, observamos que es capaz de recrear el mismo proceso solo que añadiendo más tareas implícitas.

En cambio, si añadimos un pequeño bucle al process map, como podemos ver en el siguiente process map, contact_1 lleva a contact_2 de vuelta algunas ocasiones.
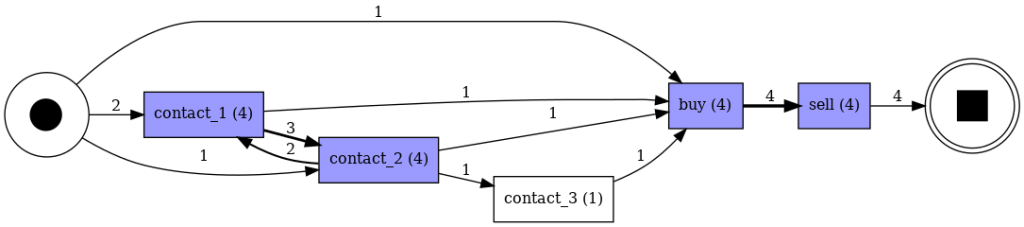
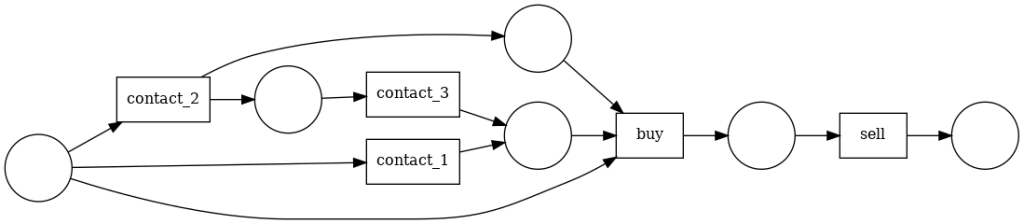
La red de petri obtenida no es capaz de conseguir este bucle.
Sin embargo, el minero de heurística es capaz de encontrar un camino desde contact_1 a contact_2 que genera un bucle. Sin embargo, en el proceso, la red se ha complicado considerablemente.
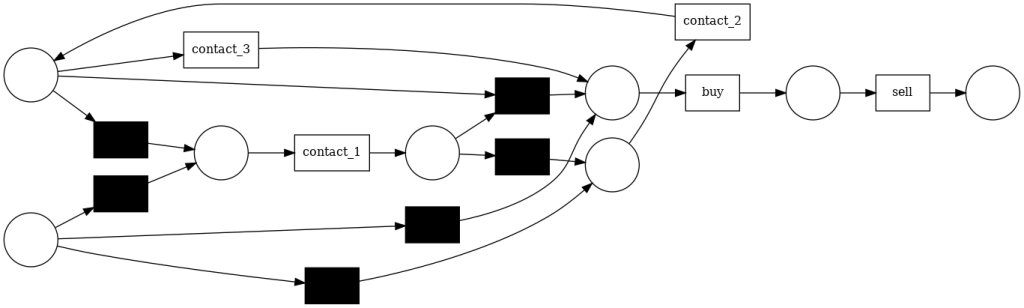
Como podemos ver, el algoritmo apropiado puede capturar diferentes estructuras que otros algoritmos no capturan. Por lo tanto, es necesario probar diferentes algoritmos y tener una idea de las estructuras que el proceso puede tener para modelarlo de una forma apropiada.
Conclusión
Cuando tenemos un log de eventos y queremos obtener información sobre los modelos subyacentes que poseen, debemos recurrir a Process Discovery, pero hemos de tener en cuenta que no todo método puede obtener toda estructura de modelo o que simple ruido puede distorsionarlo considerablemente. Por lo tanto, es necesario un conocimiento sobre los diferentes algoritmos para aplicar el más apropiado.
Bibliografía
A. Medeiros et al. “Process Mining : Extending the -algorithm to Mine
Short Loops”. In: 2004.
Lijie Wen, Jianmin Wang, and Jiaguang Sun. “Mining Invisible Tasks from
Event Logs”. In: Advances in Data and Web Management Lecture Notes
in Computer Science (), pp. 358–365. doi: 10.1007/978-3-540-72524-
4_38.
Jiafei Li, Dayou Liu, and Bo Yang. “Process Mining: Extending -Algorithm
to Mine Duplicate Tasks in Process Logs”. In: Lecture Notes in Computer
Science Advances in Web and Network Technologies, and Information
Management (), pp. 396–407. doi: 10.1007/978-3-540-72909-9_43.
Lijie Wen et al. “Mining process models with non-free-choice constructs”.
In: Data Mining and Knowledge Discovery 15.2 (2007), pp. 145–180. doi:
10.1007/s10618-007-0065-y.
Changrui Ren et al. “A Novel Approach for Process Mining Based on
Event Types”. In: IEEE International Conference on Services Computing
(SCC 2007) (2007). doi: 10.1109/scc.2007.12.
A. Weijters, Wil Aalst, and Alves Medeiros. Process Mining with the
Heuristics Miner-algorithm. Vol. 166. Jan. 2006.
W. M. P. Van Der Aalst, A. K. Alves De Medeiros, and A. J. M. M.
Weijters. “Genetic Process Mining”. In: Applications and Theory of Petri
Nets 2005 Lecture Notes in Computer Science (2005), pp. 48–69. doi:
10.1007/11494744_5.
Si este artículo te ha parecido interesante, te animamos a visitar la categoría Data Science para ver otros posts similares a este y a compartirlo en redes. ¡Hasta pronto!
