
Cuando trabajamos con bases de datos relacionales, es habitual que algunas consultas sean extremadamente lentas. Esto puede deberse a distintos motivos, pero el más común es que el patrón de acceso a los datos que la consulta demanda no es uno que el diseño de la base de datos apoye apropiadamente, como suele ocurrir en consultas que tienen que unir muchas tablas. La segunda causa más frecuente es la falta de índices o su mal diseño, punto que analizaremos en este artículo.
Todos los ejemplos que se mostrarán durante el desarrollo del post son sobre PostgreSQL con datos de muestra.
¿Qué es un índice?
Un índice es una manera de organizar punteros a los datos guardados en la base de datos, de forma que no haga falta leerla al completo para responder queries. Pero, obviamente, existen incontables maneras de organizar dichos datos y cada una de ellas posee sus ventajas e inconvenientes.
Lo más importante a tener en cuenta es que un índice se debe guardar en la propia base de datos, además de mantenerse actualizado para responder a las queries. Por lo tanto, simplemente añadiendo índices, se puede empeorar la base de datos. En este artículo, expondremos cuáles los índices más típicos y las estrategias seguidas para utilizarlos, además de ejemplos del efecto que producen. Todos ellos serán comparados con una query simple que, debido a la falta de índices, genera una lectura secuencial de toda la tabla.

Como ejemplo al que comparar, esta es una query simple con una condición que necesita escanear la tabla entera si no hay índices.
Índice B-Tree
Los índices B-Tree son los índices que las bases de datos relacionales suelen tener por defecto en la clave primaria. Se pueden considerar una extensión de los árboles de búsqueda binarios en los que, en lugar de dos hijos por nodo, pueden tener más. Esto es para optimizar los tiempos de acceso a disco, especialmente en discos duros.
Estos índices guardan el dato ordenado, permitiendo fácilmente todo tipo de consultas. Sin embargo, presentan la limitación de que han de ser re-balanceados de vez en cuando, pues se pueden desbalancear naturalmente además de ocupar una cantidad considerable de espacio.
Existen generalizaciones de los B-Tree, como los GiST (Generalized Search Tree), que permiten indexar cualquier tipo de datos con cualquier operación. Sin embargo, su uso suele requerir crear una implementación.
Creamos el índice como se muestra a continuación:
CREATE INDEX btree ON stocks USING BTREE (symbol);Al utilizar una igualdad, podemos observar que usa el índice (debido a optimizaciones de PostgreSQL, el índice es a su vez empleado para crear un bitmap).

El índice funciona de la misma manera en condiciones que no son de igualdad.
Índice Hash
Un índice por hash solo guarda el hash del campo indicado, lo que permite que el índice sea considerablemente inferior en tamaño y ahorrar rebalanceos. No obstante, ya que solo se guarda el hash, únicamente puede ser utilizado en condiciones de igualdad.
Creamos el índice de la siguiente manera:
CREATE INDEX hash ON stocks USING HASH (symbol);
Si existe una condición de igualdad, el índice se usa sin problemas.

Si no ejecutamos una condición de igualdad, vemos como necesita un scan secuencial.
Índice Multicolumna
Los índices no están limitados a un solo campo, sino que también se pueden definir sobre varios de ellos. Sin embargo, hay que tener en cuenta qué efecto tiene, pues existe un orden en los campos.
Por ejemplo, si definimos un índice sobre (A,B), hacer una consulta que filtre sobre ambos usará el índice y, si solo filtramos por A, también. Pero si solo filtramos por B, este índice no se puede usar.
A continuación, creamos el índice:
CREATE INDEX btree_multi ON stocks USING BTREE (symbol, date);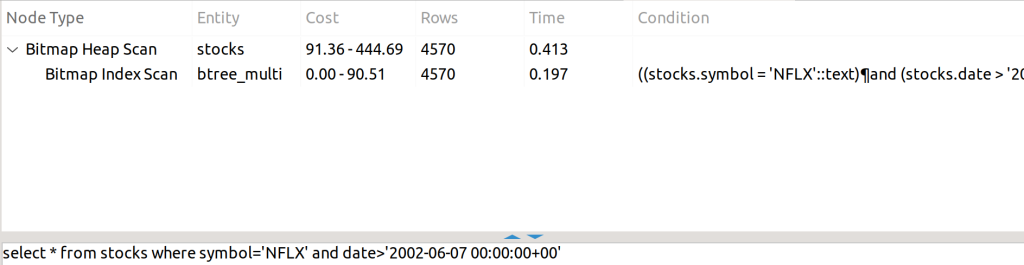
Ambas condiciones se pueden consultar en el índice, por lo tanto, lo usa sin problemas.
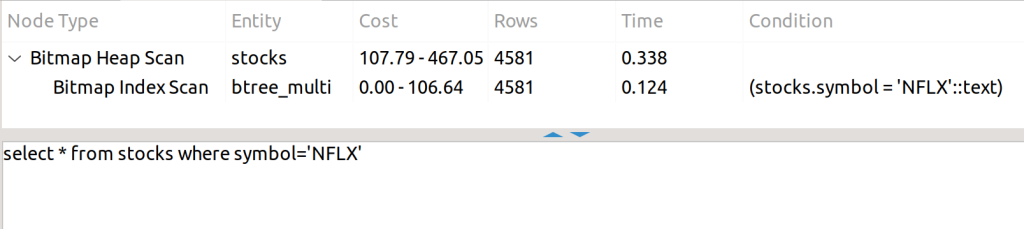
La condición está contenida en el índice, así que puede utilizar.
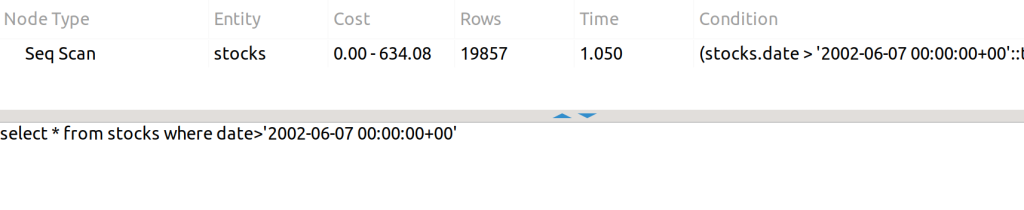
Aunque la condición está incluida en el índice, el orden es erróneo y no es capaz de usar el índice, ya que era (symbol, date) y no podemos preguntar solo por date.
Covering Index
Un caso específico de índice son los “Covering Index”. Se trata de índices de cualquier tipo que contienen toda la información necesaria para responder a la query, de forma que no es necesario acceder a la tabla indexada. Estos índices son óptimos desde el punto de vista de tiempo requerido para procesar una consulta. Sin embargo, presentan la limitación de que normalmente son creados para cubrir ciertas consultas muy críticas, mejorando así el tiempo de ejecución pero ralentizando un poco otros procesos al tener que mantener más índices.
Algunas bases de datos ofrecen apoyo explícito a estos índices como PostgresQL, que permite añadir columnas extras a un índice para transformarlo más fácilmente en un Covering Index.
Seguidamente, creamos el índice:
CREATE INDEX btree_multi ON stocks USING BTREE (symbol, date) include (high);
Dado que todos los datos consultados están presentes en el índice, se puede hacer un scan solo de índice.
Índice de expresiones
A veces tenemos una consulta que aplica una expresión o función específica sobre los datos y los índices normales no se pueden usar. Para este tipo de casos existen los índices con expresiones, que no todas las bases de datos implementan pero que ofrecen mejoras considerables en estas situaciones concretas.

Sin índice, tenemos que ejecutar un scan secuencial de toda la tabla.
Procedemos a crear el índice:
CREATE INDEX btree ON stocks USING BTREE (lower(symbol));
Con el índice, podemos filtrar directamente por la expresión.
Conclusión
Hemos visto que generando los índices apropiados es posible optimizar queries, de forma que solo se accede a los datos deseados reduciendo así tanto el coste como el tiempo de ejecución. No obstante, es importante definir el diseño apropiado de dichos índices teniendo en cuenta qué queries pueden ayudar y cómo han de elaborarse para obtener el mayor beneficio posible.
Si este artículo te ha parecido interesante, te animamos a visitar la categoría Data Engineering para ver otros posts similares a este y a compartirlo en redes. ¡Hasta pronto!
