En este artículo vamos a ver qué es y cómo funciona esta herramienta. Apache Arrow está presente en la mayoría de frameworks de nuestro entorno, como por ejemplo Spark, Dask, Drill, Tensorflow, Kudu, etc. Todos ellos son más antiguos que el propio Arrow y, de hecho, Arrow nace desde la necesidad de optimizar las operaciones con dichos frameworks, sobre todo los de serialización y deserialización. Arrow se lanzó en 2016 y actualmente está entre las herramientas más valoradas y descargadas de la famosa fundación.
¿Qué es Apache Arrow?
Apache Arrow es un formato de datos en memoria. Está diseñado para facilitar el procesamiento de grandes volúmenes de datos, pues está orientado a trabajar con columnas en vez de con filas. Veamos cómo Arrow organiza los datos internamente.
| id | name | surname |
| 1 | oscar | garcia |
| 2 | antonio | navarro |
| 3 | javi | cantón |
Formato de memoria tradicional
Formato memoria Arrow
| 1 |
| oscar |
| garcia |
| 2 |
| antonio |
| navarro |
| 3 |
| javi |
| cantón |
| 1 |
| 2 |
| 3 |
| oscar |
| antonio |
| javi |
| garcia |
| navarro |
| cantón |
En este ejemplo se puede ver la diferencia en cómo se colocan en memoria los distintos buffers de datos según el tipo. El formato tradicional está orientado a trabajar con datos transaccionales, lo que en bases de datos clásicas permite añadir datos al final de los buffers. Además, este enfoque está mucho más orientado a operar con los datos de la fila completa.
Por otro lado, los sistemas columnares están diseñados para trabajar con todos los datos de una columna completa. Una de las grandes ventajas de esta nueva aproximación es que permite operar con grandes volúmenes de datos, realizando operaciones como aritmética, promedios, etc., sobre columnas completas.
Otro gran beneficio es la capacidad de agrupar datos del mismo tipo, algo que favorece enormemente a los algoritmos de compresión. Por ejemplo, si trabajamos con una columna completa de enteros (Integers), los algoritmos de compresión podrán tener un rendimiento mucho mayor en comparación con un conjunto de datos totalmente aleatorio.
¿Qué son las operaciones SIMD?
La agrupación columnar de Arrow hace posible el uso de operaciones SIMD. SIMD proviene de las siglas Single Instruction, Multiple Data (Instrucción Única, Múltiples Datos). Es un modelo de procesamiento utilizado en la arquitectura de hardware para acelerar el rendimiento de ciertos tipos de operaciones, especialmente cuando se trata de grandes volúmenes de datos y paralelos. El concepto detrás de SIMD es que una sola instrucción pueda aplicarse simultáneamente a múltiples elementos de datos. Veamos un ejemplo.
Ejemplo sin SIMD
Suma de dos arrays de números.
Array A = [1, 2, 3, 4]
Array B = [5, 6, 7, 8]
Tradicionalmente, se hace la siguiente operación:
Resultado = [A[0] + B[0], A[1] + B[1], A[2] + B[2], A[3] + B[3]]
En un enfoque tradicional (sin SIMD), sumaría los números uno por uno:
1 + 5 = 6
2 + 6 = 8
3 + 7 = 10
4 + 8 = 12
Al final, el resultado sería el array [6, 8, 10, 12], pero el proceso es secuencial.
Ejemplo SIMD
Con SIMD, en lugar de sumar un par de números a la vez, se cargan todos los números de Array A y Array B en dos registros diferentes, uno para cada array. SIMD procesaría esos registros y sumaría los valores de todos los elementos al mismo tiempo.
[1, 2, 3, 4] + [5, 6, 7, 8] = [6, 8, 10, 12]
El resultado final sería el mismo array [6, 8, 10, 12]. Sin embargo, lo interesante aquí es que todas las sumas se hacen simultáneamente, en lugar de hacerlo una por una. Esto permite que las operaciones sean mucho más rápidas, especialmente cuando se trabaja con conjuntos de datos más grandes.
Multi Framework
Como hemos comentado anteriormente, Apache Arrow está diseñado para integrarse con diferentes frameworks y lenguajes. En este repositorio de github, podemos ver todas implementaciones en los distintos lenguajes de Apache Arrow. Las implementaciones se utilizan para la integración dentro de algunos de los frameworks más famosos.
La razón principal para el uso de este estándar para el tratamiento de grandes volúmenes de datos es que facilita la integración entre sus propios nodos, servicios y otros servicios que trabajen con Arrow.
Lo que se hace es pasar las posiciones de memoria donde se encuentran los datos y al ser todos los interesados conocedor del estándar, podrán leerlos sin ninguna dificultad. Así, se reducen a 0 los tiempos de parseo y transmisión entre servicios.
Formato interno de Apache Arrow
En este apartado analizaremos el formato interno de Apache Arrow. El ejercicio que vamos a realizar lo podréis repetir y explorar por vuestros propios medios. Para ello, solamente necesitamos tener instaladas las librerías de numpy, nanoarrow y pyarrow.

En este ejemplo, creamos un array de integers con algún null.
Si revisamos los buffers del objeto, vemos que aparecen dos buffers.

Estos dos buffers materializan la existencia de dos conceptos que utiliza de manera recurrente Arrow: vailidity bitmap buffer y values buffer.
Validity bitmap buffer
El validity bitmap buffer se encarga de almacenar la información de los valores que son nulos dentro del array. Para ello, genera un array de bits, que no deja de ser un espacio de memoria con una longitud en bytes. Dicha longitud es la del tamaño del array original dividido por 8 y redondeado hacia arriba, de manera que con un ejemplo práctico, si tenemos una columna que se representa como un array de tamaño 9, el bitmap buffer tendrá 2 bytes.
Como cualquier bitmap, representará en forma de máscara qué valores dentro de nuestro array son nulos, de forma que marcará su posición con un 0 en caso de que sean nulos y 1 en caso contrario.
Si inspeccionamos nuestro bitmap buffer del ejemplo, podemos comprobar el contenido.
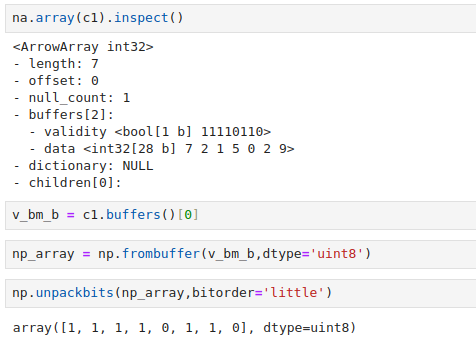
En nuestro ejemplo, vemos que, a pesar de tener 7 valores, la longitud del bitmap buffer es de 8. Esto se debe a la regla que hemos expuesto antes, 7/8 y redondeo a la alza, lo que daría 1 byte, que serían 8 bits. Y donde el último bit no se está utilizando, ya que excede la longitud de los valores, también se marcará como un 0.
Values buffer
Este buffer contiene los valores correspondientes a los datos en un formato contiguo en memoria, lo que permite un acceso eficiente. El formato del buffer varía dependiendo del tipo de datos que contiene la columna (enteros, flotantes, cadenas de texto, etc.).
En nuestro ejemplo, el buffer tiene 28 bytes. Esto se debe a que el tipo de dato es int32, lo cual significa que necesitaremos 4 bytes para almacenar un solo valor. Como tenemos 7 valores, tendremos un buffer de 28 bytes.

Conclusión
Apache Arrow ha revolucionado el procesamiento de grandes volúmenes de datos al ofrecer un formato en memoria altamente eficiente y diseñado específicamente para optimizar el acceso y la manipulación de datos en columnas.
Su integración con operaciones SIMD y la capacidad de estandarizar la comunicación entre diferentes frameworks sin necesidad de costosos procesos de serialización, lo hacen una herramienta clave en el ecosistema moderno de datos.
En esta introducción, hemos visto cómo analizar el formato interno de Arrow y, en futuros posts, exploraremos más tipos de datos y estudiaremos otros escenarios.
¡Eso es todo! Si este artículo te ha resultado interesante, te animamos a visitar la categoría Software para ver todos los posts relacionados y a compartirlo en redes. ¡Hasta pronto!
