
Git es un sistema de control de versiones que se ha convertido en una herramienta esencial para el desarrollo de software. Permite a equipos de desarrolladores trabajar de manera colaborativa sobre el mismo código y gestionar de una forma eficiente el historial de cambios.
En este post haremos una introducción a Git a muy alto nivel. Los temas cubiertos incluyen una guía rápida de instalación y configuración y además veremos cómo crear un repositorio. Por otra parte, también se discutirá brevemente la relación de Git con los procesos de Integración Continua (CI) y Despliegue Continuo (CD) y se explorarán algunos conceptos relacionados con ellos. Por último, se incluirá un glosario de los comandos más utilizados y una pequeña revisión de buenas prácticas en su uso.
¿Qué es Git y por qué es necesario?
Creado por Linus Torvalds en 2005, Git es un sistema de control de versiones distribuido que, desde ese momento, se ha convertido en el estándar de facto de este tipo de herramientas. Como sistema de control de versiones, Git permite llevar la trazabilidad de cambios de los archivos de un proyecto, coordinar ágil y eficientemente el trabajo entre múltiples desarrolladores y revertir esos cambios si fuera necesario.
Aplicado a Git, el adjetivo distribuido se justifica en el hecho de que cada desarrollador tiene una copia completa del repositorio en su máquina, incluido el historial de cambios. El desarrollador en cuestión puede introducir modificaciones en local que, potencialmente, se incorporarán a la versión del código repositada en remoto.
Git y los procesos CI/CD
CI y CD son prácticas que automatizan y hacen más eficientes los procesos de desarrollo de software.
La Integración Continua (CI) consiste en automatizar la integración del código, asegurando que los cambios realizados por los desarrolladores se incorporen frecuentemente al repositorio principal y se prueben de manera automática. Las integraciones se verifican mediante construcciones y pruebas automatizadas (builds y tests). Éstas ayudan a detectar errores de manera rápida y a mantener la calidad del código. Herramientas populares de CI/CD como Jenkins, Travis CI o CircleCI se integran estrechamente con Git para proporcionar estos servicios.
Por otro lado, el Despliegue Continuo (CD) es la extensión natural de la CI. Una vez que el código ha pasado todos los tests, se despliega automáticamente a un entorno de prueba (y luego, eventualmente, en uno de producción). Esto asegura que el software esté siempre en un estado funcional y que los cambios estén disponibles de manera rápida y segura. Herramientas como Docker y Kubernetes a menudo se usan para gestionar y automatizar el proceso de CD.
Como se ha mencionado, en estos procesos de CI/CD, el papel de Git es fundamental en cuanto al hecho de que está muy ligado a la CI. Git hace posible que los cambios se integren continua y efectivamente en el código que va a desplegarse con las herramientas de CD.
Instalación de Git y configuración inicial
Instalación
La forma de instalar Git dependerá del sistema operativo:
En Linux puede utilizarse el gestor de paquetes de la distribución. Por ejemplo, para Debian o Ubuntu:
$ sudo apt-get install gitSi queremos usarlo en macOS, puede instalarse usando Homebrew:
$ brew install gitLos usuarios de Windows tendrán que descargarlo desde Git for Windows y seguir las instrucciones para instalarlo.
Configuración inicial
Tras instalar Git, es importante configurarlo con datos identificativos y de contacto del desarrollador, para que los aportes que haga estén correctamente etiquetados. Esta configuración se establece una sola vez y, a partir de ese momento, se aplicará a todas las actividades de Git en el sistema.
$ git config --global user.name “Nombre Apellido(s)”
$ git config --global user.email “direccion@tuproveedordecorreo.com”Verificamos la configuración:
$ git config --listCreación y configuración de un repositorio
Un repositorio de Git es donde virtualmente se almacena el historial de un proyecto. Se puede crear uno desde cero o clonar uno existente.
Crear uno desde cero es tan sencillo como añadir un nuevo directorio, acceder a él e inicializarlo como repositorio de Git:
$ mkdir myproject
$ cd myproject
$ git initTras ejecutar git init, se creará un subdirectorio llamado .git que contendrá todos los archivos necesarios para que, como tal, sea un repositorio de Git, con ficheros como los de configuración y la base de datos de objetos.
Si lo que se quiere es trabajar en un proyecto existente alojado en un repositorio en Internet (de GitHub o Bitbucket, por mencionar algunos proveedores), tras haberse situado en el repositorio en el que pretende almacenarse, puede clonarse con el comando git clone:
$ git clone https://gitprovider.com/unusuario/unrepositorio.gitAl clonarlo, se descarga una copia completa del historial del proyecto para trabajar con él en local, además de establecerse una conexión con la versión remota del repositorio, cuestión que facilitará la sincronización de cambios.
Glosario y comandos básicos de Git
Git introduce una serie de términos específicos que son esenciales para entender y trabajar eficazmente con él. A continuación, van a revisarse algunos términos y comandos básicos listados en el orden en que pueden circunscribirse a las etapas concretas de la gestión del cambio de Git.
Para una referencia rápida más amplia, esta Cheat Sheet de GitHub puede ser de utilidad en cuanto se tenga algo de soltura con el control de versiones. En todo caso, para una fotografía completa de las diferentes funciones y configuraciones, la documentación oficial es referencia obligada.
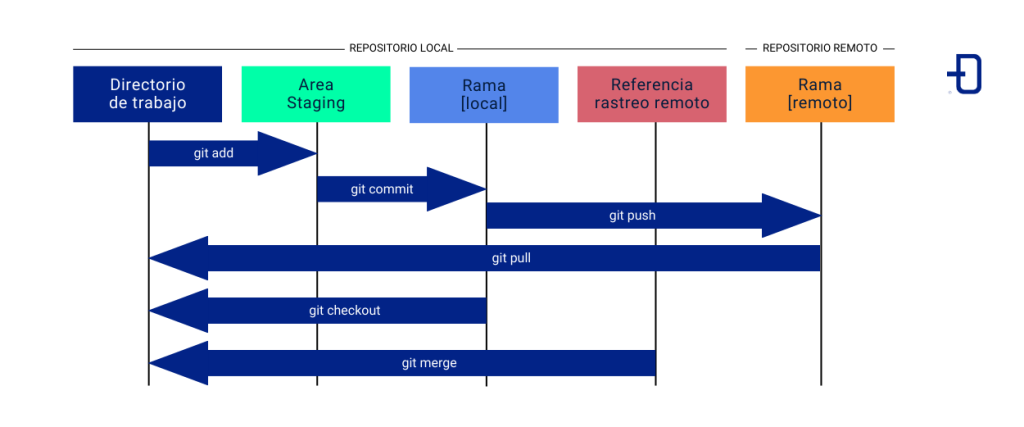
Al hacer un nuevo desarrollo, se están añadiendo o modificando archivos del proyecto situados en el directorio de trabajo (working directory). Véase este proceso como la primera etapa del desarrollo. El objetivo aquí es exclusivamente realizar y revisar cambios en el código antes de prepararlos para su inclusión en el historial del proyecto.
El comando status muestra el estado de los archivos en el directorio de trabajo, indicando cuáles han sido modificados, añadidos o no están bajo seguimiento.
$ git statusCuando el nuevo código está completo y revisado, toca seleccionar los cambios concretos que quieren incorporarse al historial. Esto se llama etapa de preparación y tiene por objetivo controlar qué modificaciones van a confirmarse y cuáles no. Los cambios seleccionados se almacenarán en el área de preparación (área de staging).
Con el uso del comando add se añaden archivos al área de staging.
$ git add <nombre del archivo>
# Añade todos los archivos que no estén bajo seguimiento:
$ git add . La siguiente fase es la etapa de confirmación y su objetivo es mantener un historial claro y descriptivo de los cambios en el proyecto, facilitando el seguimiento y la gestión del código.
Un commit es una instantánea de las modificaciones introducidas en algún momento en un proyecto. Cada uno de ellos guarda un punto en el historial de dicho proyecto con un mensaje descriptivo de los cambios.
$ git commit -m "descripción de los cambios"
# Alternativa recomendable que permite añadir cambios a la vez que se introduce el mensaje:
$ git commit -am "descripción de los cambios" El comando log sirve para mostrar el historial de commits. Es útil para revisar el historial de cambios y encontrar versiones anteriores del código.
$ git logUna rama (branch) es una línea de desarrollo independiente. La organización en ramas permite trabajar en diferentes funcionalidades de manera aislada, sin interferir las unas con las otras.
# Listar, crear o eliminar ramas:
$ git branch Hacer un cambio de rama es tan sencillo como usar el comando checkout:
$ git checkout <rama>
# Crear una nueva rama y situarse sobre ella:
$ git checkout -b <nueva rama> En la etapa de sincronización, se desea mantener el repositorio remoto actualizado con los últimos cambios desarrollados por el equipo. Un repositorio remoto es una versión del proyecto típicamente alojada en Internet.
Si queremos alojar en remoto un repositorio recién creado en local será necesario este comando:
$ git remote add origin <direccion_donde_se_aloja.git>En caso de que deseemos establecer una conexión efectiva entre local y remoto, va a ser necesario obtener tokens de acceso de la plataforma en que se quiera alojar (GitHub, GitLab, etc.). Git los requerirá en cuanto intenten subirse cambios al repositorio remoto.
Por comodidad, se recomienda configurar Git para que recuerde los tokens. Hay varias formas de hacerlo, con distintas alternativas dependiendo también del sistema operativo. En Linux, las más sencillas (y poco seguras) implican el uso de $ git config --global credential.helper con las opciones store o cache para almacenarlas en disco o memoria, respectivamente.
La posibilidad de usar opciones más seguras dependerá también de las opciones ofrecidas por la plataforma en que se quiera alojar el repositorio. GitHub, por ejemplo, permite usar protocolos SSH para autenticarse.
Un push sirve para enviar commits a una rama del repositorio remoto. Esta es una función imprescindible para compartir los cambios con los demás miembros del equipo.
$ git push origin <rama>El comando pull sirve para actualizar el repositorio local con cambios del repositorio remoto. Esta función es necesaria para poder trabajar incorporando las modificaciones que han hecho otros miembros del equipo.
$ git pull origin <rama>En la fase de integración, el objetivo es combinar los cambios de distintos desarrollos.
Un merge sirve para introducir los cambios de cierta rama en la rama actual, por ejemplo, de la rama de desarrollo a la rama principal.
$ git merge <rama desarrollo>
# Después de situarse (con checkout) en la rama principalPosteriormente, el desarrollo entra en las fases de revisión y resolución de conflictos y pruebas y validación, relacionadas con ideas que se verán más extensamente en el punto siguiente. Por último, la etapa de lanzamiento implica desplegar el software en el entorno de producción.
Este proceso habitualmente incluye la creación de tags, usados para señalar versiones del código (entendidas como puntos específicos en el historial de commits).
$ git tag v1.0.0
# Enviar los tags al repositorio remoto:
$ git push origin --tags Buenas prácticas con Git
Para poder sacar el máximo provecho de Git y mantener los proyectos ordenados, es importante seguir algunas buenas prácticas:
- Se recomienda hacer commits frecuentes con cambios pequeños y bien acotados con el fin de facilitar el seguimiento de las modificaciones y la identificación de problemas.
- Escribir mensajes claros y descriptivos ayudará al resto del equipo (incluso a uno mismo, en el futuro) a entender el propósito de cada cambio.
- Es conveniente seguir una política de ramas adecuada.
Política de ramas
El mantenimiento de una política de ramas estructurada es vital para el éxito de cualquier proyecto de desarrollo de software. Es importante porque ayuda a organizar el trabajo y asegura la estabilidad del código. A continuación, se describe una política de ramas muy común que involucra tres ramas principales, además de las ramas feature. Aquí se les llama main, test y develop, pero pueden recibir otros nombres.
Las ramas feature son las que usan los desarrolladores para mantener la rama develop limpia y estable. Una vez que un desarrollo de una rama feature está completo y probado localmente, el desarrollador crea un pull request (PR) donde recibe comentarios de otros miembros del equipo. Tras introducir las mejoras que le fueran requeridas, y volver a revisar el código, cuando los demás miembros aprueban el desarrollo, éste se incorpora a la rama develop.
Por su parte, develop actúa como un entorno de pruebas para que los programadores se aseguren de que todas las nuevas funcionalidades desarrolladas funcionan bien juntas.
En cuanto a test, se utiliza para pruebas específicas y revisiones. Recibe los cambios de la rama develop y, una vez que éstos han pasado las pruebas definidas como necesarias, se fusionan en main.
Main es la rama principal del proyecto y siempre debe contener código estable, listo para operar en un entorno de producción. Se utiliza para lanzar nuevas versiones del software. En ningún caso debería fusionarse código directamente en main sin haber sido probado y aprobado por el equipo. Esta rama debería estar protegida, aunque sea sólo formalmente, para que sean únicamente los responsables del proyecto los que decidan cuándo se incorporan cambios en ella.
Conclusión
Git es un sistema de control de versiones que se ha convertido en casi imprescindible para cualquiera que se dedique al desarrollo de software. En este post, se han cubierto los aspectos básicos para empezar a usar Git desde cero, con una revisión teórica de su lugar en el proceso de CI/CD, de las abstracciones que emplea y de sus comandos más importantes, sin dejar de lado las buenas prácticas que deberían seguirse para asegurar que los proyectos colaborativos se mantengan organizados.
Aunque puede ser intimidante al principio, dominar las funcionalidades básicas de Git tiene muy poca dificultad. Como pasa con cualquier otra tecnología, para controlar sus comandos de uso menos habituales, se requiere explorar su documentación oficial.
¡Eso es todo! Si este artículo te ha resultado interesante, te animamos a visitar la categoría Software para ver otros posts relacionados. ¡Hasta pronto!
