
What is Apache Kafka?
Apache Kafka is an open source distributed event system. It was originally developed by LinkedIn, in order to cover the needs caused by its rapid growth, and moved to a microservices-based infrastructure.
It is also an essential part of Netflix’s real-time data management, which is mainly due to the low latency and fault tolerance derived from its architecture. Moreover, because it is easily scalable, it is very beneficial for this type of business.
Main Apache Kafka components
Let’s discuss more in detail the architecture of Apache Kafka to understand how this streaming system works.
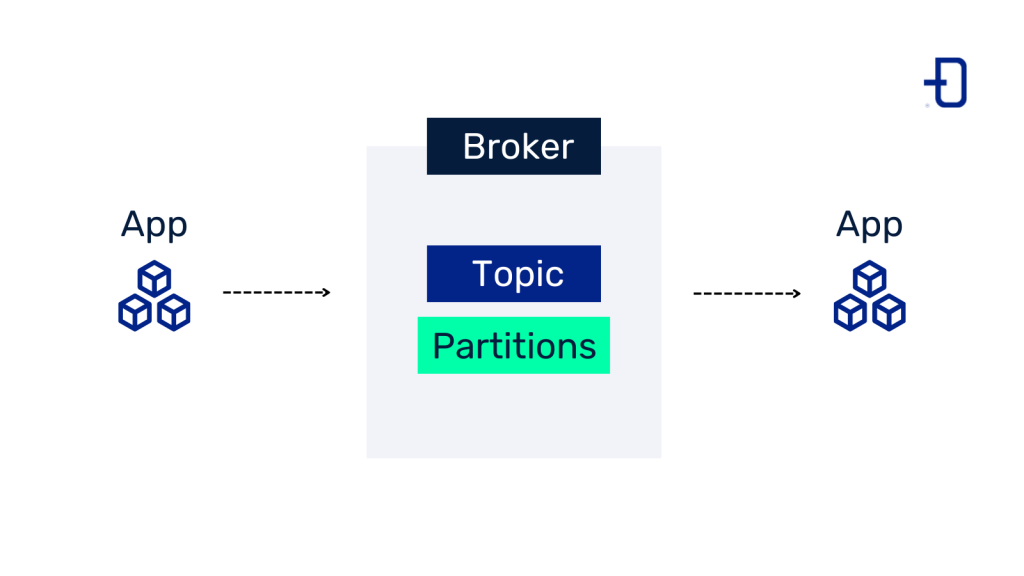
Topics
Topics are nothing more than a flow of data of a certain type associated to a channel with a specific name. In these flows, we will find producers and consumers at each end.
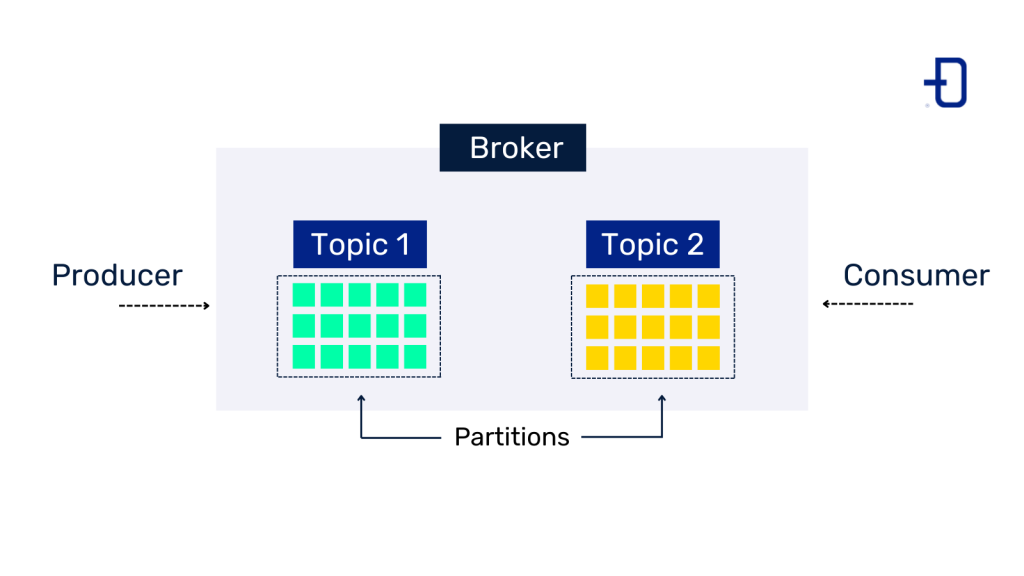
Each topic is divided into a number of parts, known as partitions. The number of partitions is indicated when a topic is created, but can be changed later. Generally, messages sent to a topic will contain a key, which is used to determine which partition a message will fall into. All messages with the same key will go to the same partition and operations such as simple compacts can be performed. If the key is not included in the message, the message will be distributed in a uniform way among the partitions.
To identify each message contained in a partition, it is assigned a unique incremental number within the partition. This number is known as an offset and an older record will have a smaller offset since messages are always added at the end of the partition.
Brokers
A Kafka cluster is made up of one or more servers that are known as brokers, due to the meaning of this term (an individual in charge of arranging transactions between a buyer and a seller for a commission). In the case of Kafka, a broker maintains multiple topics with their respective partitions. In addition, it allows messages to be retrieved by topic name, partition or offset.
Brokers share information between the components of a cluster directly or through an Apache Zookeeper node and, in case of having a cluster, only one of the brokers will act as controller or leader.
Consumers and producers
Any application that reads from a kafka topic will be considered as a consumer. Data is extracted from the server when the application is ready to read it. These consumers can be grouped under a certain name, so that, for example, all components that ingest data to an application from different sources and to different topics are kept under the same name.
As with consumers, any application that writes to a topic will be considered a producer, they will communicate directly with one of the brokers and will be able to specify in which topic and partition they want to include that message.
Apache Kafka use cases
Messaging
Apache Kafka can perform similarly to systems such as RabbitMQ, typically it will have higher capacity, lower latency and higher resilience to failures.
Metrics
Apache Kafka can serve as a central point for collecting all logs from different applications.
Stream processing
Many cases of data transformation can be performed in real time and sequentially. Apache Kafka can be very beneficial in this respect, as it can guarantee that messages are processed at least once or only once. Moreover, since version 0.10.0.0, Kafka already incorporates a stream processing library called Kafka Streams.
On the other hand, many libraries also have modules such as Alpakka for the Akka library. With this model, we could, for example, receive information from a client from several sources, normalise it, leaving the result in a new topic and, subsequently, deduplicate the clients from all the sources.
Advantages and disadvantages
Many of the strengths of Apache Kafka have already been described, such as low latency, resilience to failures, high processing performance and scalability. However, it is worth noting some of the situations where Kafka may not be as convenient.
If an application requires wildcards in topic names, Kafka does not currently support such functionality. Some messaging paradigms are not supported by Kafka, such as point-to-point queues or the request/reply model. Since Kafka compresses messages, this compression and decompression process can be costly for large messages, reducing performance and throughput.
Apache Kakfa potential alternatives
The main alternatives to Apache Kafka are other messaging systems, such as RabbitMQ or ActiveMQ, as open source packages. However, other alternatives such as Red Hat AMQ or the Amazon SQS should also be considered.
If we compare Apache Kafka with a similar product such as RabbitMQ, we will see that the differences in its architecture determine its usefulness in different use cases. For example, Kafka can hold large amounts of data without much overhead, but RabbitMQ’s queues are slower the fuller they are. In addition, we will see that RabbitMQ offers support for messages with different priorities, while Kafka does not.
Conclusion
These are the main concepts needed to understand how Apache Kafka works, however, there are many more details and configuration parameters to explore in their official documentation. We encourage you to follow their quick start guide and try this technology today here.
If you found this article interesting, we encourage you to visit the Software category of our blog to see posts similar to this one and to share it on social networks with all your contacts. Don’t forget to mention us to let us know your opinion @Damavisstudio. See you soon!
