
In cases where it is necessary to model relationships between entities, it is common to use a graph system. The functioning of this type of element is very simple. Its structure consists of entities, represented as nodes, and edges, which represent the type of relationship between those nodes.
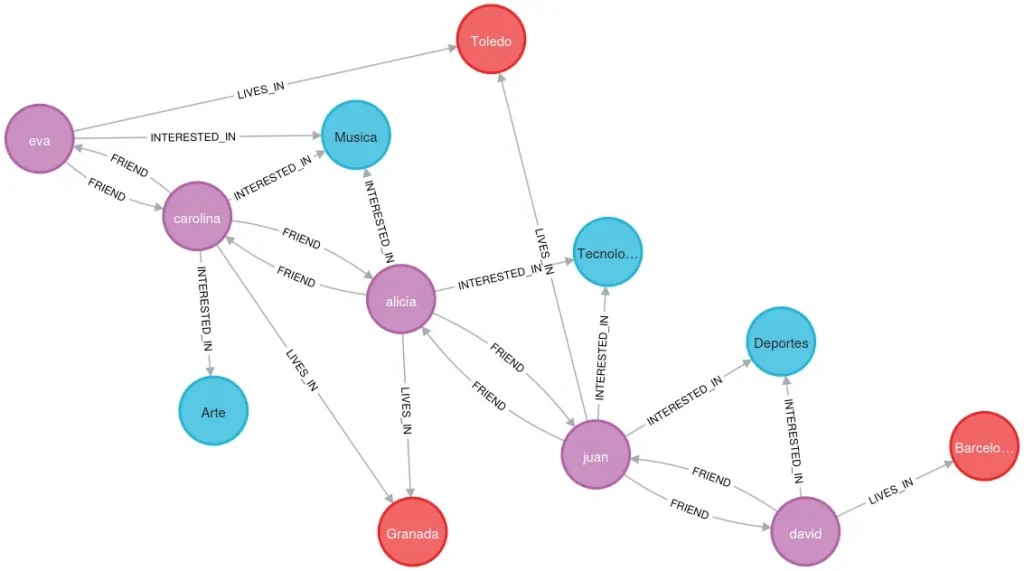
For example, this graph represents the relationship between five friends, their interests, and the cities where they live.
The use of graphs is especially powerful when the relationships between objects are something we want to exploit. For example, we can analyze customer interactions with products and obtain interaction bubbles. That way, we could see that users with property “A” do not usually interact with products “B.”
What are graph databases?
When working with graphs, conventional tabular databases have significant limitations. Given that the main characteristic of graphs is the connections between nodes, specialized databases are needed to store this type of data correctly. Among the most widely used graph databases is Neo4j.
How Neo4j works: Practical example
Next, we will explore some examples of how Neo4j works. To do this, we will use some sample data that can be generated with the following query:
// Create People
CREATE (alicia:Person {name: 'alicia', age: 30})
CREATE (juan:Person {name: 'juan', age: 25})
CREATE (carolina:Person {name: 'carolina', age: 27})
CREATE (david:Person {name: 'david', age: 35})
CREATE (eva:Person {name: 'eva', age: 22})
// Create Friendships
CREATE
(alicia)-[:FRIEND {type:'Close Friend'}]->(juan),
(juan)-[:FRIEND {type:'Friend'}]->(alicia),
(alicia)-[:FRIEND]->(carolina),
(carolina)-[:FRIEND]->(alicia),
(juan)-[:FRIEND]->(david),
(david)-[:FRIEND]->(juan),
(carolina)-[:FRIEND]->(eva),
(eva)-[:FRIEND]->(carolina)
// Add Interests
CREATE (musica:Interest {name: 'Music'})
CREATE (deportes:Interest {name: 'Sports'})
CREATE (tecnologia:Interest {name: 'Technology'})
CREATE (arte:Interest {name: 'Art'})
// Add topic interest
CREATE
(alicia)-[:INTERESTED_IN]->(music),
(alicia)-[:INTERESTED_IN]->(technology),
(juan)-[:INTERESTED_IN]->(sports),
(juan)-[:INTERESTED_IN]->(technology),
(carolina)-[:INTERESTED_IN]->(art),
(carolina)-[:INTERESTED_IN]->(music),
(david)-[:INTERESTED_IN]->(sports),
(eva)-[:INTERESTED_IN]->(music)
//Add cities
CREATE (granada:City {name: 'Granada'})
CREATE (toledo:City {name: 'Toledo'})
CREATE (barcelona:City {name: 'Barcelona'})
CREATE
(alicia)-[:LIVES_IN]->(granada),
(juan)-[:LIVES_IN]->(toledo),
(carolina)-[:LIVES_IN]->(granada),
(david)-[:LIVES_IN]->(barcelona),
(eva)-[:LIVES_IN]->(toledo)Looking at the resulting shape of this graph, we see that it is the same as the example graph shown in the image at the beginning of the post.
If we try to recreate the previous graph in SQL, we need one table per node type and per relationship type. In addition, we would have to apply many joins in each search, which is inefficient in tabular databases. For this reason, when working with graphs, it is better to use a database specialized in them.
What is Cypher and how is it used?
Cypher is the language used in Neo4j to run queries, as the data format is too complex to be represented in SQL. If we wanted to work with this type of data in this way, everything would be JOINS, so using SQL doesn’t make much sense. That’s why Cypher exists, a query language that works on the basis of pattern matching. It’s so simple to use that you just have to define the pattern to search for, and Cypher examines everything that follows that exact pattern.
For example, we can perform basic queries, such as listing all the people created previously:
MATCH (p:Person) RETURN p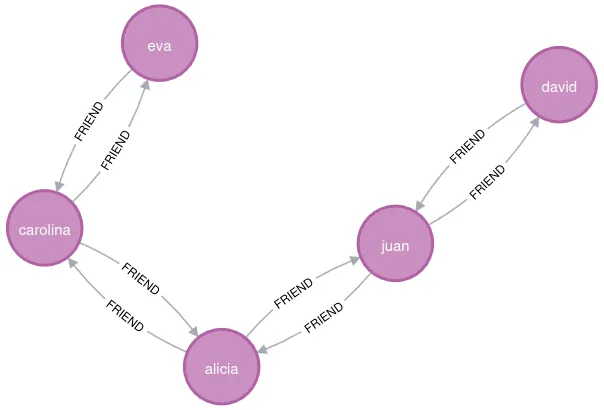
If we wanted to find out all the cities called Barcelona, we could run:
MATCH (c:City {name:'Barcelona'}) RETURN c
On the other hand, it is also possible to ask more complex questions, such as, who are friends with people who live in Granada?
MATCH e=((c:City{name:'Granada'})-[:LIVES_IN]-(p:Person)-[:FRIEND]-(p2:Person)) RETURN e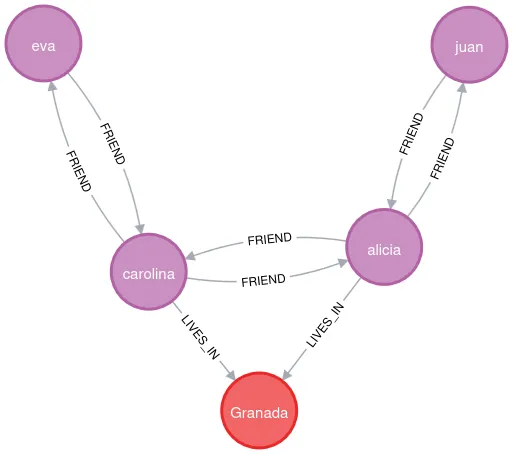
However, these queries are not very complex, nor do they provide much information about the relationships between objects. This is because it is more common to explore certain metrics that we obtain separately from these objects, such as their PageRank, betweenness centrality, or closeness centrality, etc.
Graph databases: Use cases
Graphs are a fundamental mathematical tool for solving a wide variety of problems. In the field of Big Data, graph theory is used in the analysis of complex systems and can be applied to the business world in various ways.
One use case for graph databases is route optimization in the logistics or transportation sector. As we discussed in Graphs, finding optimal routes, graph theory can be used to create a system that finds the optimal route from a starting point to an end point.
Another example of the application of graph theory is in marketing, especially in social media and other online communication platforms. In this area, understanding and knowing as much as possible about the consumer is key. Therefore, having specialized databases that work with graphs to analyze the relationships and connections between users can be a major competitive advantage.
However, logistics, transportation, and marketing are not the only sectors where the integration of graph databases is increasingly making sense. At Damavis, we have already worked on numerous projects whose architecture includes this type of non-relational database. If you would like to learn more about other implementations that can help you work better with your data, we recommend visiting the different services we offer.
Conclusion
In conclusion, graph data requires special databases to work with it. In this sense, graph databases allow you to analyze structure and relationships in a simple way, which would be extremely complicated in classic tabular databases. In this post, we have seen some examples of how to run queries in Cypher with Neo4j to analyze the relationships between different objects.
If you found this article interesting, we encourage you to visit the Data Engineering category to see similar posts to this one and to share it on social networks. See you soon!
