
En un artículo anterior, hicimos una introducción teórica a Spark Structured Streaming donde analizamos en profundidad la API de alto nivel que proporciona Spark para el procesamiento de flujos de datos masivos en tiempo real (Structured Streaming). En él, vimos aquellos conceptos teóricos esenciales para entender cómo funciona esta API, estableciendo la base suficiente para poder dar un paso adelante hacia una primera implementación práctica.
Esta vez, se pretende afrontar una segunda toma de contacto con esta interfaz desde un punto de vista práctico, presentando dos ejemplos sencillos que permitan al lector tener la confianza suficiente para lanzarse a implementar su primer pipeline de procesamiento del dato en streaming con Spark.
Datos de ejemplo
De cara a afianzar los conceptos teóricos ya vistos en Structured Streaming, se van a exponer dos ejemplos prácticos en los que se intentará condensar todo lo esencial. Para esto, se presentan dos ficheros CSV que contendrán el dato que procesaremos en nuestros ejemplos prácticos:
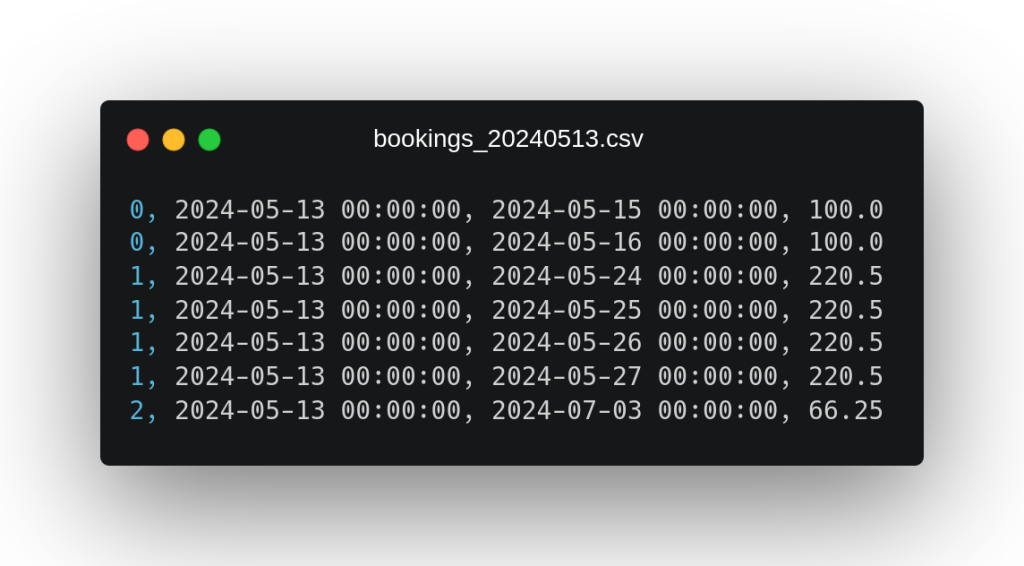
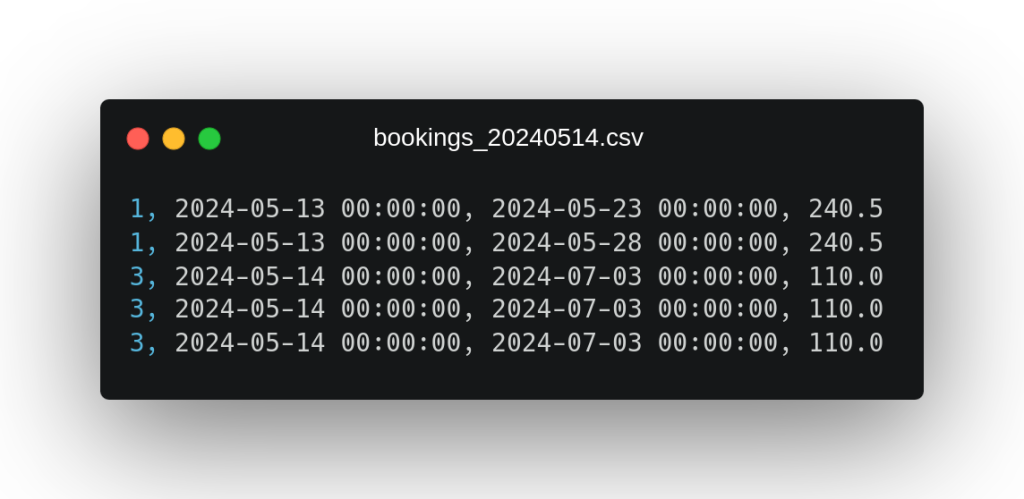
Estos ficheros contienen datos sobre reservas de hotel explotadas por día de estancia, de las cuales disponemos (en el orden en el que aparecen los campos en el fichero) de su identificador, su fecha de reserva, el día de estancia y el precio. Como anotación adicional sobre estos datos, podemos observar que en el segundo fichero vuelve a aparecer una reserva del primer fichero con identificador 1, la cual parece que se ha visto modificada añadiendo nuevos días de estancia.
Ejemplo Práctico 1 – Caso base sin agregaciones
A partir de estos ficheros de ejemplo, se plantea como caso práctico desarrollar una ETL sencilla que lea en streaming los ficheros con este formato que sean depositados en un directorio del sistema de ficheros local, les añada ciertos campos procesados y escriba el resultado en streaming en un sumidero cualquiera. Para afrontar este escenario, se plantea el código en Scala de la siguiente imagen:
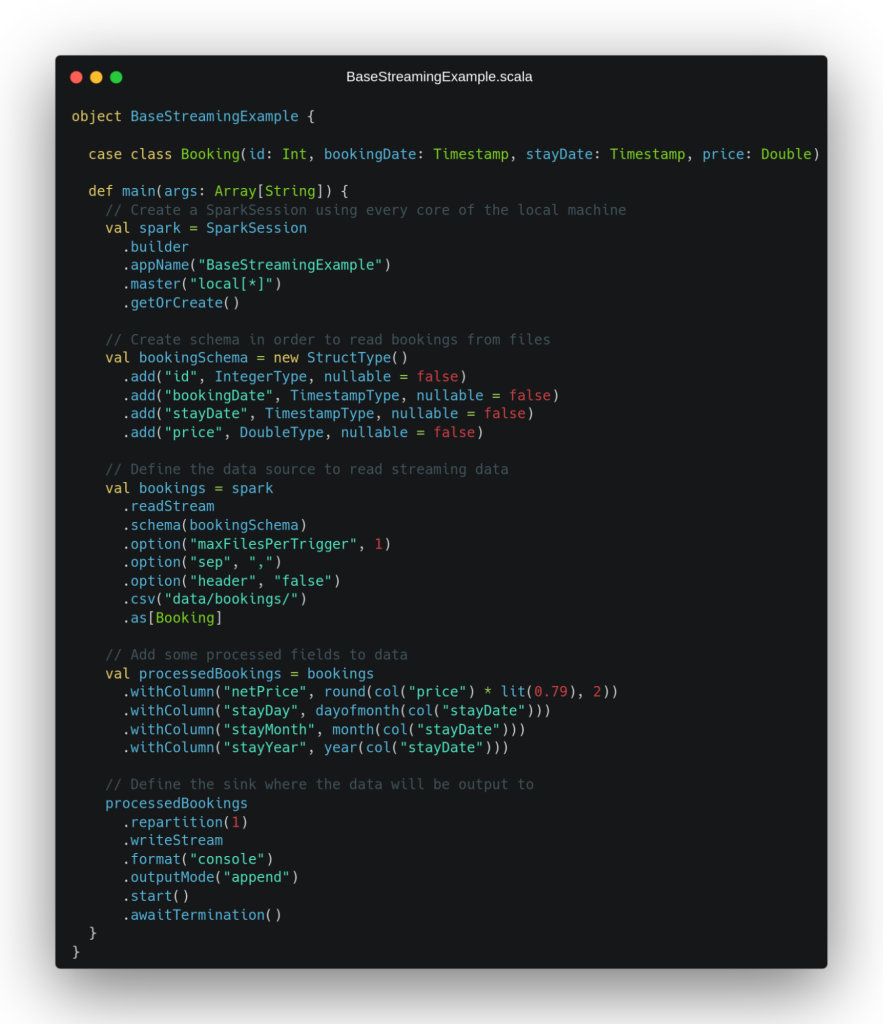
En este ejemplo, podemos ver cómo en las primeras líneas instanciamos la aplicación de Spark y definimos el esquema de datos que utilizaremos para leer de los ficheros CSV. Después, pasamos a establecer la fuente de datos que nos proveerá de un flujo de datos que procesar, que tal y como hemos comentado en este caso, será una fuente de datos de tipo fichero. En las opciones que especificamos a la hora de definir esta fuente de datos, podemos observar cómo se define una configuración maxFilePerTrigger que limitará el número de ficheros que se leen por mini-batch al leer en streaming a 1.
Esta configuración ha sido definida por motivos didácticos, con el fin de que el sistema considere ambos ficheros dados como entrada en mini-batches diferentes de nuestro streaming y, de esta forma, ver mejor cómo se comportaría el pipeline en un caso de uso real en el que un fichero llegase después que otro. Tras definir la fuente de datos en streaming, se procede a realizar algunas operaciones que añaden campos procesados al conjunto de datos obtenido como entrada al pipeline, añadiendo el precio neto y algunos campos temporales extraídos de la fecha de día de estancia.
Por último, se define el sumidero en el que escribiremos el dato una vez haya sido procesado en streaming que, en este caso (de nuevo con fines didácticos), será una salida por consola con el modo de salida “append”. En la definición de este sumidero podemos observar que se hace una sentencia repartition(1) de cara a escribir un único fichero con todo el dato procesado. Al ejecutar este código con el dato presentado con anterioridad, obtenemos por consola la siguiente salida:
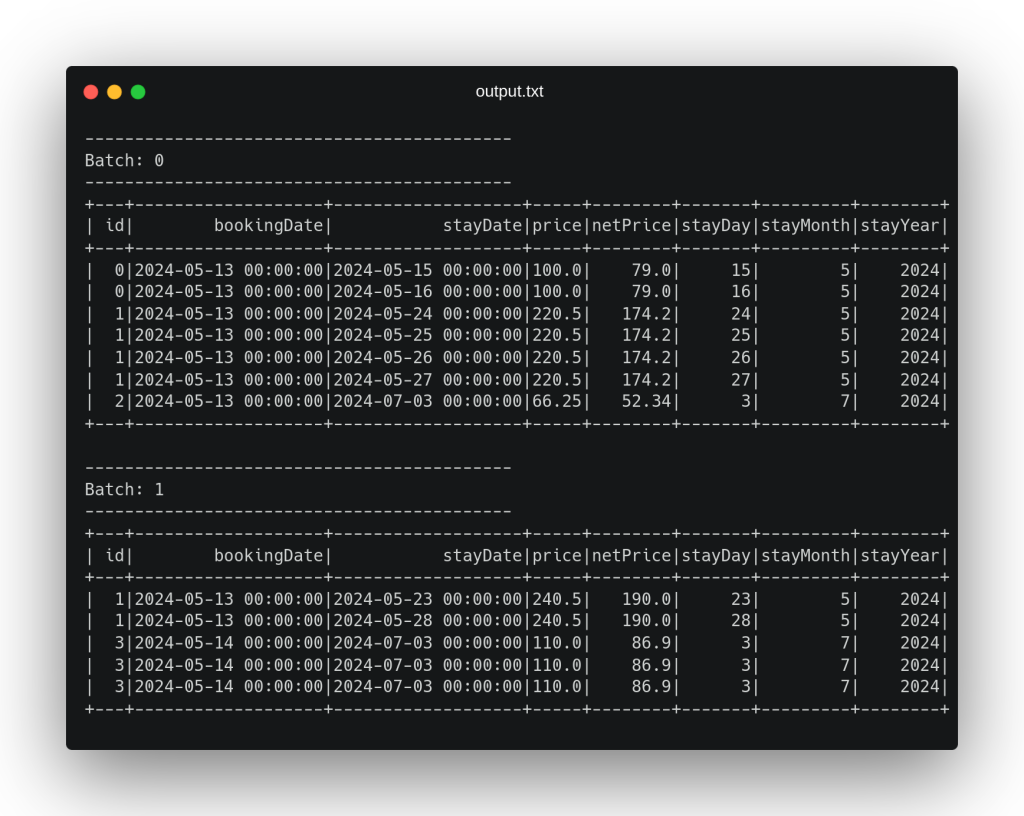
En esta salida podemos observar cómo cada fichero ha sido considerado en un mini-batch diferente, añadiendo a cada registro los campos procesados correspondientes y emitiendo en la salida un registro resultado por cada registro recibido en streaming como entrada. Tras procesar estos dos ficheros, el pipeline se queda a la espera de recibir nuevos ficheros en el directorio establecido como ruta de entrada hasta que se termine la ejecución de forma externa, gracias a la última línea de código .awaitTermination().
Ejemplo Práctico 2 – Caso más complejo con agregaciones y estado interno
Tras este primer ejemplo sencillo, se plantea un escenario más complejo partiendo de los mismos datos de entrada. En este segundo caso, queremos obtener el primer día de estancia y el precio total de cada reserva completa (considerando el precio de cada uno de sus días de estancia). Para esto, tendremos que realizar una agrupación por reserva, lo cual sabemos que implica tener que almacenar un estado interno, que Spark manejará para nosotros de forma automática. Para poner solución a este escenario, se plantea el código de la siguiente imagen:
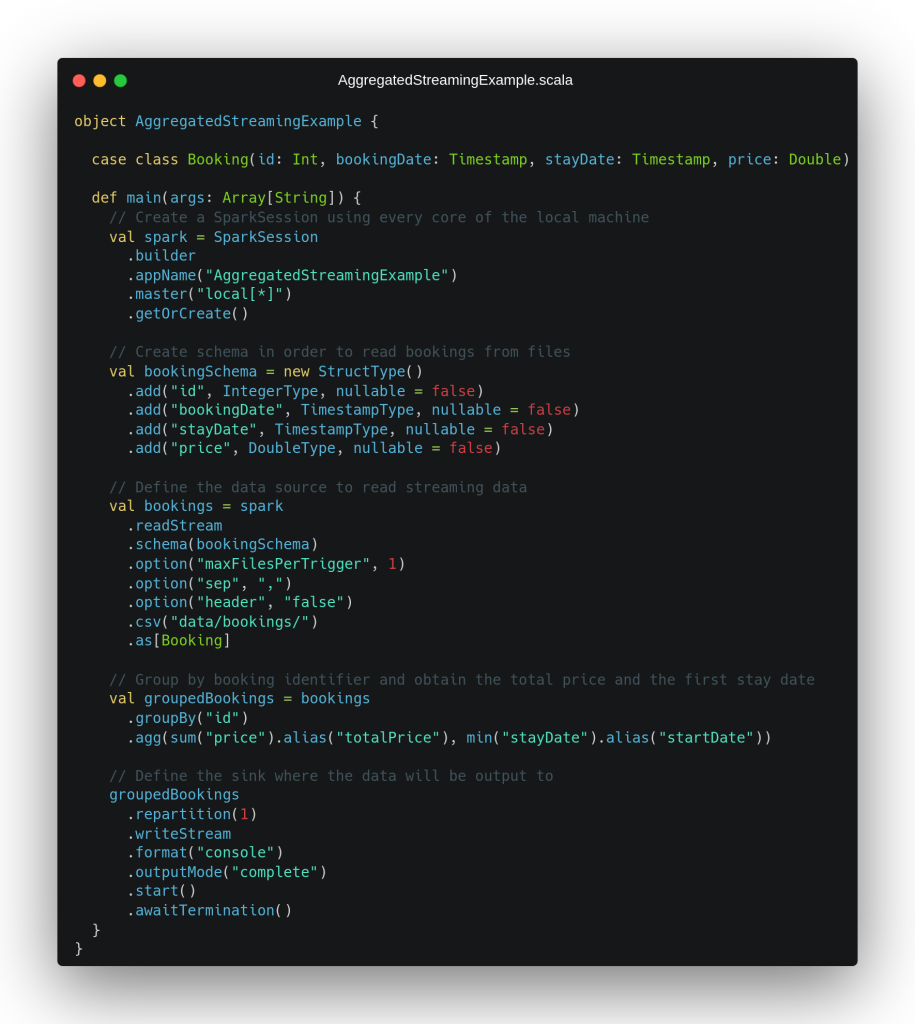
Las primeras líneas de este segundo escenario son idénticas a lo que veníamos viendo en el ejemplo anterior, incluida la definición de la fuente de datos en streaming que no ha cambiado puesto que seguimos teniendo el mismo dato de entrada. Tras esto, observamos cómo el dato es agrupado por el identificador de la reserva para, posteriormente, obtener una suma del campo precio para todos los días de estancia y el primer día de estancia en formato timestamp mediante el uso de la operación min.
Después de este proceso, vemos la definición del sumidero de datos, donde se puede observar que se ha cambiado el modo de salida al modo completo, de cara a producir como salida todas las reservas procesadas hasta el momento cada vez que nos llegue nuevo dato, independientemente de si han sido cambiadas, para poder observar mejor qué está ocurriendo por debajo. Al ejecutar este fragmento de código, obtenemos la siguiente salida por pantalla:
Como podemos ver en la salida, al procesar el primer fichero se determina que la reserva con identificador 1 tiene un precio total de 882€ y una fecha de inicio del 2024-05-24. Recordemos que en el segundo fichero venía una actualización de esta reserva en la que se añadían dos días de estancia más, y, como podemos ver, al procesar este segundo fichero, ha considerado para calcular la agregación tanto el dato previamente procesado en el primer fichero como las actualizaciones nuevas que han llegado en el segundo, incrementando el precio total a los 1363€ y cambiando la fecha de inicio.
Esto se debe a que Spark por debajo ha almacenado un estado interno de esta agregación para considerar el dato previamente procesado cuando nos llega nuevo dato en nuestro streaming, obteniendo de esta forma la agregación correcta al considerar todo el dato en conjunto. Además, si vemos el código, podemos ver cómo no existe ninguna referencia a dicho estado interno, ya que Spark se encarga de este al definir una agregación en el procesado de nuestro dato.
Conclusión
En este post se han visto dos casos prácticos sencillos en los que se hace uso Spark para procesar un conjunto de datos ficticio en streaming. En el primero, se ha observado un escenario simple en el que no existen agregaciones en el dato, solamente se hace un procesamiento sencillo para posteriormente escribir el flujo de datos continuo en otro sitio.
Por otro lado, en el segundo ejemplo, se ha visto un caso de uso más complejo, en el que, al existir agregaciones en el dato, Spark se ve forzado a guardar una representación interna del dato agregado con anterioridad, devolviendo resultados coherentes y robustos en un contexto en streaming.
¡Esto es todo! Si este artículo te ha parecido interesante, te animamos a visitar la categoría Data Engineering para ver todos los posts relacionados y a compartirlo en redes. ¡Hasta pronto!
