
BigQuery se ha convertido en los últimos años en una potente herramienta de almacenamiento y análisis de datos en la nube. Su tamaño, escalabilidad y todas las características que ofrece, serían por coste y logística difícilmente replicables por un usuario o empresa que quisieran hacerlo desde cero. Además de que todo el mantenimiento y gestión corre del lado de Google.
Como cualquier otro servicio en la nube, en este caso una plataforma como servicio (PaaS), uno de los aspectos en los que se debe poner especial atención de cara a sacar el máximo beneficio del mismo será conocer su coste y facturación.
Durante este post, analizaremos y daremos algunos consejos que nos ayudarán a tener un mayor control sobre estos costes, así como para mejorar el rendimiento de nuestras consultas en algunos casos.
Facturación en BigQuery
Para empezar, los cobros de esta plataforma pueden venir desde dos puntos distintos: en primer lugar, habrá una facturación por el almacenamiento de los datos como tal y, por otra parte, por los costes derivados del procesamiento de los mismos.
En cuanto al almacenamiento, podremos optar por diferentes métodos. En este caso, nos centraremos en la facturación “ON-DEMAND”, si queremos hacer cálculos lo más aproximados posibles, Google ofrece una calculadora online que nos puede ayudar a hacer una estimación de costes rápidamente.
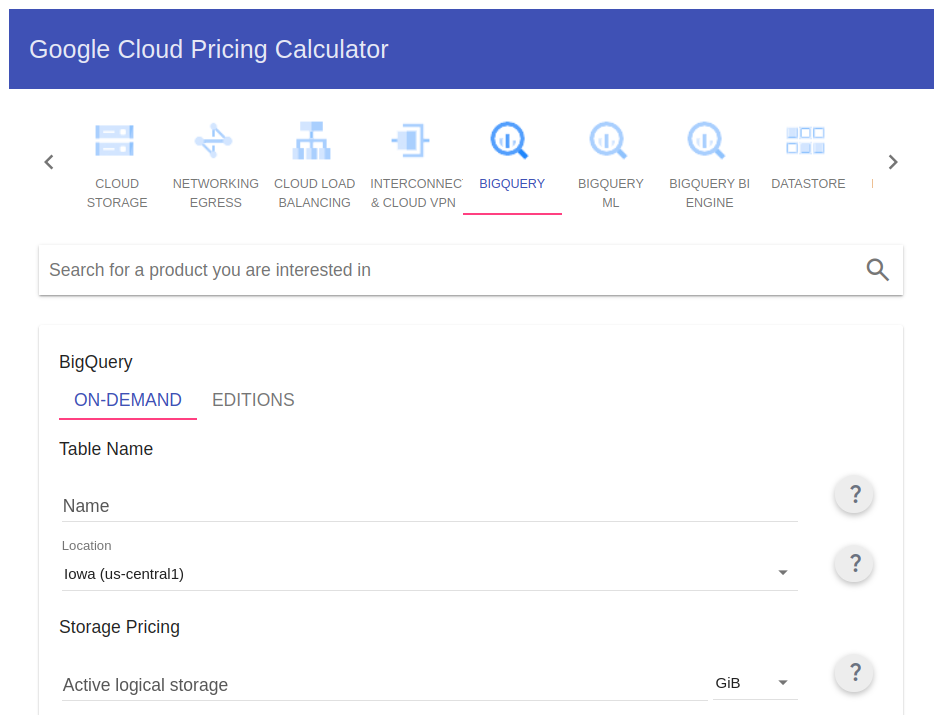
En términos generales, estos precios oscilan en torno a los 20$ por TB (0,025$/GB) almacenados mensuales.
En lo relativo al procesamiento, el precio ON-DEMAND, se sitúa en torno a los 5$ por TB procesado (el primer TB mensual es gratuito). Y es aquí donde nos centraremos, en algunas prácticas recomendadas para reducir esta cantidad de datos procesados durante nuestras consultas.
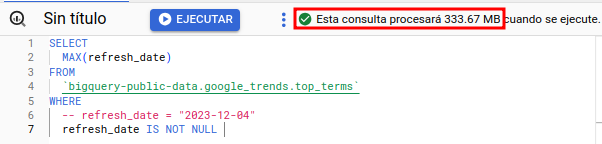
Durante la ejecución de las mismas, la interfaz de BigQuery nos informará de los datos que se van a procesar y será un punto a tener en cuenta antes de lanzar nuestras consultas.
Exploración de datos
De cara a explorar nuestros datos, sobre una BD convencional se tienden a realizar algunas prácticas que en BigQuery no serán óptimas, especialmente derivadas de su coste. Un claro ejemplo es hacer consultas del tipo:
SELECT * FROM `dataset.table_name`A nivel estructural, BigQuery almacena los datos a nivel de columnas, esto es, procesará (y facturará), únicamente las columnas que seleccionamos. Por lo tanto para evitar costes adicionales será recomendable seleccionar lo estrictamente necesario. A continuación podemos ver una comparativa:

También deberemos tener en cuenta, de cara a la exploración de los datos, que BigQuery nos aporta herramientas de visualización de los mismos que pueden evitar generar costes adicionales. Por ejemplo, si queremos analizar una muestra de los datos será conveniente usar la previsualización de los mismos en vez de ejecutar una sentencia de tipo:
SELECT * FROM `dataset.table_name` LIMIT 10Ya que en algunos casos como el que se muestra a continuación, se procesaría el total de la tabla pese a querer un pequeño conjunto de registros. A continuación podemos ver como el hecho de indicar un LIMIT de los registros, no afecta a la cantidad de datos procesados.
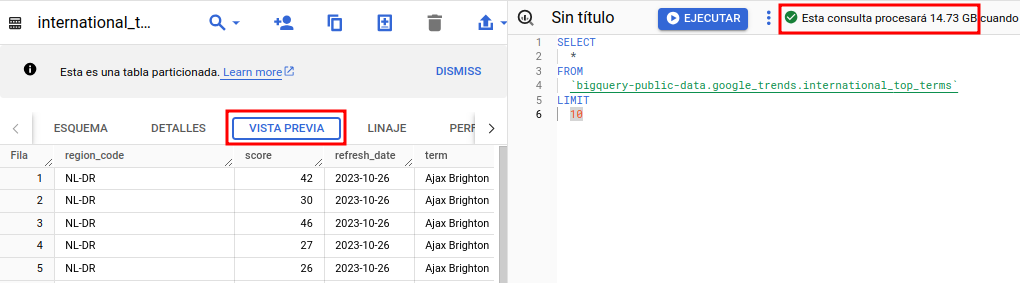
Esta vista previa es totalmente gratuita y junto con las pestañas de detalles o esquema, nos pueden dar suficiente información sobre lo que contiene la tabla y sus características sin necesidad de hacer consultas con un coste asociado.
Creación y replicación de tablas
Otra de las tareas que podemos realizar en nuestro día a día son el traspaso de datos entre tablas. En ocasiones se requiere de una copia exacta de estos datos a modo de snapshot o para la realización de test por separado, podríamos pensar en hacer esto de la siguiente manera:
CREATE OR REPLACE TABLE
`project_name.data_test_blog.data_mobile_test_no_cluster`
AS
SELECT
*
FROM
`bigquery-public-data.catalonian_mobile_coverage_eu.mobile_data_2015_2017`Pese a que esta consulta es perfectamente válida, y puede cumplir su función, BigQuery nos permite realizar este tipo de operaciones de diversas formas en función de nuestras necesidades, y en muchas ocasiones, sin coste alguno asociado.
Uno de los casos más triviales y que tendrán el mismo efecto que la consulta que acabamos de ver sería el método COPY. Esto nos permitirá no sólo copiar el contenido, sino que además también copiará la metadata asociada a la tabla, particionamientos, clustering, etc.

En otros casos, podremos recurrir incluso a una operación de menor coste aún, la clonación de la tabla. Para ello, de nuevo se realizará una copia completa de los datos y metadatos de la tabla original, además tampoco tendrá coste de almacenamiento asociado al menos para aquellos registros que se mantengan iguales a la tabla original. Esto puede ser interesante cuando es necesario un backup o para realizar trabajos separados sobre la misma tabla. A continuación, podemos ver un ejemplo de cómo será la creación de uno de estos clones.
CREATE OR REPLACE TABLE
`data_test_blog.data_mobile_test_cluster_CLON` CLONE `data_test_blog.data_mobile_test_cluster`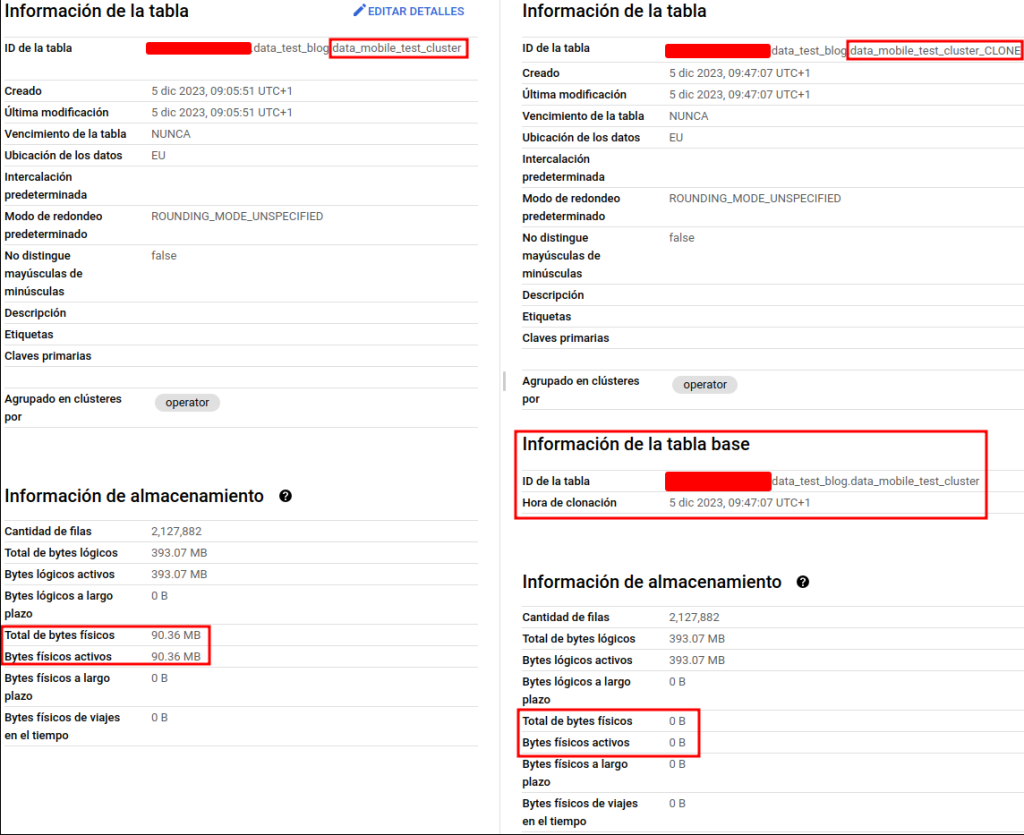
Otra opción disponible, similar a las tablas clonadas, es la de generar snapshots (de algún punto en los últimos 7 días) sobre una tabla base, de nuevo no hay coste asociado a la consulta o almacenamiento. Estas tablas tienen la característica de ser más ligeras en cuanto al procesamiento sobre ellas, eso sí, son inmutables.
CREATE SNAPSHOT TABLE
`data_test_blog.data_mobile_test_cluster_SNAPSHOT` CLONE `data_test_blog.data_mobile_test_cluster` FOR SYSTEM_TIME AS OF TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 1 day)El uso de todas estas alternativas para la replicación de datos deberán ser cuidadosamente estudiadas en función de las necesidades del caso, ya que algunas de estas tablas no se comportan como lo harían tablas creadas de manera convencional.
Particionamiento y clustering
En cuanto a la estructura de las tablas, deberemos intentar que éstas aporten todas las facilidades posibles a la hora de interactuar con ellas, para que los costes sean también menores. Dos técnicas a considerar serán el clustering y el particionado.
De manera similar a lo comentado en el inicio del post en cuanto al almacenamiento por columnas, podremos indicar en la creación de las tablas si queremos que estén particionadas de alguna forma, lo que significa que BigQuery las tratará como bloques separados internamente estando estos distintos fragmentos indexados. Esto se traduce en que si filtramos por este campo, BigQuery no necesitará acceder al completo de los datos, ya que indexará de manera directa el fragmento requerido.
A continuación, podemos observar la comparativa entre una tabla sin particionar y la misma particionada por un campo date:

Esto tiene sus limitaciones y solo se puede realizar sobre determinados tipos de columnas, normalmente sobre campos de tipos DATE o INTEGER.
El particionamiento de estas tablas también nos ofrece otras facilidades y reducción de costes relacionados con su particionamiento. Un ejemplo es el borrado de particiones:

Este tipo de borrado de particiones no solo tiene una ventaja en cuanto a coste, sino que también, al estar ese bloque guardado internamente de manera independiente, no requiere que el resto de la tabla sea reorganizada en alguna forma, como sí sería necesario si borramos registros contiguos.
Por otro lado, se puede aplicar clustering a la creación de las tablas, lo cual nos aportará la capacidad de ordenar internamente la misma a partir de un campo deseado, esto es, los registros que tengan un valor igual para el campo en el que se realiza el clustering, se situarán de manera adyacente en la tabla. Este proceso puede ser especialmente útil si agrupamos u ordenamos frecuentemente por dicho campo, ya que el coste en cuanto a tiempo y cómputo será mucho menor. Esto es debido a que BigQuery solo accedería a ese fragmento de la tabla, ya que guarda metadatos sobre dónde comienzan y terminan dichos clusters.
En la mayoría de ocasiones, si se quiere utilizar este método, es interesante realizarlo en conjunto con el particionado.
A continuación, podemos ver un ejemplo de una tabla creada con un clustering sobre uno de sus campos, además en esta ocasión usaremos otra de las herramientas aportadas por BigQuery tras la ejecución:
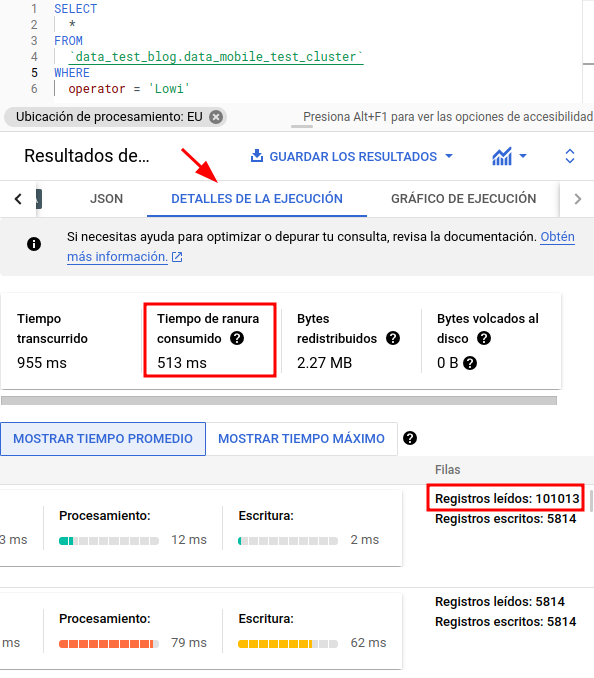
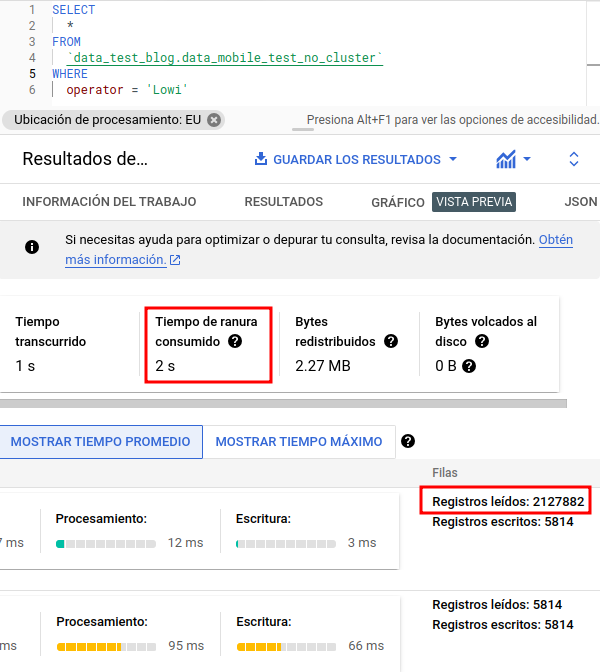
En este caso, tras realizar la ejecución del script, nos hemos dirigido al apartado “Detalles de ejecución” que, junto con el gráfico de ejecución, nos ayudará a analizar el comportamiento de nuestras consultas.
Podremos analizar el consumo de slots (recurso asignado por BQ para el procesamiento), tiempos de ejecución, registros leídos, etc.
Aquí podemos observar que, pese que el tiempo de ejecución es similar (estamos tratando un dataset pequeño), sí observamos que el tiempo consumido de slot es mucho mayor, así como la cantidad de registros accedida.
Conclusión
Si bien este tipo de plataformas nos ofrece de manera sencilla un gran conjunto de posibilidades, rendimiento y coste, solo serán óptimos si prestamos atención a todos aquellos detalles que están en nuestra mano. En este post hemos visto algunos de ellos que si se siguen pueden marcar la diferencia.
Si este artículo te ha parecido interesante, te animamos a visitar la categoría Data Engineering para ver otros posts similares a este y a compartirlo en redes. ¡Hasta pronto!
