
Apache NiFi es una tecnología con mucho potencial para trabajar con grandes volúmenes de datos desde diferentes fuentes. Realiza la extracción, transformación y carga de los datos de manera eficiente y escalable, lo que la convierte en una completa herramienta que abarca las tres fases del Big Data.
A continuación, vamos a definir los aspectos clave para entender de forma teórica en qué consiste y sus componentes principales. Una serie de buenas prácticas nos guiarán para crear flujos de calidad desde el principio de nuestro aprendizaje. Finalmente, nos iniciaremos con la herramienta a través de un ejemplo sencillo.
¿Qué es Apache NiFi?
Apache NiFi es una herramienta para la extracción, el procesamiento y la distribución de datos integrados en tiempo real. Su objetivo principal es facilitar el movimiento de los datos entre diferentes sistemas y realizar transformaciones sobre éstos mientras fluyen.
Por otro lado, NiFi se basa en Flow Based Programming (FBP). Este paradigma define aplicaciones como flujos de procesos de caja negra que intercambian datos a través de conexiones predefinidas por transferencia de mensajes. Dichas conexiones se especifican externamente a los procesos. Estos procesos de caja negra se pueden conectar indefinidamente para formar diferentes aplicaciones sin tener que ser cargadas internamente.
Asimismo, NiFi se puede entender como una agrupación de elementos atómicos (grupos de procesos y procesadores) que pueden combinarse para construir un flujo de datos.
Componentes principales de Apache NiFi
- FlowFiles: son registros que representan los objetos en movimiento a través del sistema. Se caracterizan por ser mutables a lo largo del flujo y pueden ser divididos o fusionados con otros FlowFiles. Su estructura se divide en:
- Contenido: es el conjunto de datos reales que se están procesando.
- Atributos: son las características asociadas al FlowFile, que proporcionan información o contexto sobre los datos (metadatos). Están almacenados en pares clave-valor y los más importantes son:
- uuid: identificador del FlowFile.
- filename: nombre del archivo.
- ruta: lugar donde se almacenan los datos en disco.
- Procesadores: son elementos atómicos que tienen la capacidad de realizar diversas tareas. Por ejemplo, la adquisición de datos de diversas fuentes, publicar datos en entornos externos y enrutar, transformar o extraer información de FlowFiles. En la actualidad, pueden existir alrededor de 300 procesadores, abarcando un gran espectro de funcionalidades. Además, NiFi permite la creación de procesadores customizados. Se dividen en dos tipos:
- Fuentes (entradas): se encargan de extraer o recibir datos desde distintos orígenes y convertirlos en FlowFiles.
- Sumideros (salidas): su tarea es enviar los datos procesados al destino final.
- Grupos de procesos: son la agrupación de varios procesadores.
- Conexiones: es la unión entre componentes (elementos de creación arrastrables desde la barra de NiFi al lienzo, como procesadores o grupos de procesadores). Posee una cola, lugar donde se irán almacenando temporalmente los FlowFiles activos hasta que el siguiente procesador pueda procesarlos.
- Relaciones: son etiquetas que se emplean dentro de los procesadores para especificar cómo enrutar los FlowFiles, dependiendo de su procesamiento. Las más comunes son success, retry, failure, original y unmatched.
- Controladores: permite conocer cómo se conectan los procesos y gestiona los hilos y sus asignaciones, empleadas por todos los procesos.
Apache NiFi: Mejores prácticas
A continuación, veremos algunas de las mejores prácticas a tener en cuenta a la hora de trabajar con NiFi para crear flujos de datos optimizados, gestionar errores y asegurar el sistema.
- Definir flujos de datos sencillos y concretos: es buena idea modularizar los flujos según la funcionalidad que se pretenda abordar. De esta forma, se puede evitar que obtengamos flujos gigantes monolíticos y difíciles de gestionar.
- Nombrar los procesadores: dado que es recurrente el empleo de un mismo procesador dentro del mismo canvas (en ocasiones, incluso dentro del mismo flujo de trabajo), es crucial tener una forma de diferenciarlos entre sí.
- Evitar dependencias innecesarias: debemos usar conectores con sistemas de cola entre procesadores. De esta forma, en caso de error en un sistema (por ejemplo, de recolección de datos) que obligue a detener el flujo, todos aquellos procesos intermedios que puedan realizarse sin conexión, continúen. Pasarán los resultados a cola para enviarse cuando vuelva la conexión.
- No abusar de controladores de estado: se pueden usar en algunos procesadores para almacenar información internamente y usarla más adelante. Pero hay que tener en mente que hacerlo puede reducir tanto el rendimiento como la escalabilidad.
- Optimizar el tamaño de los FlowFiles: es posible ajustar el tamaño de los FlowFiles. Sin embargo, no debe ser ni demasiado pequeño (para evitar la sobrecarga), ni demasiado grande (alto consumo de memoria y un punto enorme de fallo).
- Optimizar el rendimiento de procesamiento: es buena idea ajustar la paralelización del procesamiento según la carga de trabajo asignando un número de hilos adecuado.
- Emplear Grupos de Procesos Remotos: son componentes de NiFi que permiten enviar y recibir FlowFiles entre diferentes instancias de NiFi. De esta forma, se redistribuye la carga mejorando así el rendimiento y consiguiendo mayor escalabilidad.
- Configurar rutas de error en los procesadores: los empleamos para evitar bucles, detenciones del flujo o pérdidas de datos en caso de problemas de conexión o con los propios datos. Así se garantiza que el flujo no se detenga y los datos no se pierdan.
- Usar penalización y espera progresiva en caso de error: en caso de error, sirven para que el sistema espere a que los servicios tengan tiempo de recuperarse. De esta forma, se evita una saturación del sistema.
- Usar repositorios de contenido y flujo en discos diferentes: una opción avanzada que puede ser interesante es emplear la SSD del equipo para los repositorios de FlowFiles y Provenance (metadatos e historial de los FlowFiles que requieren acceso frecuente a disco). Y, por otra parte, usar la HDD para el repositorio de Contenido (FlowFiles donde se almacenan los datos pesados).
- Hacer limpieza regularmente de los repositorios: se debe revisar periódicamente el contenido de los repositorios de FlowFile, Contenido y Provenance. Así, se podrán evitar problemas de almacenamiento y rendimiento.
En caso de que se trabaje con sistemas en producción con datos sensibles, es importante tener en cuenta varios aspectos. Por ejemplo, a la hora de mantener la seguridad y la integridad de los datos y controlar quién tiene acceso:
- Habilitar la autenticación y el control de acceso: para asegurarnos de que únicamente usuarios y servicios autorizados puedan entrar.
- Configurar SSL/TLS: podemos implementar algunos protocolos de seguridad para cifrar las comunicaciones entre el navegador y el servidor de NiFi. Además, es posible configurar la autenticación basada en certificados entre componentes.
- Habilitar el registro de eventos: NiFi posee archivos .log para supervisar tanto el acceso a la interfaz como a la actividad de los flujos de datos.
- Usar Nifi Registry: se trata de una herramienta externa que permite gestionar el versionado de los flujos de datos. Es útil para mantener un historial de las configuraciones de los flujos y hacer seguimiento de los cambios en el tiempo.
Instalación y configuración de Apache NiFi en Linux
Tras conocer los conceptos básicos de la herramienta, procedemos a descargarla e instalarla en nuestro entorno. Este ejemplo se realiza en Linux, por lo que el manual de instalación que abordaremos estará enfocado en este SO. No obstante, puedes consultar otras alternativas en la documentación oficial primeros pasos de Apache NiFi.
Requisitos:
- Java 21: aunque podría ejecutarse en alguna versión previa de Java, para la versión más reciente de esta herramienta (NiFi 2.2.0) es recomendable usar Java 21. En muchos espacios de internet puedes encontrar que tiene compatibilidad con Java 8, 11 y 17. Aunque, personalmente, las dos primeras versiones las he probado y no han podido levantar el servicio, generando el error que se muestra a continuación. Recuerda exportar JAVA_HOME con esta versión y actualizar la versión con update-alternatives (para usuarios de Linux).
LinkageError occurred while loading main class org.apache.nifi.bootstrap.BootstrapProcess java.lang.UnsupportedClassVersionError: org/apache/nifi/bootstrap/BootstrapProcess has been compiled by a more recent version of the Java Runtime (class file version 65.0), this version of the Java Runtime only recognizes class file versions up to 55.0.
Comandos de interés
- Con
bin/nifi.sh runse ejecuta NiFi en primer plano. bin/nifi.sh statusproporciona información sobre el estado actual.

- Ejecuta
bin/nifi.sh startpara lanzar NiFi en segundo plano. bin/nifi.sh stopfinaliza la ejecución.

Instalación y configuración paso a paso
En primer lugar, nos dirigimos a la web oficial de Apache Nifi para la descarga del binario Standard 2.2.0.

Descomprimimos el fichero y ejecutamos lo siguiente por consola dentro de la carpeta:

Este comando inicia Apache NiFi en segundo plano y la primera vez que se ejecuta. Vemos que se crean una serie de directorios nuevos.
A continuación, ejecutamos el siguiente comando para establecer unas credenciales de usuario y contraseña para iniciar sesión en NiFi:


Accedemos a https://localhost:8443/nifi/, iniciamos sesión y obtendremos el siguiente canvas:
En este punto, ya tenemos la herramienta puesta en funcionamiento. En los siguientes apartados comenzaremos a darle uso con algunos ejemplos sencillos para iniciarnos con ella.
Primeros pasos con NiFi
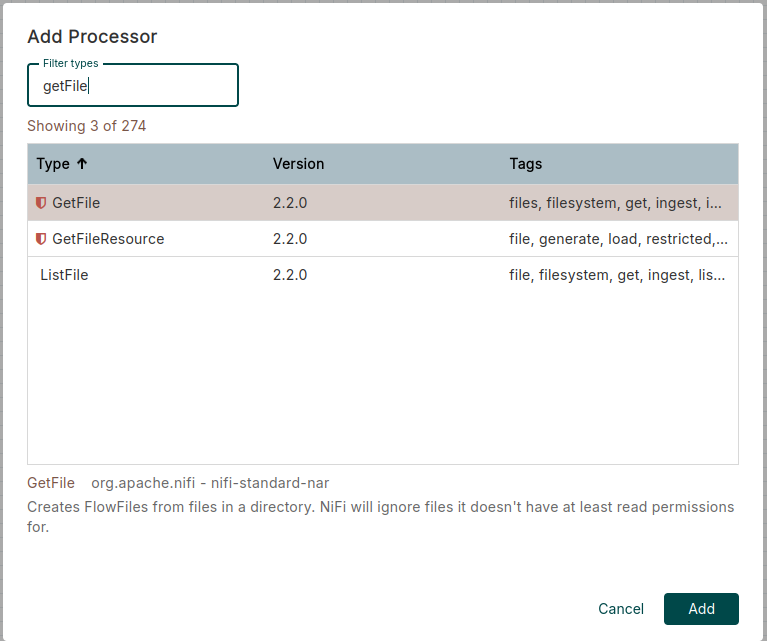
Ahora que tenemos la herramienta a punto, vamos a crear un flujo de datos sencillo. Primero, arrastramos un procesador hasta el canvas (clic en el primer objeto de la barra superior de tareas) y buscamos un GetFile. Luego, hacemos el mismo proceso para crear un PutFile.
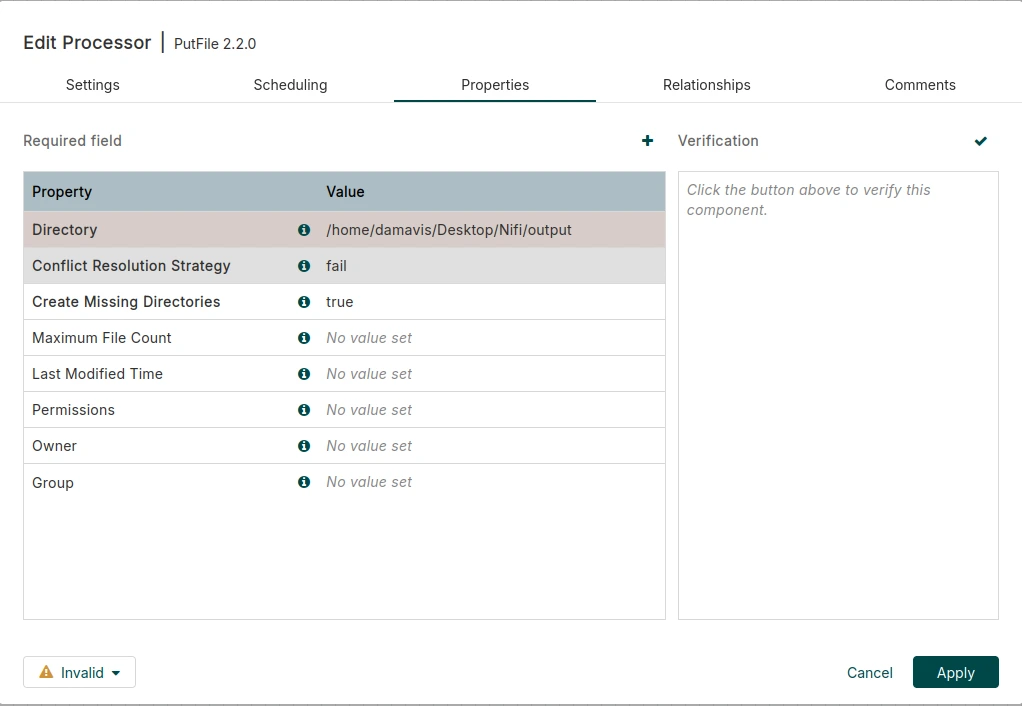
Cuando ya tengamos los dos procesadores, procedemos a crear dos archivos en nuestro equipo. Para ello, copiaremos su ruta (puedes utilizar input y output como nombres para que te sea más intuitivo). Establece la ruta de la carpeta de origen (input) al procesador GetFile y la de destino (output) al PutFile.
Una vez que tengamos definidos los procesadores con sus respectivas rutas, pasamos el ratón por encima del procesador GetFile, hacemos click y arrastramos la fecha hasta el procesador PutFile. Con esta acción se crea una conexión entre los dos procesadores, donde hacemos click en el checkbox para establecer la relación success y después pulsamos Add.
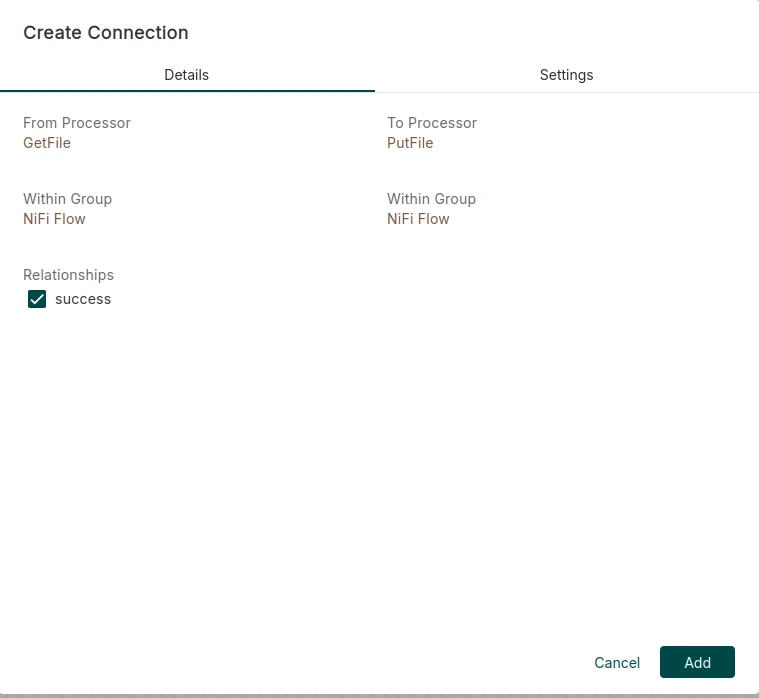
En este punto, deberíamos tener en nuestro canvas los dos procesadores creados previamente unidos por una conexión, que posee una cola como vemos en la siguiente imagen:
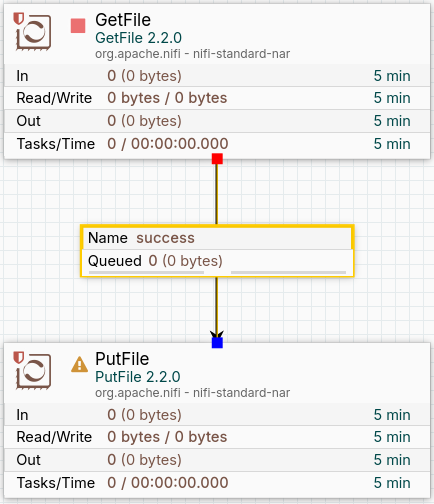
Si nos fijamos bien, a la izquierda del procesador de PutFile existe un símbolo de advertencia. Esto indica que aún no hemos configurado cómo debe responder el procesador en caso de que se realice o no la acción de forma exitosa. Es decir, que se envíe el archivo desde la carpeta de origen hasta la de destino, o que no lo consiga. Para ello, hacemos clic derecho en el procesador y establecemos que se termine la tarea en caso de éxito y también de error. Además, pinchamos en Apply.
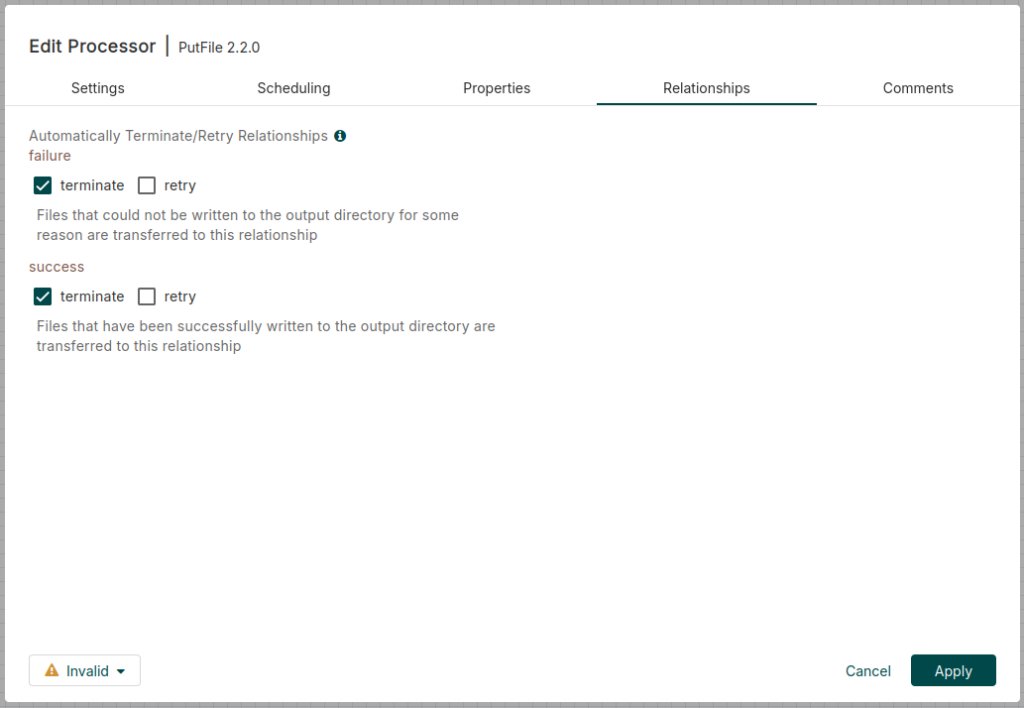
Ahora podemos observar que el símbolo anterior ha desaparecido.
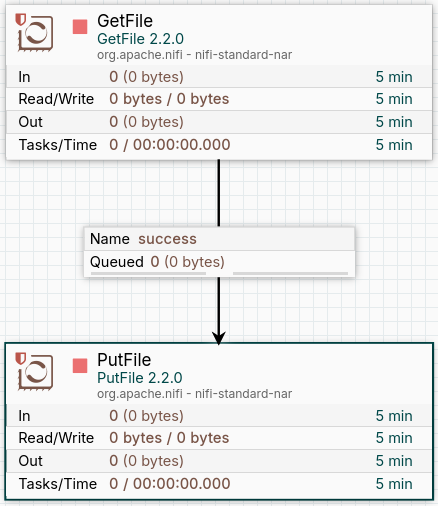
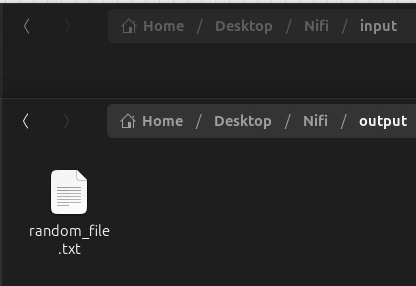
Finalmente, introducimos un archivo cualquiera dentro de la carpeta de input y activamos ambos procesadores con clic derecho y Start. Podemos ver cómo el archivo ha sido enviado desde la carpeta input hasta la de output.
Conclusión
A lo largo de este artículo, hemos ido profundizando en los conceptos clave de Apache NiFi y conocido las mejores prácticas para poner en marcha nuestros flujos de datos con eficiencia y seguridad. Además, hemos sido capaces de instalarlo en nuestro entorno de trabajo y desarrollado un pequeño caso de uso. Ahora, llega tu turno para poner en práctica tus nuevos conocimientos y jugar un poco con ella.
Hasta aquí nuestro post de hoy. Si te ha parecido interesante, te animamos a visitar la categoría Software para ver artículos similares y a compartirlo en redes con tus contactos. ¡Hasta pronto!
