
Kafka es una de las tecnologías más populares del stack de Apache que ya hemos explorado en nuestro blog. Si aún no estás del todo familiarizado con ella, te recomendamos leer la Introducción a Apache Kafka para conocer sus componentes principales.
Arquitectura de Kafka: De Zookeeper a KRaft
En primer lugar, analizaremos cómo se ha ido desarrollando esta tecnología en el tiempo respecto a lo que hemos abordado anteriormente.
La arquitectura de Kafka ha evolucionado y ya no depende de Zookeeper. Desde la versión 3.3, se introdujo un nuevo sistema de consenso llamado KRaft (Apache Kafka on Raft). Por el momento, todavía se puede usar Zookeeper como organismo de consenso. Sin embargo, se planea eliminar esta dependencia en el futuro.
Recordemos que Zookeeper se conectaba con los brokers. Además, ha sido un componente esencial en Kafka para coordinar la configuración, la información de los brokers y el estado del clúster.
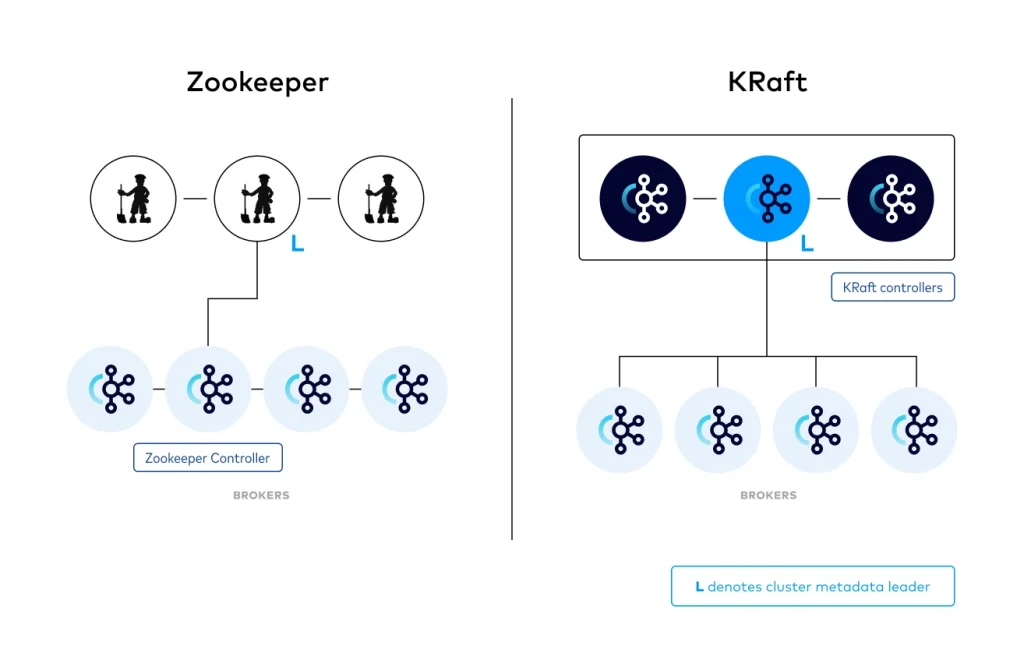
Cómo funciona KRaft en Kafka
Con KRaft, Kafka utiliza su propio protocolo de consenso (basado en Raft) para gestionar el estado de los brokers y particiones de manera interna. Un conjunto de brokers (Controladores o Controllers), almacenan y replican esta información, manteniéndola consistente sin necesidad de un sistema externo. Cuando hablamos de un sistema externo, nos referimos a que Zookeeper tiene su propia identidad. Además, se utiliza en muchos otros proyectos como backend de apoyo para sistemas distribuidos.
KRaft maneja todo de forma interna con uno o varios Controladores. Estos Controllers son brokers especiales que usan el protocolo Raft para replicar el estado y mantener el consenso en el clúster. Esto unifica Kafka en un solo sistema y facilita la gestión.
KRaft coordina la asignación y el estado de las particiones dentro del clúster, así como la elección del líder para cada partición. Este proceso de selección de líderes es crucial. El broker líder de cada partición es el que maneja las operaciones de lectura y escritura. Por su parte, KRaft verifica que haya un líder asignado de manera eficiente y fiable.
KRaft asegura que las réplicas de cada partición estén sincronizadas con el líder. La replicación de datos entre brokers se gestiona para garantizar la durabilidad y consistencia de la información. Esto permite que los datos permanezcan disponibles incluso en caso de fallo de uno o más brokers.
Por último, mantiene y coordina los estados de los consumer groups, incluyendo el seguimiento de los offsets que cada consumidor ha procesado. Esto garantiza que los consumidores puedan continuar desde el último punto leído en caso de una desconexión o fallo, sin necesidad de coordinación adicional con Zookeeper.
Particiones en Apache Kafka
Uno de los principales conceptos que debemos entender es cómo funciona el sistema de particiones dentro de Kafka.
Cada topic de Kafka se divide en múltiples particiones, lo que permite distribuir los mensajes entre varios brokers. Esto facilita la escalabilidad y el procesamiento paralelo. Dentro de una partición, Kafka garantiza el orden de los mensajes. Es decir, los eventos se mantienen en el mismo orden en que fueron enviados y leídos. Sin embargo, a nivel de topic, como cada partición es independiente, no se asegura este mismo orden.
Réplicas, líderes y seguidoras
Cada partición tiene réplicas para proteger la durabilidad y disponibilidad de los datos. Solo una de estas réplicas actúa como «líder», encargada de gestionar todas las operaciones de lectura y escritura del topic. El resto de las réplicas funcionan como «seguidoras» sincronizándose continuamente con el líder para poder asumir su rol en caso de fallo.
Kafka mantiene una lista de réplicas sincronizadas o ISR (In-Sync Replicas), que están al día con el líder. De este modo, si el broker que aloja el líder de una partición falla, Kafka automáticamente elige una nueva réplica líder de la lista de ISR. De esta forma, evita la interrupción del servicio.
En ocasiones, puede ser interesante asignar mensajes a las particiones. Es decir, que ciertos mensajes caigan siempre en la misma partición. Si un mensaje tiene una clave, el particionador calcula un hash de esa clave, lo que permite dirigir el mensaje a una partición específica. De esta forma, todos los mensajes con la misma clave irán a la misma partición, respetando el orden relativo de los mensajes de ese tipo.
Para que se entienda mejor, vamos a explicarlo con un ejemplo. Imaginemos que debemos asegurar el orden de operaciones entre cuentas de una entidad bancaria. Sabemos que Kafka nos asegura el orden de los mensajes dentro de la misma partición. Pero, si los mensajes fueran operaciones y se les asignase una partición de manera aleatoria, podría incurrir en algún tipo de condición de carrera. Si hacemos que la key (que decide dónde debe caer un mensaje) sea el número de cuenta, nos aseguramos que siempre leeremos en orden todas las operaciones que tengan que ver con una misma cuenta.
Casos prácticos de Apache Kafka
Pasemos a la práctica. A continuación, veremos los diferentes casos que hemos expuesto y analizaremos cómo se comportaría Kafka. Para ello, nos apoyaremos en esta herramienta de Visualización de Kafka que nos permitirá observar el comportamiento de los mensajes en las diferentes particiones.
Ejemplo 1: Productores y consumidores en un topic con dos particiones
Empecemos con el comportamiento del ejemplo más simple. En este caso, tenemos un producer que envía mensajes a dos brokers (los que aparecen con el botón de apagado). El topic tiene dos particiones, por tanto, cada broker muestra esas dos líneas donde se van insertando los mensajes.
En un sistema de asignación de partición aleatoria, los mensajes pueden caer tanto en la partición 1 como en la 2, pero siempre se respeta el orden dentro de la partición. Es decir, los últimos mensajes siempre serán más nuevos que los anteriores.
En la parte de abajo, hay un consumer group llamado A. Este consumer group solamente tiene un consumidor, por lo que se encarga de leer las dos particiones para ir obteniendo todos los mensajes.
*Nota: En la imagen, se puede ver claramente cómo las particiones de color oscuro son las particiones líderes. También se puede observar cómo el productor envía datos solamente a las particiones líderes. Tal y como hemos comentado anteriormente, el resto de particiones se encargarán de sincronizarse con la líder.
Caso 2: Distribución de consumidores en un consumer group
En este caso, hemos añadido un consumidor más al consumer group A. Podemos ver cómo cada consumidor reparte los mensajes del topic y se disponen a leer cada uno de una partición distinta.
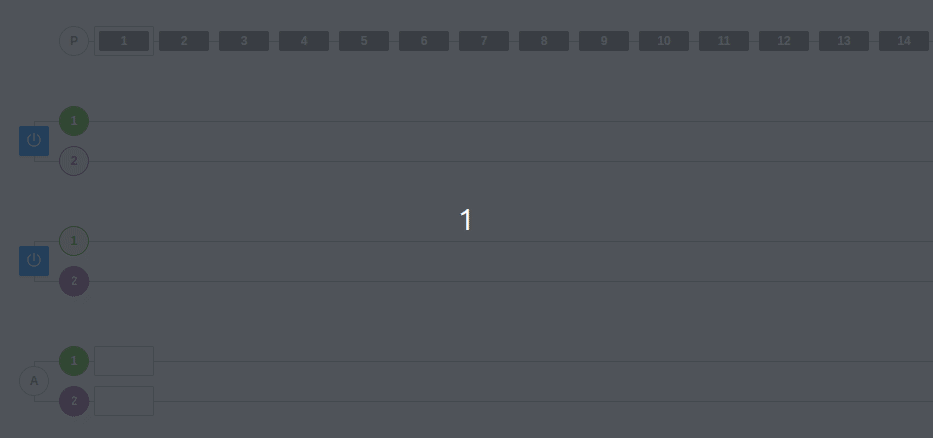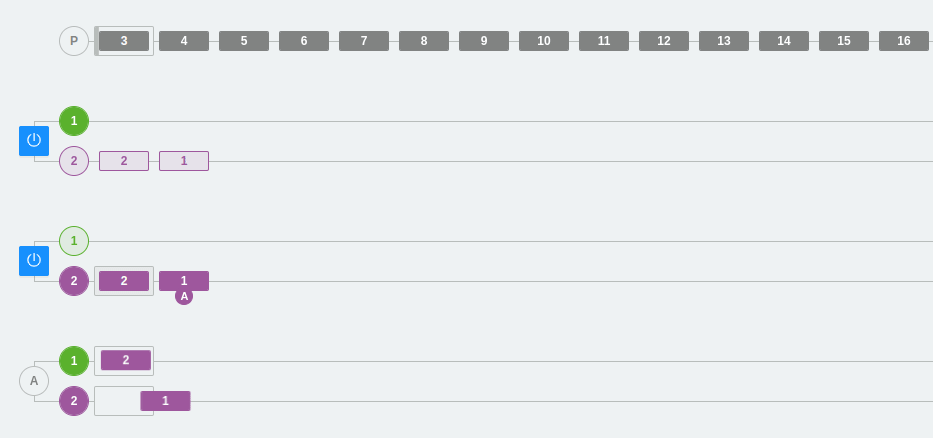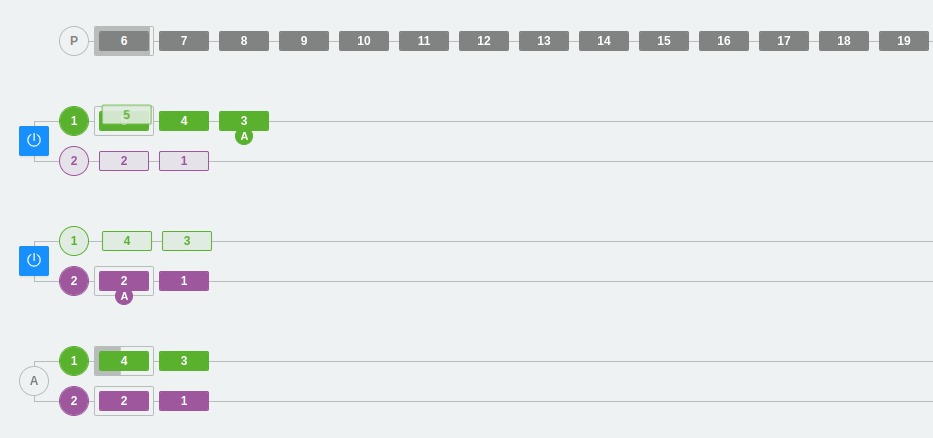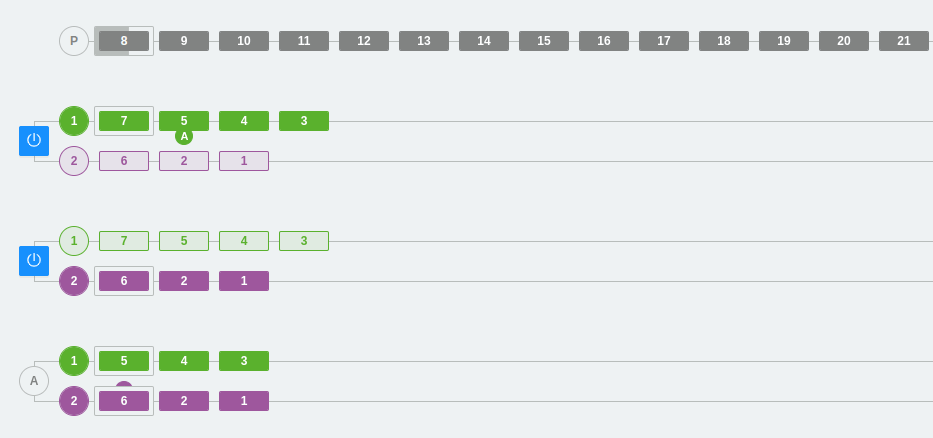
Este ejemplo marca un límite que hemos comentado anteriormente, pero seguramente ahora se ve mucho más claro. No podemos tener más consumidores en un consumer group de la cantidad de particiones que tiene dicho topic.
¿Qué ocurre si en este mismo ejemplo añadimos una nueva partición?
Lo que sucede es que uno de los consumidores recogerá los mensajes de dos particiones y el otro consumidor, solamente de una.
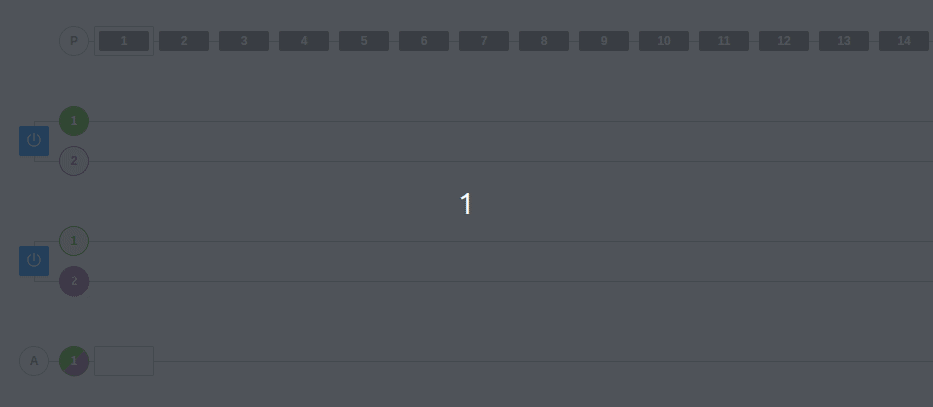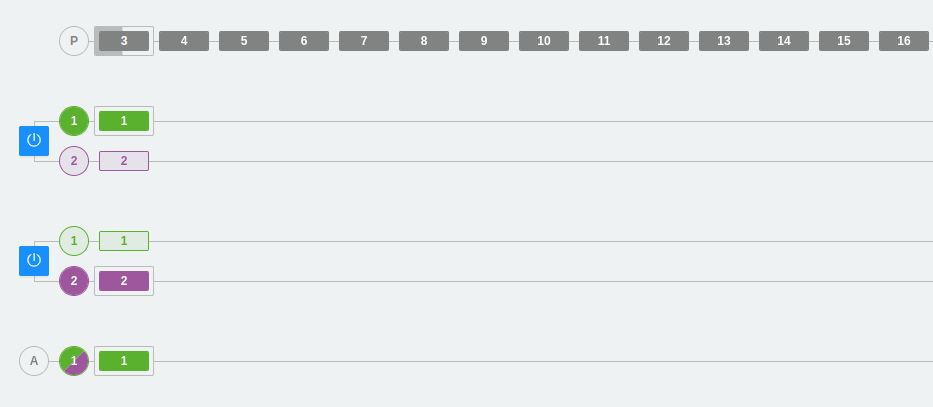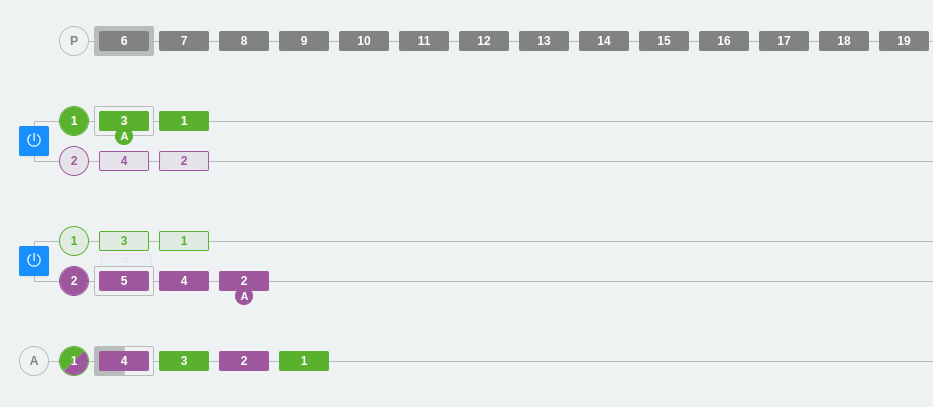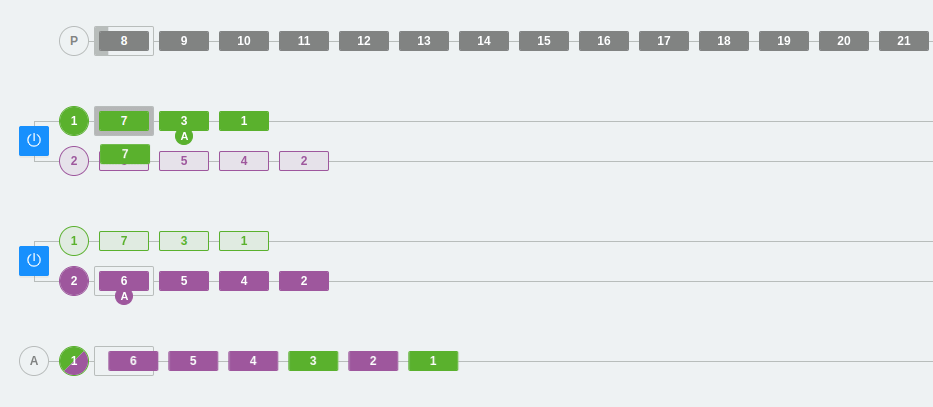
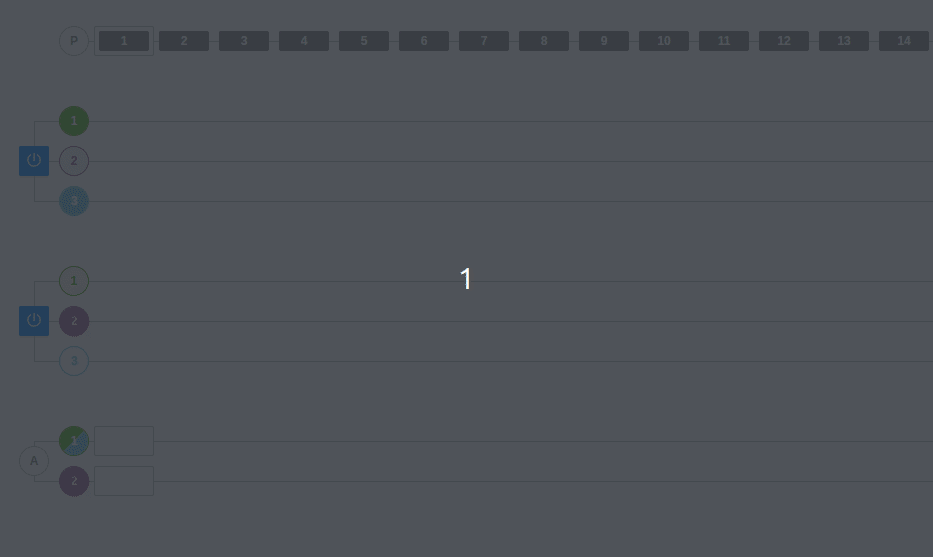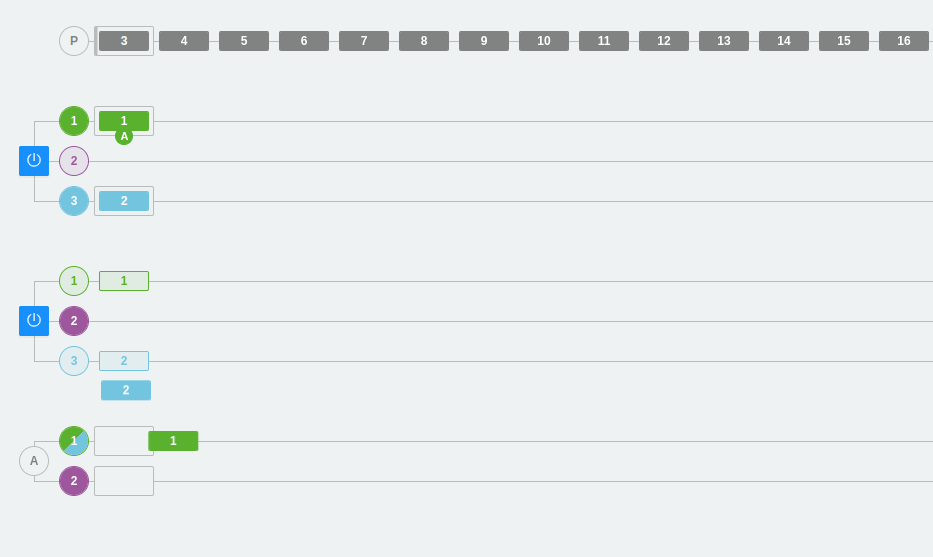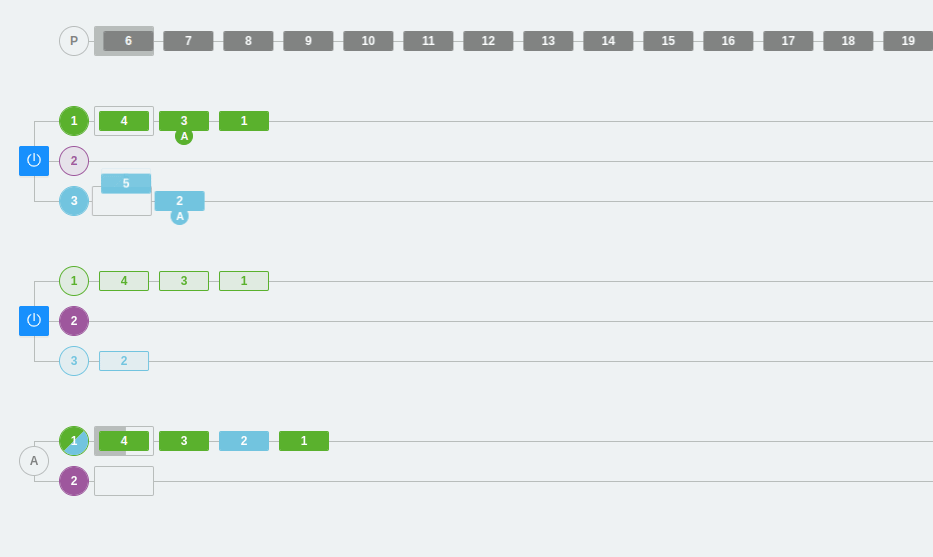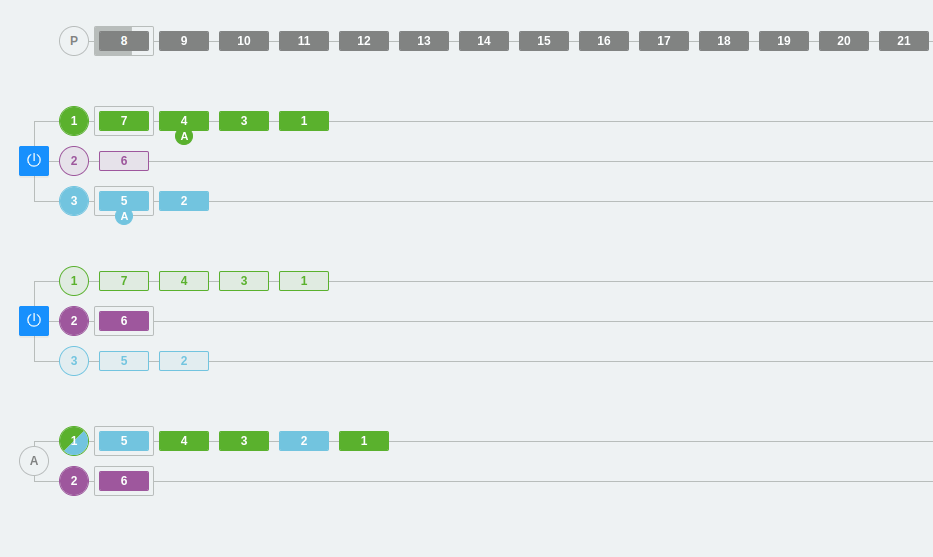
Ejemplo 3: Escalado de particiones y consumidores en Kafka
En el siguiente ejemplo, tenemos tres particiones en los dos brokers y tres consumidores dentro del mismo consumer group A.
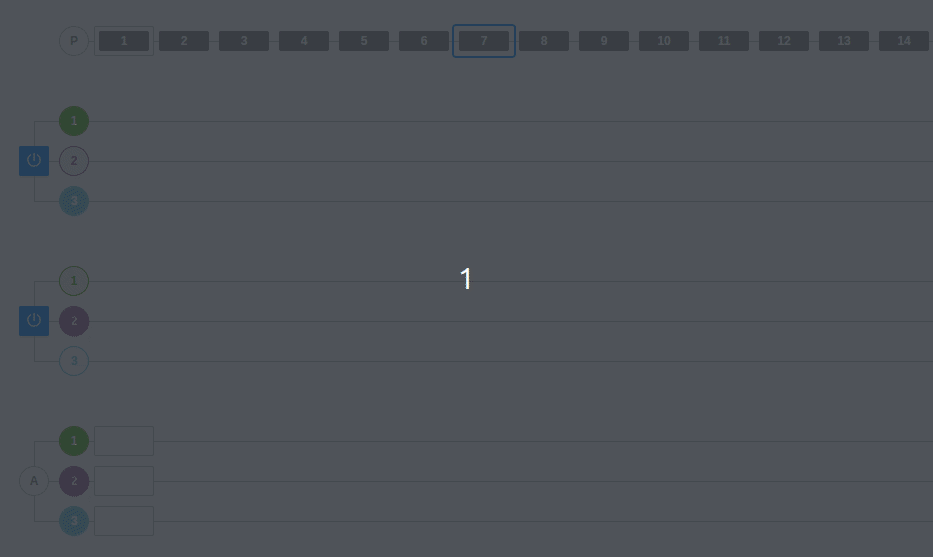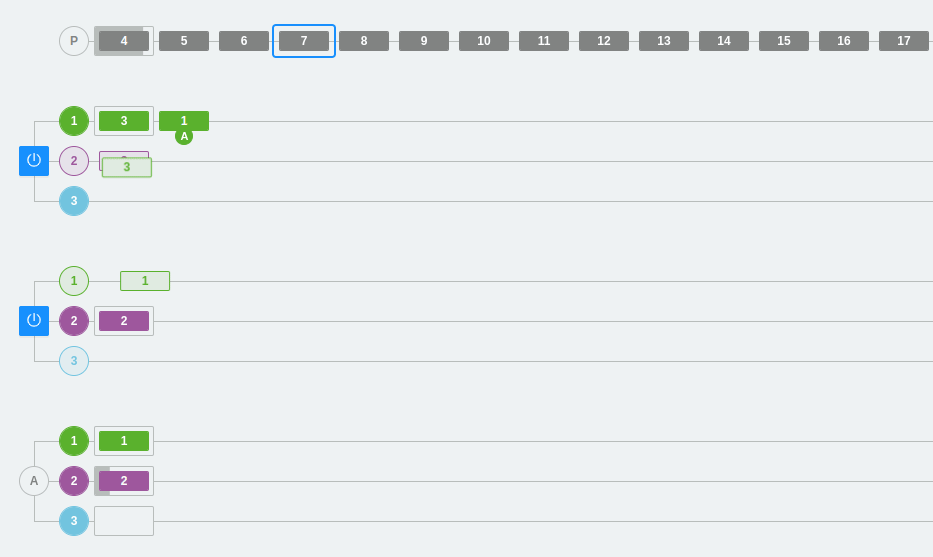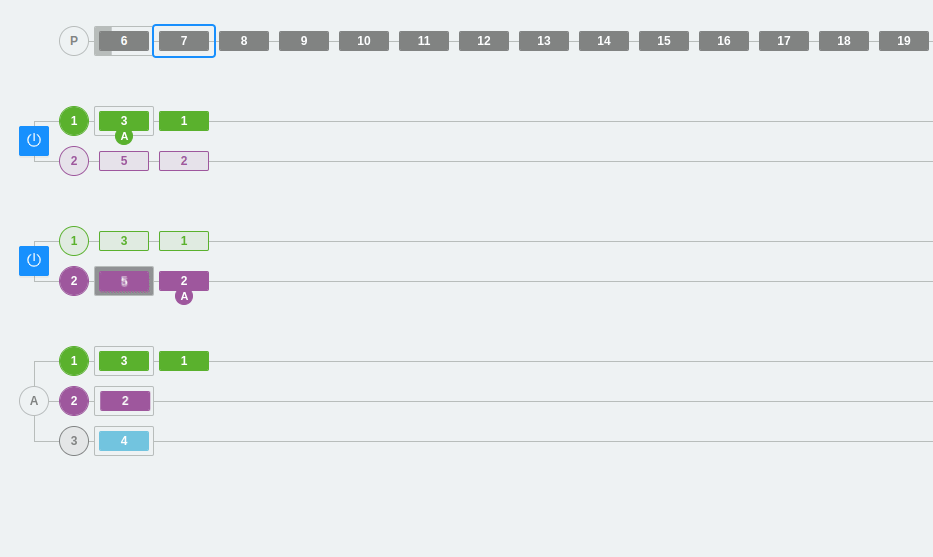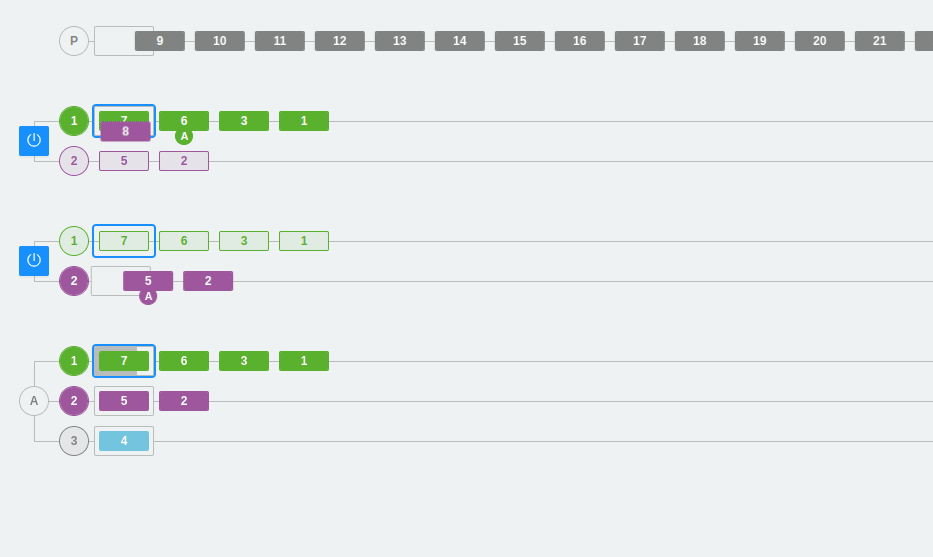
Como ya hemos visto, a cada partición se conectará un consumidor del grupo. Cada partición tiene un número y un color que lo identifica para que visualmente sea más sencillo seguir el flujo.
Por otra parte, se observa que los colores son verde, morado y azul intenso. Llegado un momento, se cambian las particiones, se quita una y la tercera partición desaparece. El resto de mensajes se irán colocando en las otras particiones y el consumidor 3 se desactiva (ya que no podrá escuchar directamente sobre ninguna partición). Recordemos que, en este caso, los consumidores que no puedan asignarse a una partición se quedarán inactivos. Esto no significa que no sirvan para nada, ya que aseguran la alta disponibilidad desde el punto de vista del consumo de los datos.
Caso 4: Fallo de un broker y recuperación del clúster
En este ejemplo, veremos qué ocurre cuando eliminamos un broker que queda inactivo por cualquier circunstancia.

Tal y como se puede observar, disponemos de dos brokers con dos particiones cada uno. En un momento dado, se interrumpe el segundo broker. El único broker disponible pasa a asumir toda la carga de trabajo, donde la partición secundaria pasa a ser la primaria. Posteriormente, el broker inactivo se vuelve a activar. Inmediatamente, el cluster tiende a sincronizar los mensajes moviendo al segundo broker todos aquellos mensajes que se inyectaron durante el tiempo de inactividad. Así, podemos fijarnos en que ahora el segundo broker no ha recuperado la partición primaria de color morado, ya que se ha mantenido en el primer broker hasta que el estado no cambie.
Conclusión
En este post, hemos visto cómo ha evolucionado la arquitectura de Apache Kafka con la introducción de KRaft. Este sistema ha llegado con el objetivo de reemplazar a Zookeeper en la gestión interna del clúster. Ahora, Kafka es capaz de manejar de forma autónoma el consenso y la replicación, simplificando su arquitectura y mejorando la eficiencia.
Hasta aquí nuestro post de hoy. Si te ha parecido interesante, te animamos a visitar la categoría Software para ver artículos similares y a compartirlo en redes con tus contactos. ¡Hasta pronto!
