
De todas las herramientas a las que podemos acceder en Google Cloud, una de las más potentes y utilizadas es, sin duda, BigQuery. Su versatilidad como data warehouse lo ha situado como una de las principales soluciones cloud para analítica de datos. A la hora de implementar sistemas de almacenamiento de datos a los que pueden acceder multitud de usuarios o departamentos de la organización, uno de los problemas que se presenta es “quién ve qué” e incluso “cómo lo ve”.
Esta gestión de la privacidad se puede enfocar de diferentes maneras. En función de nuestras necesidades, se pueden tomar distintas decisiones. En ocasiones, una simple vista autorizada será suficiente, o limitar los permisos a determinados datasets o tablas para un conjunto de personas que necesitan de dichos datos. Otras veces, y desde el punto de vista del gobierno de datos, esto puede acabar incrementando el tamaño hasta el punto de que acabe siendo sumamente complejo y difícil de gestionar, mantener y escalar.
Dentro de los servicios asociados a la API data catalog de GCP, tenemos una opción cómoda, rápida y fácilmente escalable para el control de los datos: el control de acceso a nivel de columnas. Este mecanismo basado en etiquetas nos permitirá controlar fácilmente a distintos niveles de granularidad quién puede ver qué columnas o incluso cómo verlas (enmascaramiento de datos). Esto, además, nos permite añadir una capa extra de información y metadatos a nuestras tablas. En este post, veremos cómo llevar a cabo dicho proceso así como un caso de uso práctico.
Protección de datos sensibles
En primer lugar, será necesario que nuestro proyecto tenga las APIs requeridas para dicha tarea. En este caso, hay que emplear Google Cloud Data Catalog API y BigQuery Data Policy API. También se requiere que el usuario encargado de realizar las tareas que se presentan a continuación, tenga ciertos roles. Estos roles son Policy Tag Admin role, BigQuery Admin role or the BigQuery Data Owner role y Organization Viewer role. Es posible que se necesiten otros roles adicionales que serán asignados durante el propio proceso.
Una vez tenemos nuestro entorno de trabajo con todo lo necesario, comienza el proceso de etiquetado y gestión de permisos.
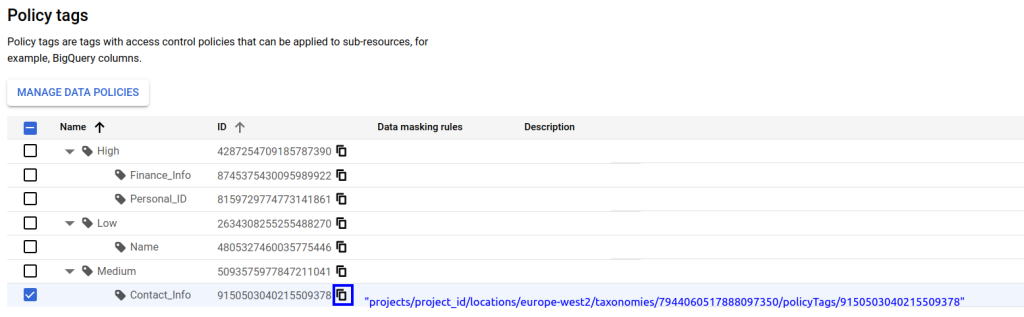
Lo primero es analizar nuestro caso de uso y generar una taxonomía adecuada que se ajuste a nuestros requisitos. Para ello, nos dirigiremos al apartado de Policy Tags en BigQuery y ahí crearemos nuestra Taxonomía.
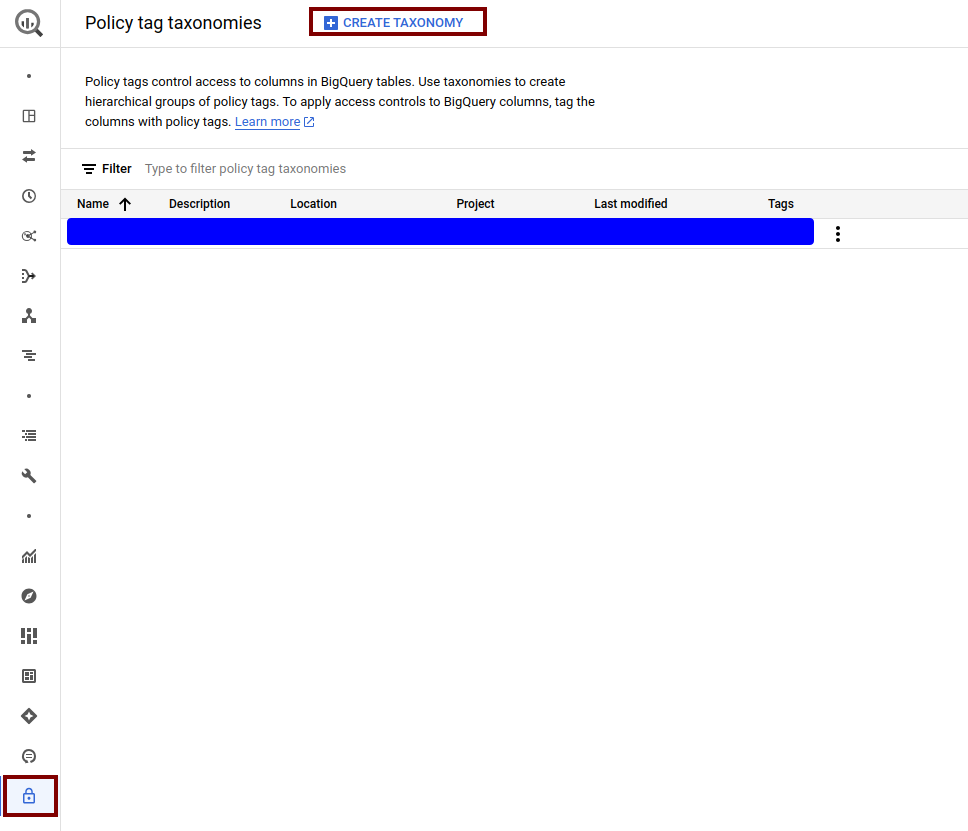
Una buena práctica a seguir será aglutinar las distintas etiquetas que requieran de una política de acceso similar bajo una de mayor nivel. En este caso, podemos ver a modo de ejemplo cómo hemos creado una taxonomía donde dividimos toda la información en 3 niveles de “privacidad”: datos altamente sensibles, nivel medio o nivel bajo. En función de la granularidad deseada y la información que queramos añadir en nuestras columnas, podremos optar por más o menos niveles de complejidad. Estas políticas pueden ser actualizadas de una forma simple. Si en un futuro requerimos de nuevos niveles o nuevas subtags, podremos añadirlas sin problemas.
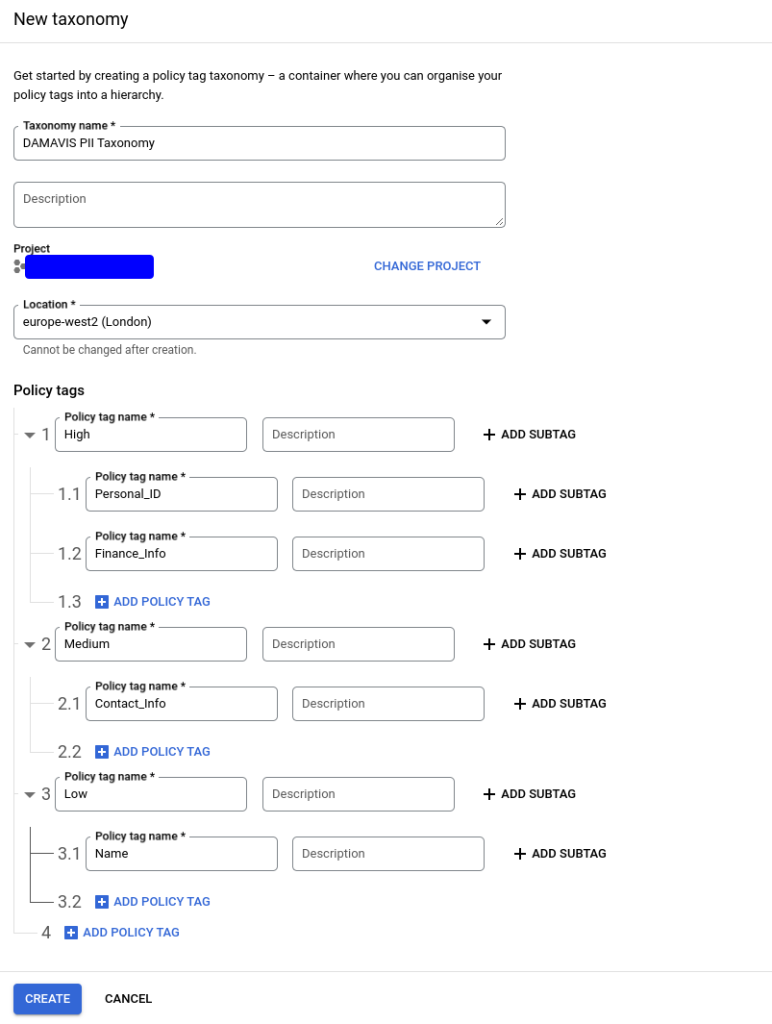
Tras crear la taxonomía, tendremos acceso al panel que nos permitirá asignar las políticas concretas que se aplicarán. En dicho panel cabe destacar la existencia de varios apartados:
- Activación de control de acceso. Este botón interactivo será el que permita, una vez configuradas las políticas, que sólo los usuarios asignados para ver los datos etiquetados puedan acceder a ellos. Esto implica que surtan efecto las políticas creadas.
- Árbol de etiquetas. Tendremos la representación de las etiquetas creadas, permitiéndonos seleccionar cada una de ellas para añadir roles que tendrán visibilidad sobre los datos etiquetados.
- Panel de información. Sobre las etiquetas seleccionadas, podremos observar tantos los roles heredados como incluir los nuevos que apliquen para dichas etiquetas.
- Botón de gestión de políticas de datos. Podremos acceder a un menú, de nuevo sobre las etiquetas seleccionadas, donde aplicar una política de enmascaramiento sobre los datos.
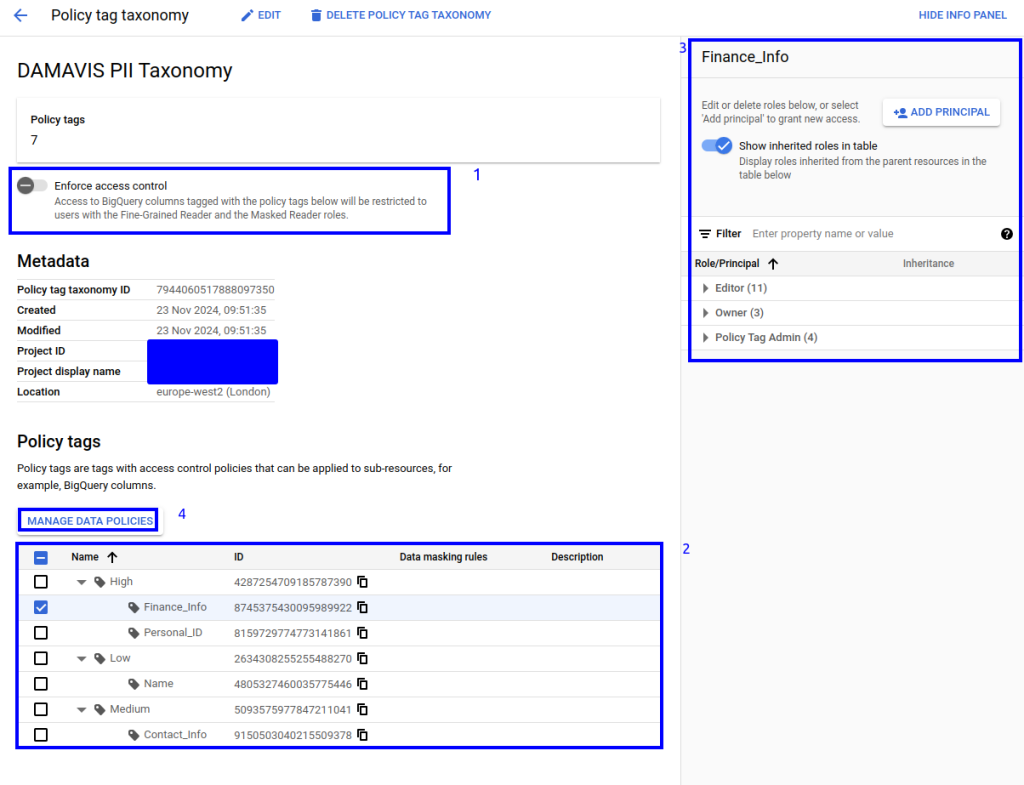
A continuación, usando la UI, procederemos a asignar cada uno de estos recursos a los grupos, usuarios o cuentas de servicio que queramos. En este caso, aplicaremos lo siguiente:
- Vamos a dar permisos a nuestro usuario con el rol fine grained reader para ciertas columnas, todo lo correspondiente al etiquetado de bajos privilegios y para una de las tags que contiene información altamente sensible. El resto de las columnas, si tienen alguna etiqueta asignada, no serán visibles para este usuario de pruebas. Como podemos ver, hemos elegido tanto una etiqueta concreta como una “rama” completa.
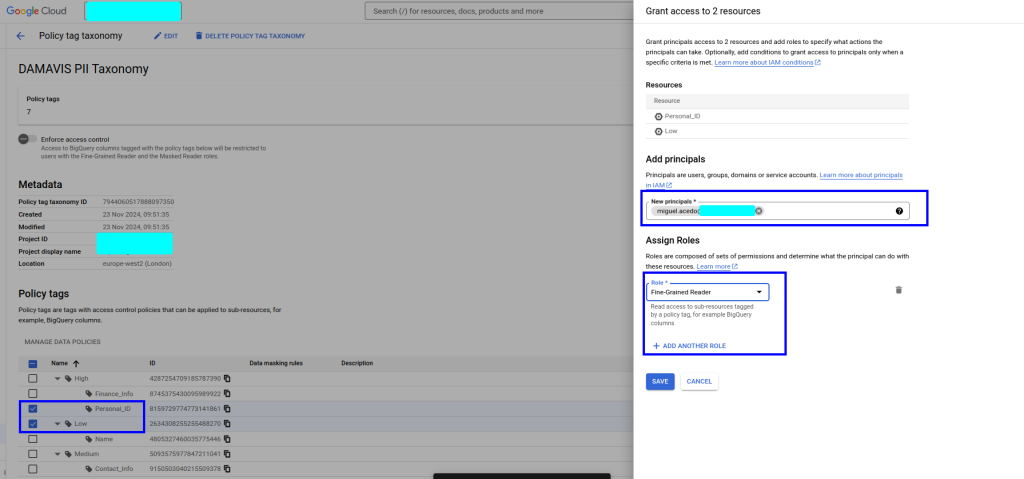
- En segundo lugar, para la etiqueta contact_info, que usaremos para etiquetar el email, aplicaremos un enmascarado especial. Dentro de la configuración de dicho filtro, debemos de nuevo indicar a qué usuario/rol se le asignará el permiso maskedReader y que, por tanto, podrá ver la columna pero con su información ofuscada.
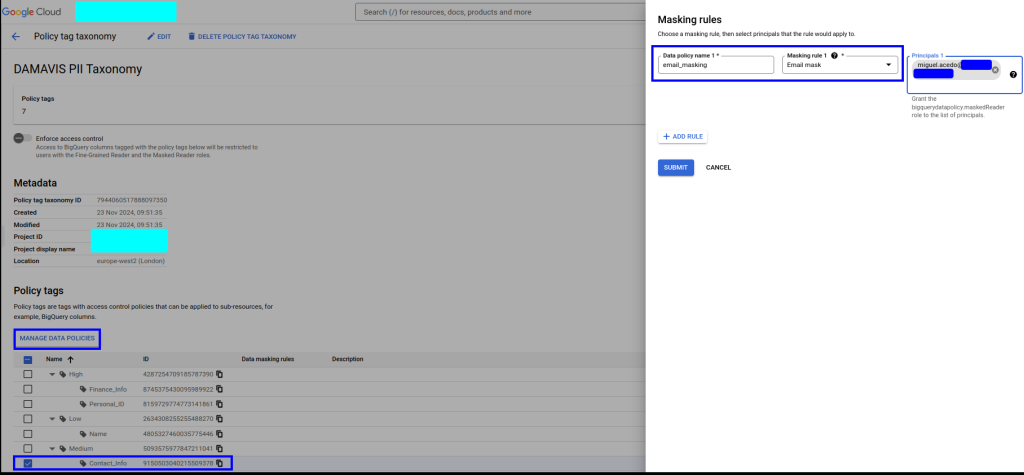
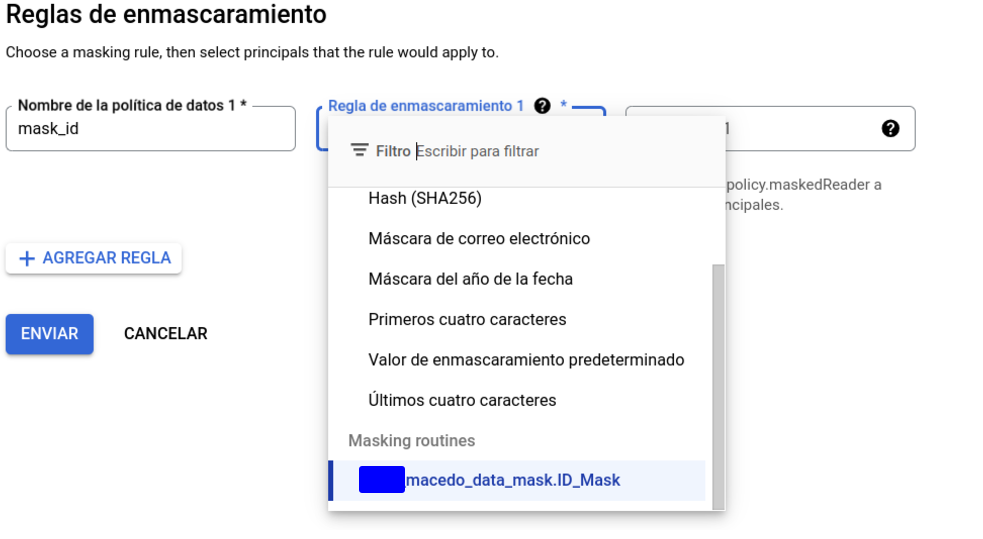
Dependiendo de nuestras necesidades y del tipo de dato, es posible fijar una regla u otra. Por ejemplo, podremos aplicar null al campo al completo, un valor por defecto, alguna regla particular como la que aquí aplicamos, un hashing o incluso una UDF sobre el campo.
En este último caso, las funciones se crearán como rutinas en BigQuery, teniendo como particularidad el flag data_governance_type = “DATA_MASKING”, que permitirá que dentro de la interfaz podamos seleccionar dicha rutina.

Es importante aclarar que, una vez activemos la política, todas las columnas que contengan alguna de las etiquetas presentes en la misma desaparecerán para aquellos roles a los que no se explicite que tienen acceso. Por lo tanto, de cara a evitar problemas en nuestros procesos, será muy importante asegurarnos de que estos datos no están actualmente siendo usados por otros roles o service accounts.
Ejemplo práctico
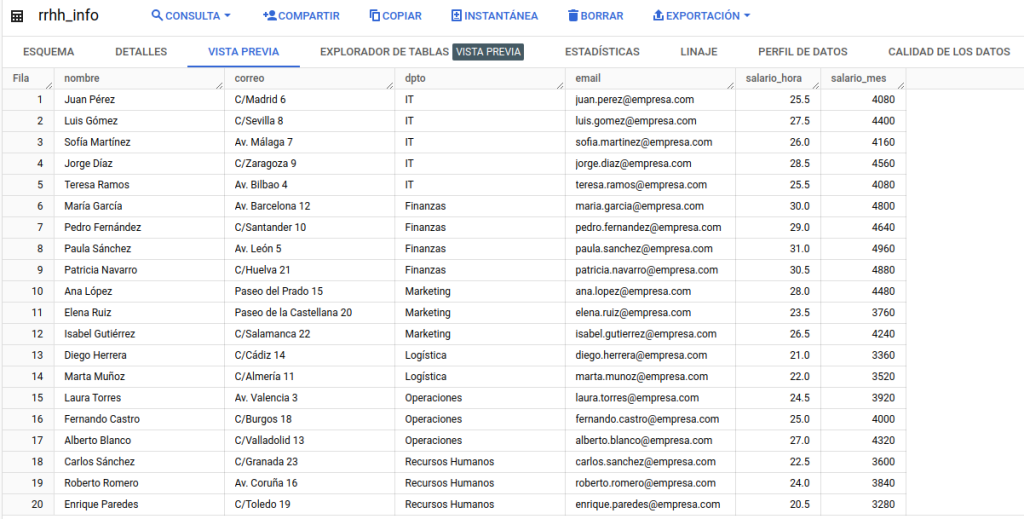
A modo de ejemplo, se ha creado una tabla con información referente a un posible caso de uso, en el que tenemos información de empleados a la que quizás queremos acceder de una forma controlada.
A continuación, aplicaremos el etiquetado sobre las columnas según corresponda mediante la edición del esquema.
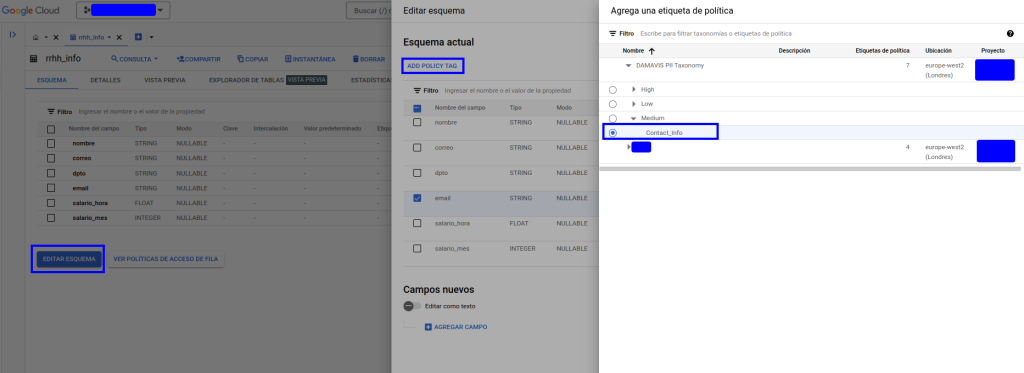
Una vez aplicado el etiquetado deseado, en el esquema podremos observar que se ha agregado la información en la columna correspondiente:
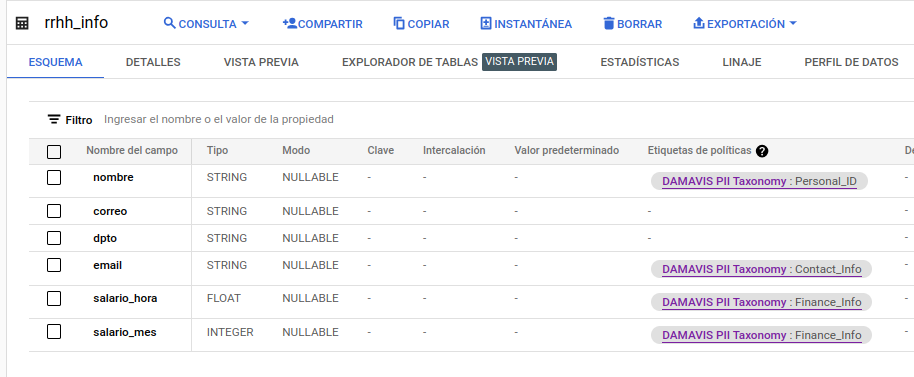
Esta asignación de una tag para cada columna se puede realizar de distintas formas. O bien desde la interfaz, como acabamos de observar, o como una opción extra en el esquema de la tabla. Este esquema puede incluirse en la creación, o bien mediante una actualización del mismo desde la api de bigQuery o desde el CLI. Donde no podremos incluirlo será mediante sentencias DDL en la interfaz de BQ. En el esquema, añadiremos la opción de policyTags y también el path a la policy:
[
...
{
"name": "email",
"type": "STRING",
"mode": "NULLABLE",
"policyTags": {
"names": ["projects/project_id/locations/europe-west2/taxonomies/7944060517888097350/policyTags/9150503040215509378"]
}
},
...
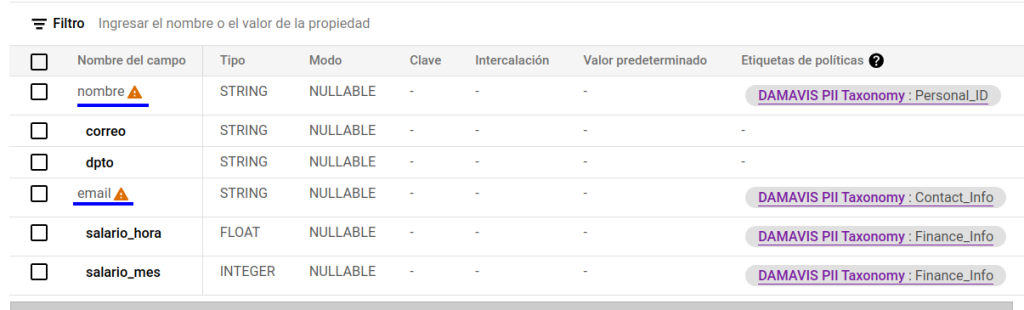
]Finalizado el proceso, podremos activar nuestra nueva política y ver cómo, en efecto, tenemos acceso a los datos tal y como lo hemos configurado. Nuestro usuario tendrá acceso a:
- Todas las columnas no etiquetadas y que, por tanto, se regirán por los permisos ya adquiridos sobre el proyecto.
- Visibilidad de la columna de email, pero de forma ofuscada.
- Dentro de las columnas con etiqueta correspondiente a los datos altamente sensibles, solo tendremos acceso a aquellas relacionadas con el salario, no pudiendo ver la vinculada a la política de Personal_ID.
En las siguientes imágenes podemos ver cómo estos cambios han surtido efecto:
Si tratamos de lanzar una query sobre la tabla:
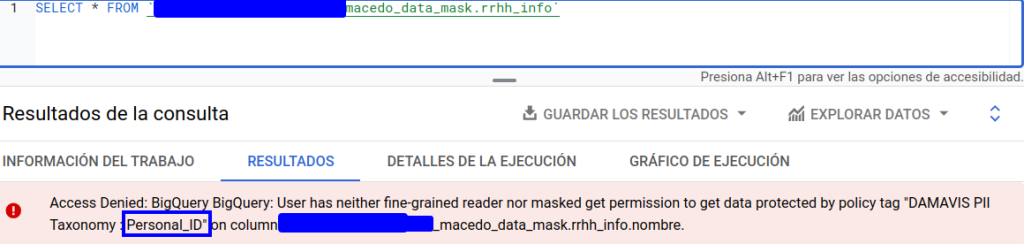
Deberemos excluir la columna en cuestión si queremos acceder a los datos. También hay que tener este factor en cuenta a la hora de analizar qué procesos hacen uso de sentencias de tipo SELECT * . De lo contrario, dichos procesos podrían fallar.
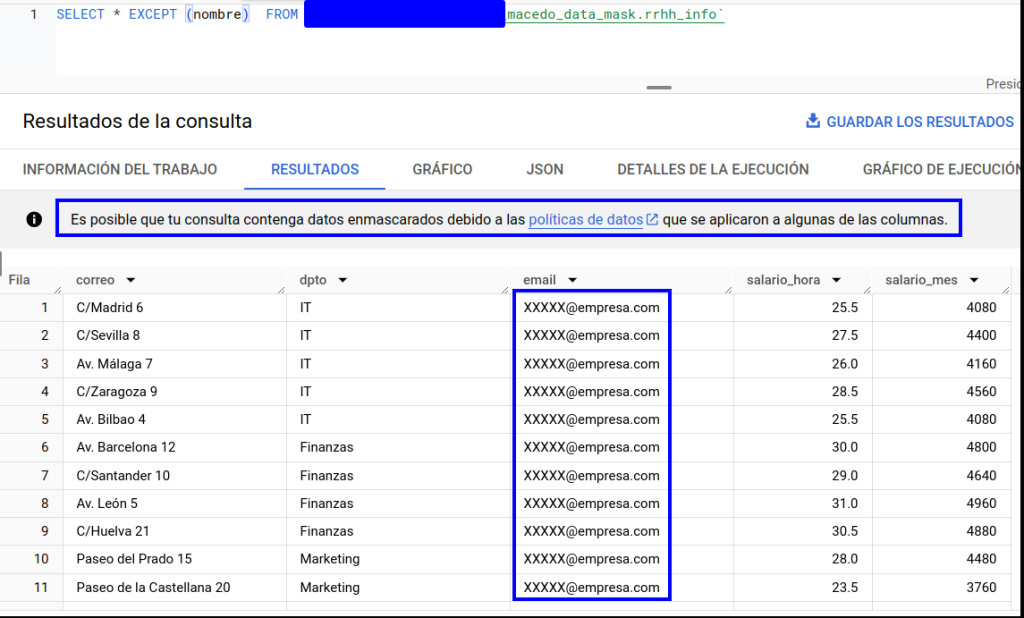
A modo de ejemplo, se ha pedido a otro miembro del equipo (que solo tiene los accesos propios del proyecto) que intente acceder al recurso:
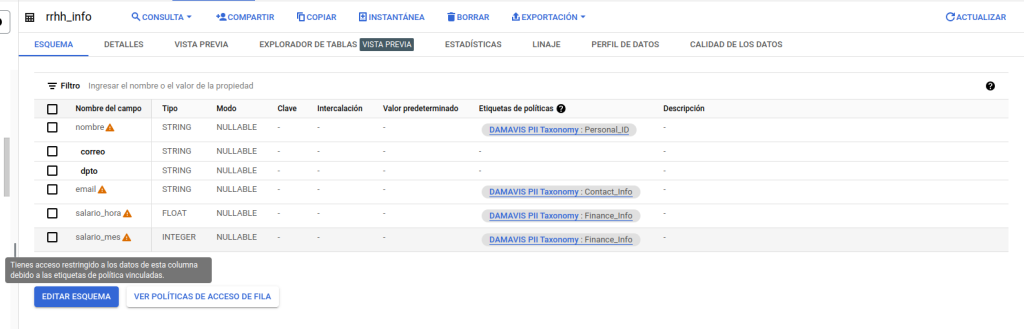
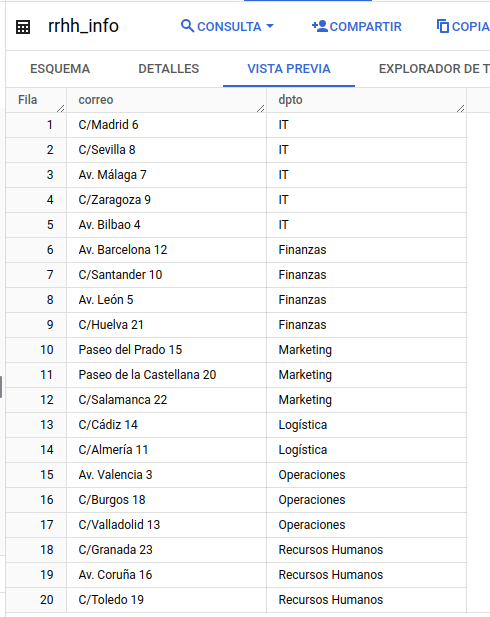
Podemos ver que, tanto en el esquema como en la vista previa, BigQuery indica y limita su nivel de acceso.
Conclusión
Como hemos visto en el post, la primera vez que generamos estas políticas puede ser un trabajo minucioso. Además, es algo que requiere de cierta intervención manual (especialmente, si esta metodología no ha sido implantada desde la generación del proyecto). Su escalabilidad y fácil mantenimiento son, sin duda, los puntos fuertes a tener en cuenta a la hora de buscar una solución que nos permita controlar el acceso a nuestros datos.
La aplicación de dichas etiquetas a todas las tablas que creemos, o la inclusión de nuevos usuarios/service accounts a grupos presentes en dichas políticas, nos permitirá un control granular sobre toda la información de nuestro proyecto sin tener que realizar cambios en vistas, datasets o tablas de forma manual. Separando, por tanto, el gobierno de datos de los procesos ETL o de la parte analítica de nuestra organización.
Si este artículo te ha parecido interesante, te animamos a visitar la categoría Data Engineering para ver otros posts similares a este y a compartirlo en redes. ¡Hasta pronto!
