
Airflow is an open source framework for developing, orchestrating and monitoring batch workflows. In case you are not familiar with it, and to better understand the content of this article, it is recommended to review the basics of Apache Airflow that we analysed some time ago in our blog.
As an orchestrator, the framework is provided with some tools that allow it to control the execution of tasks at different levels. Previously, we saw the use of Apache Airflow sensors in detail as well as the advanced handling of dependencies between different DAGs. The simplest concept related to handling dependencies between tasks in the same DAG is trigger rules. This post is intended to be an overview of the options and possibilities that Airflow offers in this regard.
What are trigger rules?
In Airflow, operators have an argument called trigger_rule that defines the requirements necessary for the task to proceed to execute in the workflow. On a practical level, this translates into defining the conditions that the previous task executions in the workflow (upstream) must have fulfilled, before giving the green light to execute the next task (on which the trigger rule is set).
The default value of this argument is all_success, so a task will never be executed unless all upstream tasks immediately preceding it have also been successfully executed. For example, in the following view, the last_task has been executed because all parallel_task_* tasks 1 to 5 have been executed successfully.
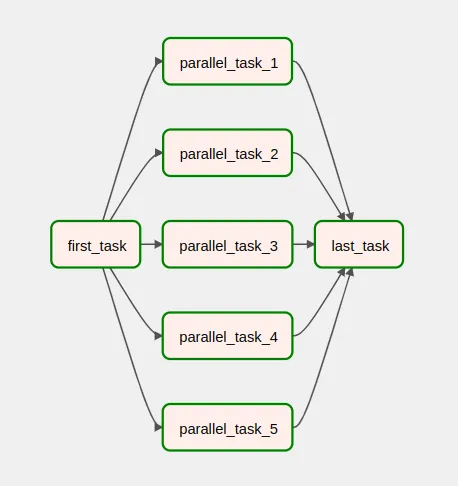
Description of trigger rules
In Airflow, task instances can have several states. A list of them is available in the Graph View of the UI:

To understand the basic trigger rules, just consider the states failed, skipped, success and upstream_failed. They are fairly self-descriptive, although we will define them in order to better understand the logical conditions underlying the argument.
- failed implies that a task failed.
- skipped means that the task failed to execute, although the upstream tasks did not fail.
- succes means that the task was successfully executed.
- upstream_failed means that the task was not executed because the upstream tasks failed.
Types of trigger rules in Airflow
Including the all_success option we saw earlier, Airflow offers the following trigger rules:
| success | done* | skipped | failed | |
| none | none_skipped | none_failed / none_failed_min_one_success / none_failed_or_skipped | ||
| one | one_success | one_done | one_failed | |
| all | all_success | all_done | all_skipped | all_failed |
| always / dummy | always / dummy | always / dummy | always / dummy |
*done refers to tasks actually executed, successfully or unsuccessfully.
- none_skipped: No upstream task is in skipped state.
- none_failed: No upstream task is in failed or upstream_failed state.
- none_failed_or_skipped: No upstream task is in the skipped, failed or upstream_failed state.
- none_failed_min_one_success: No upstream task is in the failed or upstream_failed state and at least one of them is in the success state.
- one_success: Of the upstream tasks, at least one is in the success state. This trigger rule does not wait for the other tasks to finish.
- one_done: Of the upstream tasks, at least one was executed (whether it ended in success or failed status).
- one_failed: Of the upstream tasks, at least one is in the failed or upstream_failed state. This trigger rule does not wait for the other tasks to finish.
- all_success: All upstream tasks are in success state.
- all_done: All upstream tasks have been executed (whether in success or failed state).
- all_skipped: All upstream tasks are in skipped state.
- all_failed: All upstream tasks are in failed or upstream failed state.
- always: The task will run regardless of the status of the upstream tasks.
Use cases of trigger rules in Airflow
In many cases, the default option all_success is sufficient to ensure that tasks are executed in the order determined by their respective dependencies. In other occasions, the workflow may contain certain complexities that make all_success a limitation.
A clear case in point is the use of branching. By making the execution of one or another task dependent on a condition, subsequent tasks in the execution flow may depend on only one of them having been successfully executed. An example case with branching would be the following:
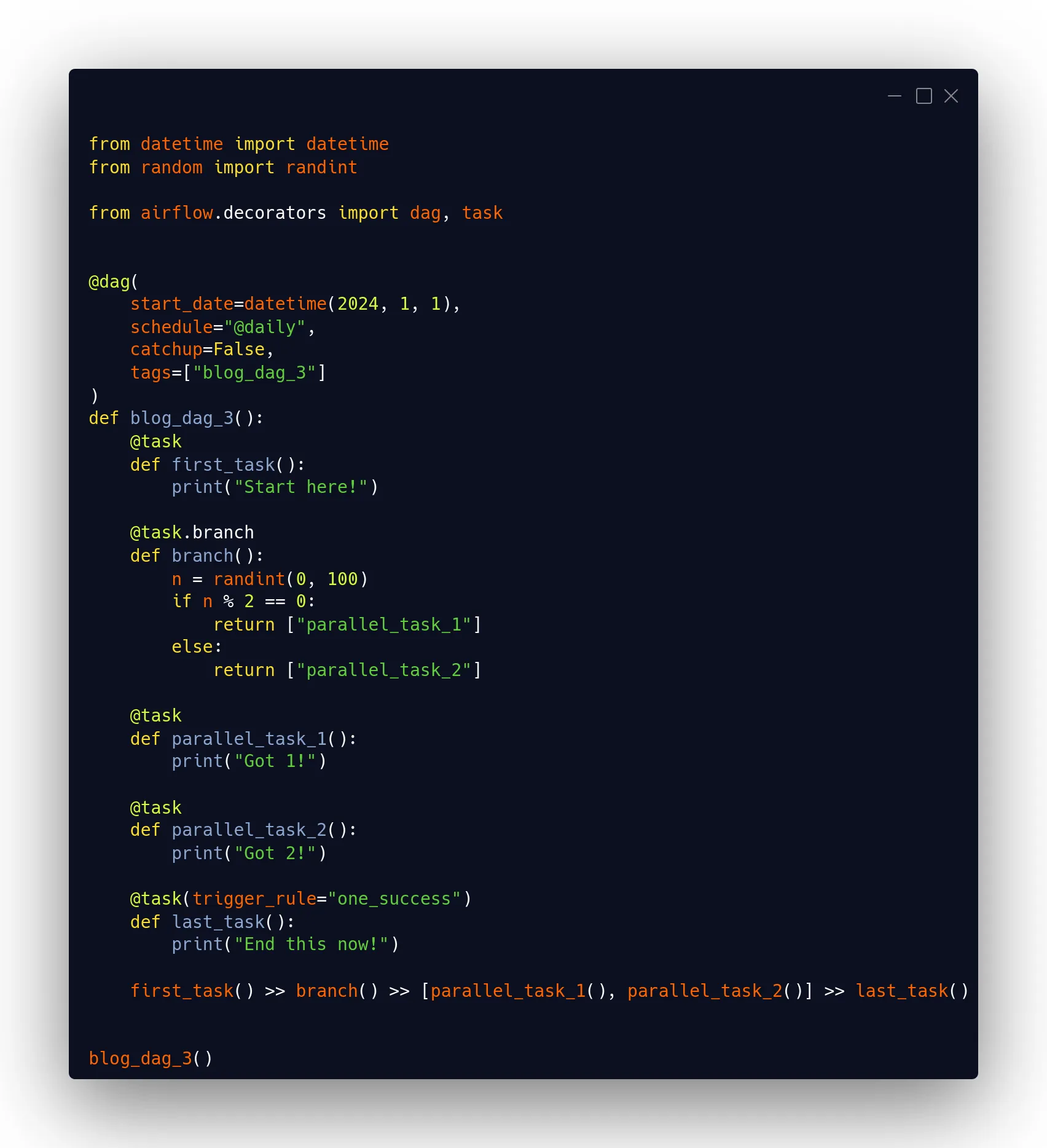
Sometimes branching will determine that parallel_task_1 and sometimes parallel_task_2 is executed. However, with the trigger rule one_success the last_task will run regardless of which one ends in success.
In this other case, sometimes the compute_odd_no process fails. When this happens, a send_warning process is executed which would, for example, send a notification. And when compute_odd_no fails, the send_warning task is not executed.
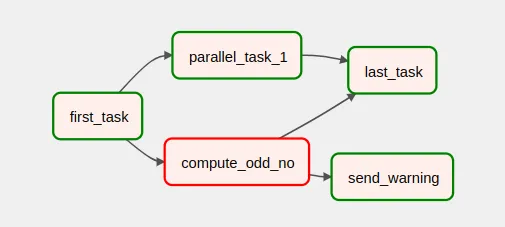
In this case, last_task also has a trigger rule one_success. It is important to note that, even if neither parallel_task_1 nor compute_odd_failed, the execution of last_task would start as soon as one of the two had terminated on success, without waiting for the other process to finish.
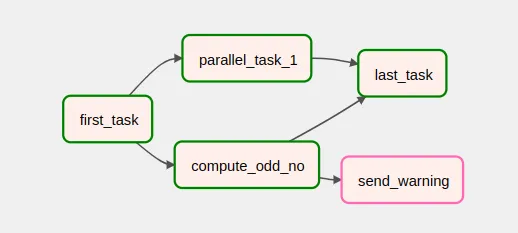
Further than trigger rules
At the beginning of this entry, the use of sensors and the management of dependencies between DAGs were already mentioned as additional elements to trigger rules to control the execution flow of tasks. This should cover most use cases in ETL processes. However, there may be situations where these tools are insufficient or too complex to integrate compared to implementing logic in the task code.
Some examples include:
- Dependencies on specific statuses where a combination of upstream tasks have ended with specific statuses. For example, if in DAG 1 you would like to execute last_task only if parallel_task_1 and parallel_task_2 have ended in success and the other 3 in failed.
- Dependencies based on the nature of the error eventually produced. For example, execute a task if the upstream task has ended with an error of type ValueError, but not if the type of the error is any other.
- Dependencies based on the structure of the input data in a process.
- Dependencies that do not conform to the structure of a DAG, such as interdependent tasks.
In these cases, it is better to handle dependencies internally within tasks rather than with the tools offered by Airflow. In other contexts, handling dependencies within tasks may be preferable to reduce complexity in DAGs. These complexities will need to be weighed to decide which solution is best in each case, taking into account factors such as simplicity and interpretability of the code.
Conclusion
This post has reviewed the trigger rules that Apache Airflow offers to manage dependencies between tasks in the same DAG. The available trigger rules are enough to orchestrate most of the use cases in ETL processes and knowing the options can be useful to avoid having to introduce complexity in the DAGs. In any case, and as a final note, it is worth remembering that, even with the other tools that Airflow offers, there may be examples in which it is not entirely worth using them or they may be insufficient to manage a specific type of dependency.
That’s it! If you found this article interesting, we encourage you to visit the Airflow tag with all related posts and to share it on social media. See you soon!
