
La llegada de Apache Spark 4.0 se está haciendo esperar, pero para alentar a la comunidad, la famosa fundación ha liberado un preview access de la versión. Hace ya unos meses, los desarrolladores de Databricks contaron un pequeño avance de lo que nos espera anunciando las novedades en un vídeo. En este artículo, haremos un resumen y explicaremos las principales novedades de la nueva versión.
El equipo de Apache ha tratado de actualizar el famoso framework buscando la mejora en eficiencia, ampliando la compatibilidad con APIS y lenguajes de desarrollo y facilitando el uso para desarrolladores y analistas de datos. Si eres un fan de esta herramienta, no te puedes perder las novedades que mostraron en la presentación de Spark 4.0 y que comentaremos en detalle en este post.
Nuevas funcionalidades de Spark 4.0
Spark Connect
Con Spark 4.0 llega Spark Connect, una API cliente que se coloca entre los usuarios de Spark y el driver, unificando la forma en que éstos se comunican con el sistema. Gracias a esta nueva implementación, los usuarios podrán conectarse a Spark de manera más flexible y ligera.
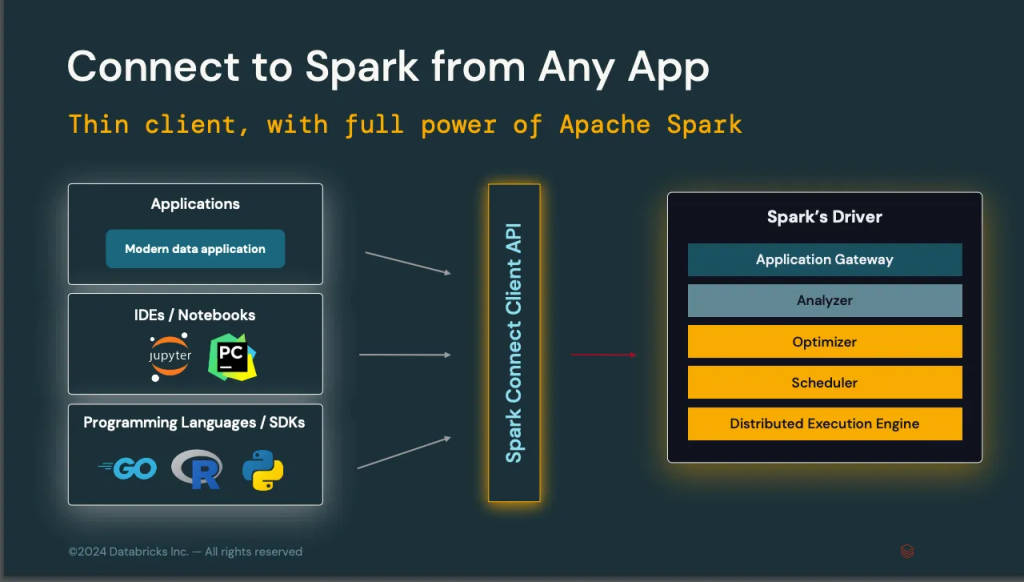
Esta nueva API podrá instalarse sencillamente con pip install pyspark-connect. Esta librería pesa solamente 1.55 MB, frente a los 355MB de PySpark.
Con esta nueva API, mejora la latencia de las consultas interactivas tipo REPL.
ANSI Mode por Defecto
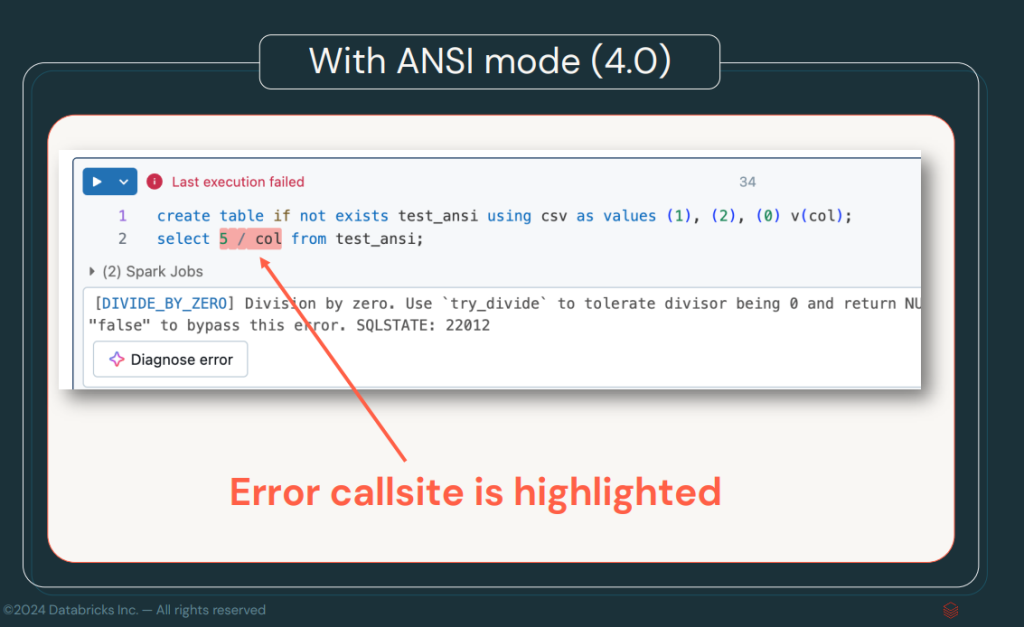
En esta nueva versión, ANSI Mode estará activada por defecto, lo que en versiones anteriores habría necesitado activarse con spark.sql.ansi.enable=true. Este modo garantiza que las operaciones SQL se ajusten a las reglas y comportamientos establecidos en el estándar ANSI SQL, lo que asegura una mayor compatibilidad con otros sistemas y bases de datos SQL. La principal ventaja que ofrece es la robustez a la hora de operar con las sentencias SQL y la mejora en el tratamiento de errores.
El modo ANSI permitirá la detección de errores más rápida por parte de Spark. En otro post, podemos tratar este estándar en más profundidad, pero, básicamente, nos permite evitar errores de conversión no válidos, división entre 0, operaciones que violan la integridad de los datos, etc.
Tipos de Datos Variant
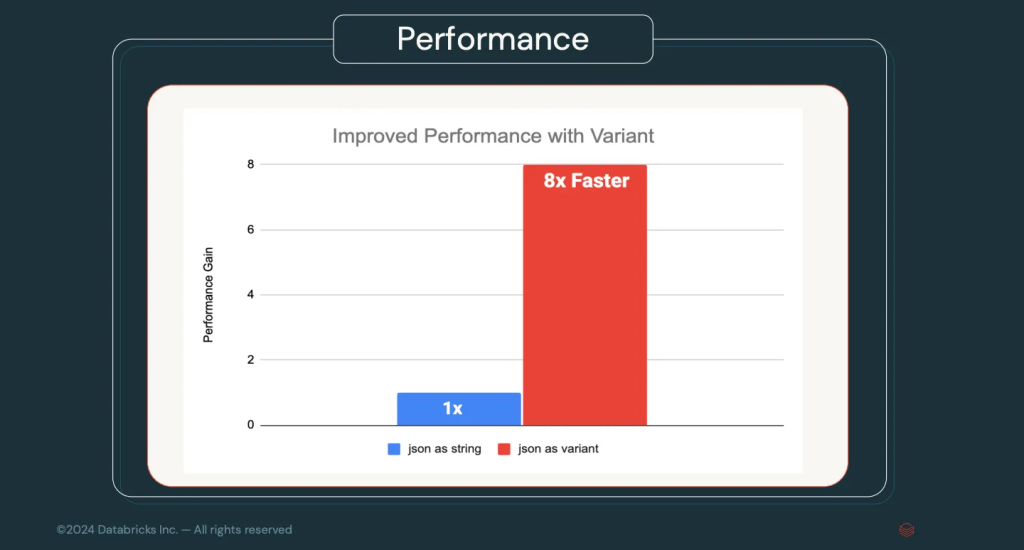
Hasta ahora, los datos complejos como JSON se trataban como cadenas de texto y se estructuraban mediante la operación PARSE_JSON. Con los nuevos tipos de datos Variant, Spark podrá manejar estos datos de forma nativa, lo que promete un rendimiento hasta 8 veces más rápido en las consultas que involucren JSON.
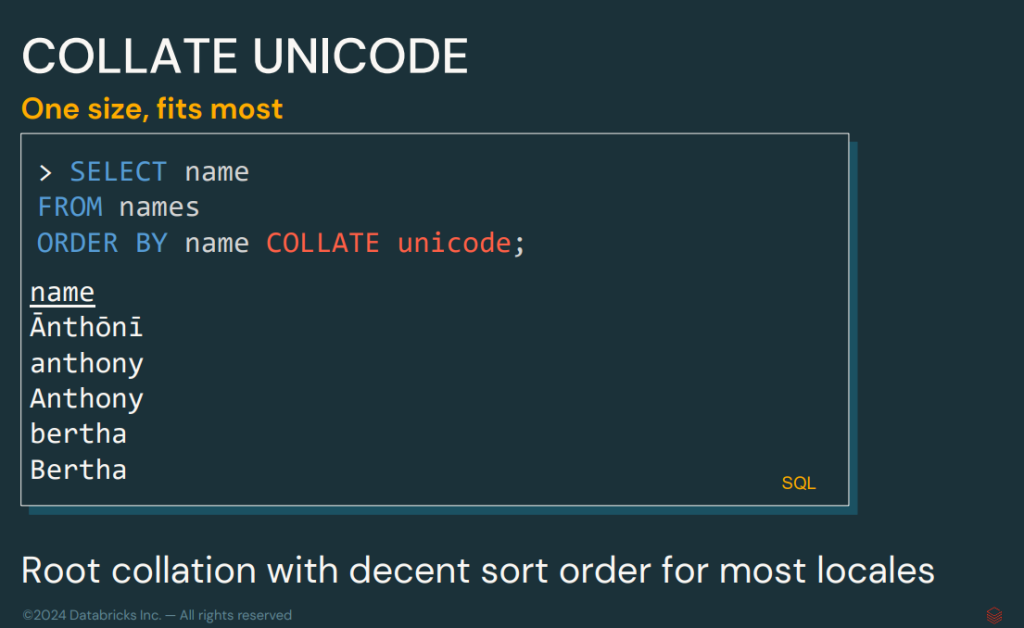
Soporte para Collation
El soporte para Collation introduce la capacidad de ordenar y comparar datos teniendo en cuenta la configuración regional. Este sistema permitirá trabajar de manera más sencilla con las operaciones entre alfabetos, idiomas, mayúsculas y minúsculas, entre otros ejemplos.

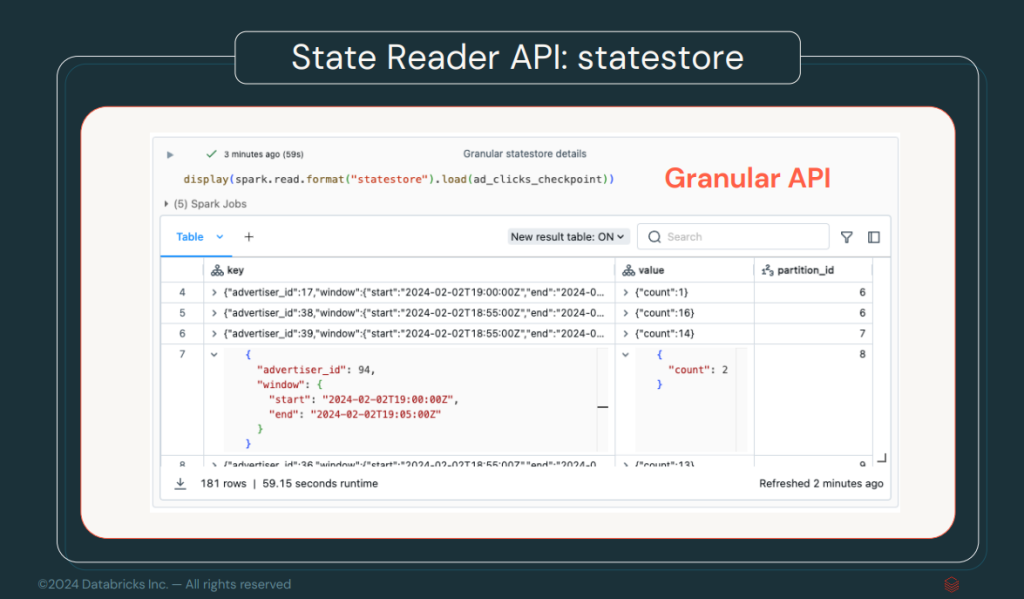
Streaming State Data Source
Una de las grandes mejoras en el procesamiento de streaming es la adición del Streaming State Data Source. Este nuevo Data Source permite acceder al estado interno de una aplicación en streaming. Esto se logra conectándose al checkpoint almacenado, por ejemplo, en un S3, mejorando la visibilidad del estado en aplicaciones de tiempo real.
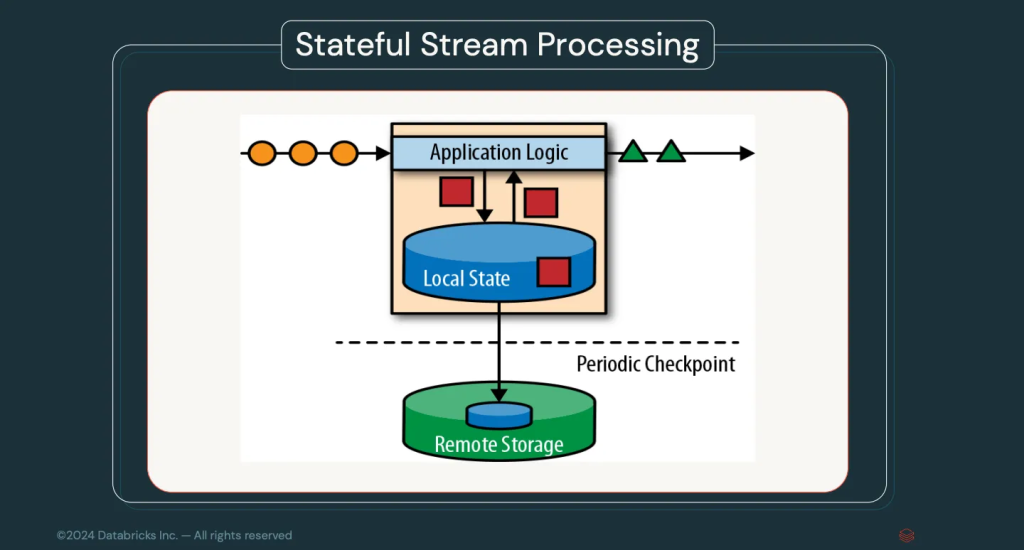
Arbitrary Stateful Processing V2
En esta versión, se amplía la capacidad de esta conocida funcionalidad. Recordemos que este sistema nos brinda la posibilidad de guardar un estado en una operación de streaming. Por ejemplo, en una suma acumulativa, mantener el resultado de la suma en cada evento del stream para poder continuar con el conteo.
Por otra parte, en esta versión el sistema soporta el estado de streaming por cada agrupación en un groupByKey. El estado podrá ser actualizado conforme se evalúa el grupo actual y dicha actualización estará disponible en el siguiente evento.
Extensiones de Apache Spark 4.0
Data Source en Python para Streaming y Batching
Esta funcionalidad es una de las más importantes y que, desde mi punto de vista, más juego va a dar a la comunidad. Se ha ampliado el soporte para el desarrollo de DataSources a Python de manera nativa. Esto permitirá a la amplia comunidad de Python desarrollar sus propios DataSources de una forma muy orgánica y ponerlos al servicio de otros usuarios.

Dataframe.toArrow y GroupedData.applyInArrow
La apuesta del equipo de desarrollo por Apache Arrow está siendo total. En esta ocasión, se integra Apache Arrow para el desarrollo de UDFs en Python. El método Dataframe.toArrow simplifica la conversión entre un DataFrame de PySpark y una tabla de PyArrow. Por su parte, GroupedData.applyInArrow permite paralelizar el trabajo en grupos, lo que mejora significativamente el rendimiento y la conveniencia en tareas intensivas.
Conector XML Nativo
Una de las nuevas características es la incorporación de un parser XML nativo tras haber integrado una librería de terceros que se utilizaba para este fin. Esto agiliza la carga y procesamiento de datos en formato XML sin depender de librerías externas.
spark.read.xml("/path/to/my/file.xml").show().Conector Databricks
Como es de esperar, Databricks ha trabajado e influido sobre el desarrollo para favorecer su ecosistema. Por ello, han añadido una mejora del conector para Databricks, permitiendo cargar tablas de Databricks SQL mediante el prefijo jdbc:databricks, optimizando la conexión y el acceso a estos sistemas de manera más eficiente.
spark.read.jdbc(
"jdbc:databricks://…",
"my_table",
properties
).show()Extensión Delta 4.0
Esta nueva versión de Spark incluye soporte para Delta Lake 4.0 junto con todas sus nuevas funcionalidades.

Por otro lado, se introduce el concepto de Liquid Clustering para mejorar las lecturas y las escrituras en DeltaLake y hacerlas mucho más rápidas.
La manera de lanzar estas optimizaciones es sobre una tabla ya creada y que tenga un clustering por una key. Además, se realiza la operación de OPTIMIZE tbl., La cual se encarga de mejorar el índice y agrupar la tabla creada de manera que se prometen los siguientes incrementos.

Funciones y Procedimientos Personalizados
Python UDTF
Llega una novedad que, desde mi punto de vista, será muy usada por la comunidad. Se trata de la opción de crear funciones Python UDTF (User-Defined Table Functions), que permiten devolver una tabla completa en lugar de valores escalares. Esto abre un nuevo abanico de posibilidades para el procesamiento personalizado de datos.
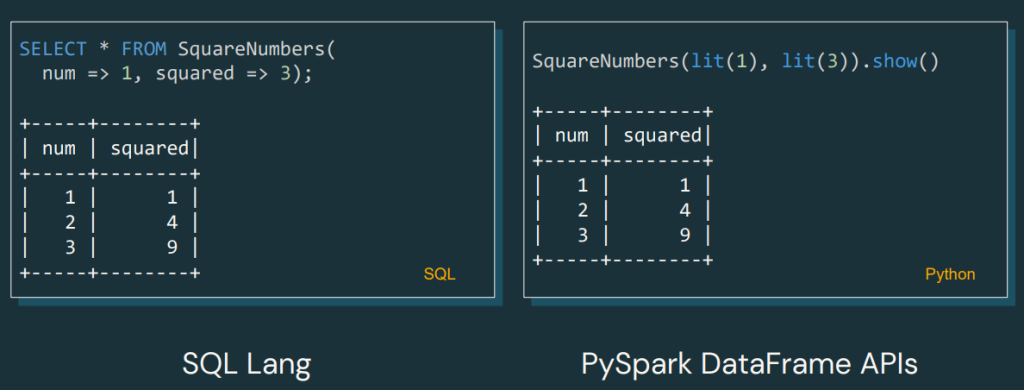
Ejemplo:
Aquí podemos ver cómo el UDF nos devolverá el DataFrame de los cuadrados.
UDF Optimizado con Arrow
Las UDFs ya estaban optimizadas con Arrow desde Spark 3.5, pero, ahora, en Spark 4.0, se activan por defecto. Esto mejora la velocidad de serialización y deserialización, haciendo que el procesamiento de funciones definidas por el usuario sea más rápido y eficiente.
En la siguiente imagen, podemos ver un benchmark del rendimiento del UDF.
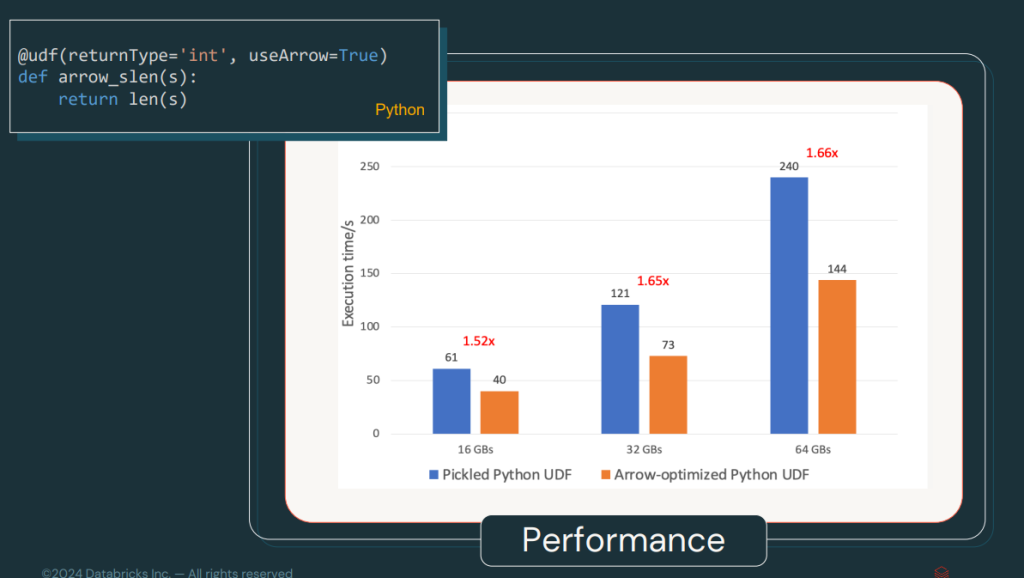
Uno de los secretos para esta mejora es el sistema de pickelización de Arrow UDF, que hace mucho más liviano el compartir la información.
SQL UDF/UDTF
Ahora es posible crear funciones y procedimientos personalizados utilizando el DSL de SQL, lo que permite guardarlas para su uso posterior y eso se podría entender como una especie de Stored Procedures para Spark.

SQL Scripting
Una novedad significativa es el soporte para scripting SQL con operaciones de control como IFs, WHILE, FOR, CONTINUE y muchas otras más, lo que mejora la lógica programática dentro de las consultas SQL.
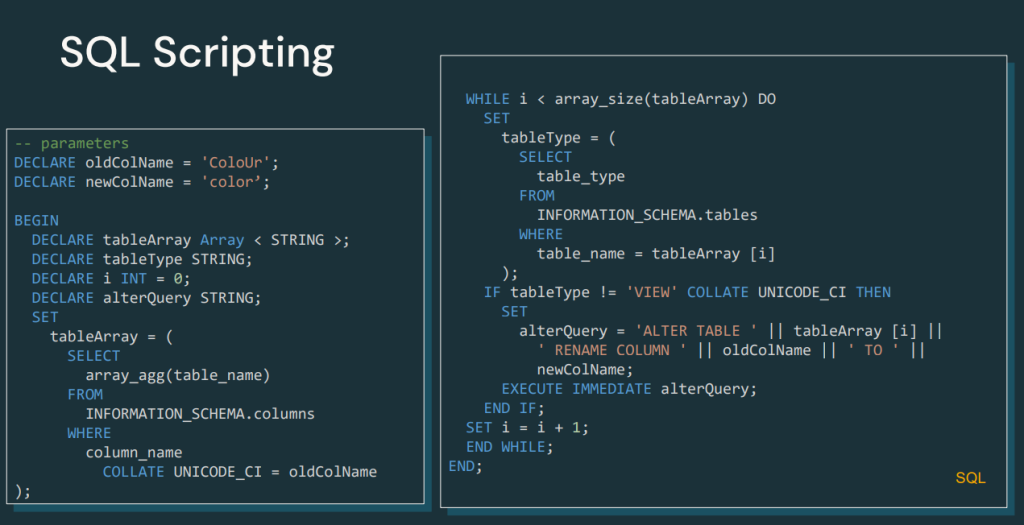
Esta nueva característica abrirá un abanico de posibilidades. Por ejemplo, la integración con frameworks de ELT como DBT, que se podrán incorporar fácilmente e incluso añadir cierta lógica acercándonos más a la programación imperativa.
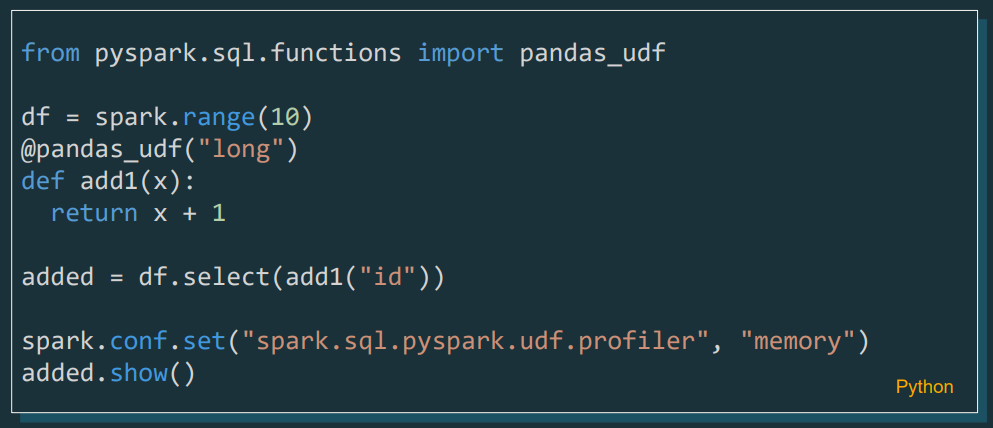
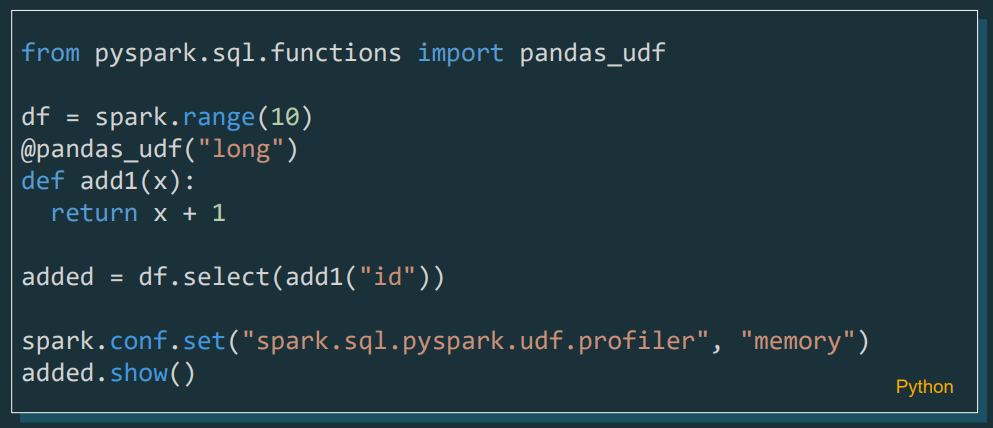
Pyspark UDF Unified Profiler
Ahora, ya se incluye un profiler para UDFs en PySpark, que permitirá a los desarrolladores analizar y optimizar el rendimiento de sus funciones personalizadas con mayor detalle, tanto para el análisis de la memoria utilizada, como del tiempo invertido para la función.
Usabilidad y Mejoras de Experiencia
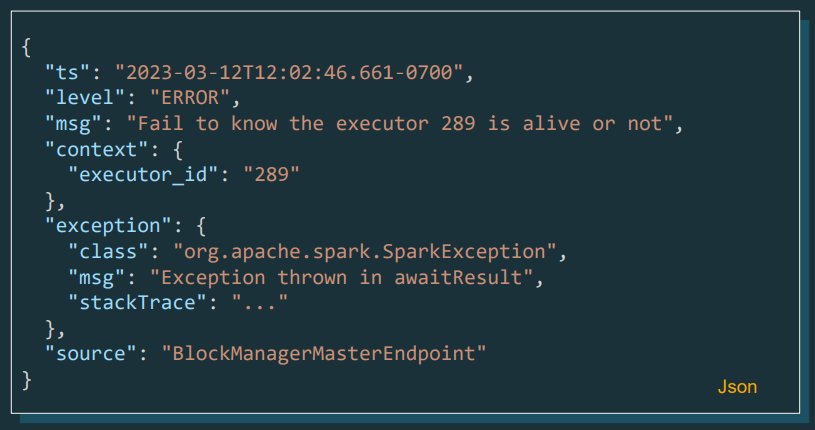
Structured Logging Framework
Los logs estructurados son una de las grandes mejoras de esta versión. Ahora, los registros podrán ser analizados y consultados directamente desde Spark, permitiendo cargar logs del sistema para su análisis posterior.
Pasamos de:

A un formato de logs que podremos cargar y leer con Spark:
Mensajes y Condiciones de Error Mejoradas
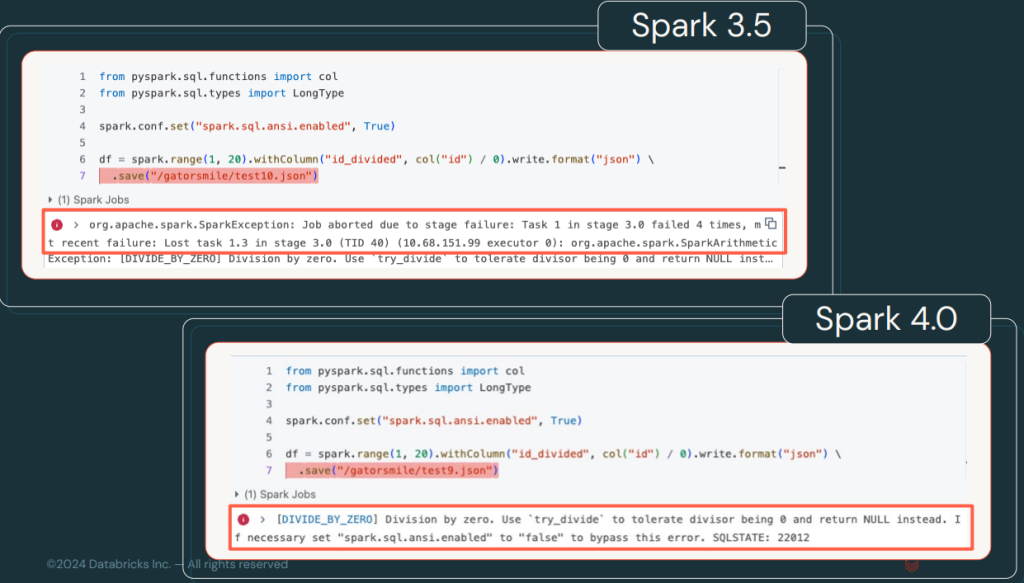
Los errores en Spark 4.0, ahora estarán categorizados y clasificados con códigos específicos que permitirán identificar y solucionar problemas más rápidamente. Esto mejora la documentación y facilita la depuración.
Puedes consultar una lista de estados, códigos y condiciones de error que Spark SQL puede devolver en la documentación de Spark.
Para visualizar mejor el cambio, veamos la diferencia entre los errores en una versión y otra.
Cambios de Comportamiento
Se han realizado ajustes importantes en cuanto a la retrocompatibilidad y la gestión de versiones. Las categorías de impacto, te permitirán evaluar mejor los cambios al actualizar Spark y determinar si afectan tus flujos de trabajo.
En esta parte, tendremos que ver cómo se aplica, ya que cambia la forma en la que se aumentan las futuras versiones, se han realizado una serie de categorías y, dependiendo de la categoría del cambio, se modificará la versión para que la comunidad pueda entender si puede migrar a la nueva sin riesgos.
Mejora en la Documentación
La nueva documentación de Spark 4.0 incluirá más ejemplos, configuraciones de entornos y guías rápidas para facilitar la adopción de las nuevas funcionalidades. Además, se incluirá soporte para conversiones de tipos de datos más robustas.
Conclusión
Spark 4.0 se ha hecho esperar, pero trae novedades que yo creo que están muy en sintonía con las tendencias de la comunidad. Por ejemplo, podemos subrayar las mejoras en la integración con Python y SQL, lo cual considero que era algo necesario para reducir la complejidad de acceso al framework.
Por otro lado, la inclusión de nuevos conectores, mejoras en el manejo de logs y un enfoque en la usabilidad, hace que Spark 4.0 sea una plataforma más accesible y potente. Ya sea que trabajes con Big Data, Machine Learning o streaming en tiempo real, esta actualización trae mejoras que potenciarán todos tus proyectos.
