
Este artículo asume que hay un conocimiento base de embeddings de objetos, ya sean de texto o imágenes. En caso de que no se tengan nociones sobre el tema, el post sobre Text Embeddings: la base del NLP moderno explica este concepto.
Cuando queremos trabajar con datos altamente dimensionales, como embeddings de textos o genomas, tenemos el problema de que las bases de datos clásicas, como aquellas basadas en SQL o incluso una gran cantidad de bases de datos noSQL, son incapaces de tratar estos datos de forma apropiada.
Por ejemplo, si se quisiera recuperar todo elemento similar a un elemento específico, se tendría que leer todo valor en la base de datos y calcular las distancias o similitudes posteriormente. Esto es extremadamente ineficiente, ya que, intuitivamente, no todo elemento es similar y solo queríamos leer aquellos elementos similares, puesto que, si tenemos una base de datos con terabytes de documentos, una simple query sería prohibitiva.
Normalmente, esto en bases de datos típicas no es un problema, ya que no se hacen búsquedas aproximadas. Sin embargo, en el caso de los embeddings el único tipo de búsqueda posible es la búsqueda por similaridad, por tanto, los típicos índices que se emplean no son capaces de tratar estos datos.
Nos encontramos entonces con el problema de que nuestro tipo de datos no se ajusta a los casos de uso que las bases de datos implementan. Por eso, existen unas bases de datos muy especializadas para este tipo exacto de datos, las bases de datos vectoriales, que implementan índices y algoritmos optimizados para estos casos de uso.
Comparación
Para mostrar el efecto que estas bases de datos tienen, primero podemos ver la diferencia en el tiempo para obtener las distancias entre embeddings de distintas bases de datos vectoriales con el método clásico de computar toda distancia. Para esta comparación, generamos embeddings completamente aleatorios, sin significado, asociados todos al mismo texto.
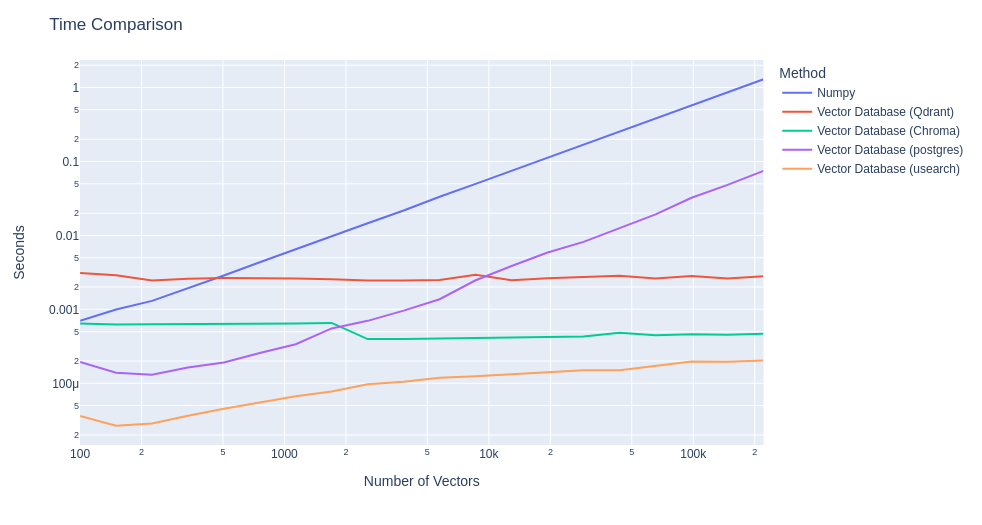
Como podemos ver, el efecto de aplicar una base de datos vectorial es considerable. Se puede observar cómo los tiempos de ejecución usando solo Numpy crecen en relación a la cantidad de elementos a indexar, llegando a 1 segundo con 200.000 elementos, mientras que bases de datos vectoriales como Chroma, Qdrant o Usearch mantienen un tiempo casi constante respecto a la cantidad de elementos.
Las bases de datos vectoriales implementan algoritmos ANN (Approximate Nearest Neighbors) como HNSW (Hierarchical Navigable Small Worlds). Estos algoritmos intentan solucionar el problema de encontrar los elementos más cercanos a un elemento sin tener que observar todo el espacio que contiene dicho elemento. Esto es debido a que observar todo el espacio crece proporcionalmente con la cantidad de elementos en el mismo, haciendo que el algoritmo sea más y más lento.
También hay que mencionar que ciertas bases de datos vectoriales implementan optimizaciones a nivel de hardware, ya que procesadores modernos suelen integrar instrucciones que pueden operar sobre vectores de forma nativa y extremadamente eficiente, como AVX en el caso del set de instrucciones de x86.
Casos de uso de bases de datos vectoriales
Ahora entendemos que usar la base de datos apropiada para este tipo de datos es vital. Podemos querer indexar embeddings, después de todo, está bien saber qué elementos son similares a otros desde un punto de vista semántico pero, ¿cuál es el caso de uso donde esto nos sería útil?
El escenario clásico para similaridad de embeddings fueron las búsquedas semánticas de documentos, donde todo documento está indexado por su embedding o múltiples embeddings, cada uno basado en diferentes partes de éste, y la búsqueda es un texto en lenguaje natural.
Por ejemplo, podemos tener indexadas una serie de descripciones de producto y querer encontrar artículos similares a otros semánticamente. O podemos tener indexados varios documentos legales y queremos recuperar aquellos que contengan información respecto a un evento.
Un caso de uso popular antiguo era la búsqueda de imágenes, donde se usaban embeddings de imágenes para buscar otras parecidas, o incluso se intentaban crear embeddings mixtos que pudieran asociar textos con imágenes.
Para ilustrar este ejemplo, hacemos uso de un dataset que contiene enteramente imágenes de plantas donde indexamos estas imágenes puramente por su embedding. Para ello, usaremos la base de datos vectorial de Qdrant.
Planta query 1:

Resultado query 1:




Planta query 2:

Resultado query 2:




Como podemos ver, de esta manera es posible recuperar fácilmente imágenes similares usando una base de datos vectorial y un modelo de embeddings.
Actualmente, el caso de uso más popular y la razón del auge y popularidad de las bases de datos vectoriales es debido al RAG (Retrieval Augmented Generation). Esta técnica se usa para poder nutrir de contexto necesario a un LLM sin necesidad de tener que reentrenarlo.
Por ejemplo, queremos hacerle una consulta sobre ciertos productos, pero al no estar entrenado en exactamente esos productos, se inventará una respuesta. La solución sería alimentar la descripción de dichos productos de forma que en el contexto tenga todo lo necesario para solucionar la consulta. Este contexto lo podemos guardar en una base de datos vectorial para que, cuando llega la consulta, buscamos en la base de datos aquellos documentos relacionados y que puedan dar contexto y generamos una nueva consulta con el contexto añadido.
Si aplicamos RAG sin una indexación apropiada de los documentos podría requerir de varios minutos, mientras que con bases de datos vectoriales puede requerir de solo unos segundos más. A la vez, evitamos tener que reentrenar el LLM, algo que puede ser prohibitivamente caro.
Hoy en día existen varias bases de datos vectoriales o que tienen funcionalidades vectoriales, como postgres con la extensión pgvector, ChromaDB, Usearch, Qdrant, Pinecone, Redis, Neo4J, MongoDB, OpenSearch, etc. Cada una de ellas ofrece diferentes características y es necesario efectuar un estudio apropiado sobre las necesidades funcionales para decidir cuál se usa.
Por ejemplo, Qdrant es capaz de escalar horizontalmente con facilidad debido a que puede correr nativamente en un cluster de kubernetes, mientras que, por ejemplo, Usearch escala mejor verticalmente. Podemos ver una comparación de diferentes bases de datos vectoriales y las funcionalidades que ofrecen en Superlinked.
También se han de considerar las funcionalidades extras que pueden implementar. En este caso, nos hemos centrado en la funcionalidad principal, la obtención de embeddings similares a un embedding dado. Sin embargo, dependiendo de la base de datos, se pueden implementar elementos como otros tipos de filtro basados en metadatos, la capacidad de usar embeddings esparsos, integración con herramientas de RAG populares como LangChain o LlamaIndex, la opción de cuantificar los embeddings, etc.
Conclusión
Las bases de datos vectoriales son unas bases de datos especializadas para calcular similitudes o distancias, principalmente en espacios Euclidianos, de forma que obtener elementos similares es lo más óptimo posible. Esto permite que ciertos casos de uso, como el RAG, puedan operar en tiempos razonables.
Es recomendable evaluar si datos vectoriales podrían enriquecer nuestros datos y si los sistemas en uso pueden beneficiarse de ellos, permitiendo así enriquecer nuestras aplicaciones.
Si te ha parecido interesante este artículo, te animamos a que visites la categoría Data Engineering para ver otros posts similares y a que lo compartas en redes. ¡Hasta pronto!
