
Una de las peculiaridades de SQL y sus muchos dialectos es que intentan añadir funcionalidades que no están presentes en ANSI SQL. Este fenómeno es tan común, que es habitual encontrar que cada dialecto implementa dichas funciones de una forma muy similar, pero no idéntica.
Operador pipe: Qué es y cómo funciona
En este sentido, podemos mencionar como caso extremo el de GoogleSQL. Recientemente, este servicio añadió un nuevo operador para intentar solventar algunos de los problemas más frecuentes del SQL clásico.
La nueva adición a GoogleSQL del operador pipe hace posible cambiar cómo se plantea una query. Básicamente, lo que hace sería como dividir una query en varias CTE (Common Table Expression) de forma que cada una de ellas representa un paso en el procesamiento de datos.
Pipe operator en consultas complejas
El mayor problema con entender las queries complejas en SQL es el orden sintáctico comparado con el orden semántico. En la siguiente imagen, podemos ver un ejemplo:
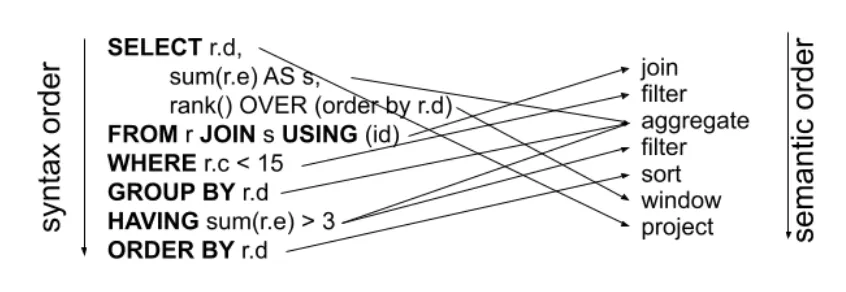
El objetivo de pipe operator es solucionar esta discrepancia modificando la manera en la que se escribe la query para que coincidan orden sintáctico y semántico. De esta forma, además de simplificar la query, la hace mucho más entendible.
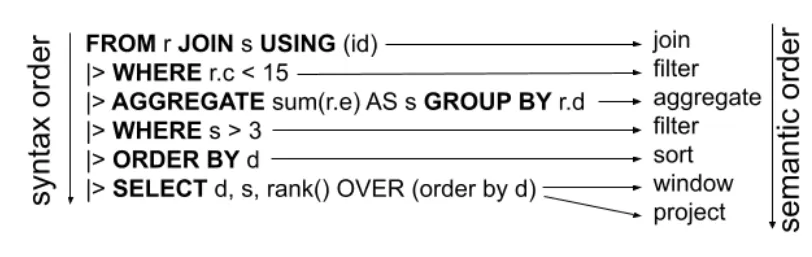
Para definir el operador pipe se emplea el símbolo de pipe, |>, el operador a ejecutar y los argumentos. Por ejemplo, |> SELECT column1, column2. Además, se pueden encadenar infinitamente mientras sean operaciones válidas. En la página oficial de Google Cloud, está la lista completa con la sintaxis para consultas del operador pipe.
Organizar la sintaxis de esta manera supone grandes ventajas. Cuando tenemos queries más complejas, que muchas veces hacen uso de subqueries, es difícil evaluar su comportamiento. Esto provoca que el mantenimiento y debuggeo resulten extremadamente difíciles cuanto más crece la query. Sin embargo, con una organización lineal, es posible analizar cada paso aplicado individualmente. De esta manera, se simplifican considerablemente dichas consideraciones.
Ejemplo de query con pipe operator
A continuación, veremos el estado del código en su forma de origen:
WITH users AS (
SELECT 1 AS user_id, 'Alice' AS first_name, 'Smith' AS last_name
UNION ALL
SELECT 2, 'Bob', 'Johnson'
UNION ALL
SELECT 3, 'Carol', 'Williams'
),
products AS (
SELECT 101 AS product_id, 'Laptop' AS product_name, 1200.00 AS price
UNION ALL
SELECT 102, 'Phone', 800.00
UNION ALL
SELECT 103, 'Headphones', 150.00
),
orders AS (
SELECT 1001 AS order_id, 1 AS user_id, 101 AS product_id, '2025-09-01' AS order_date
UNION ALL
SELECT 1002, 1, 103, '2025-09-01'
UNION ALL
SELECT 1003, 2, 102, '2025-09-02'
UNION ALL
SELECT 1004, 3, 101, '2025-09-03'
UNION ALL
SELECT 1005, 2, 103, '2025-09-04'
)En el siguiente bloque de código, mostraremos la query en su forma original:
SELECT
u.user_id,
u.first_name,
u.last_name,
(
SELECT COUNT(*)
FROM orders o
WHERE o.user_id = u.user_id
) AS total_orders,
(
SELECT SUM(p.price)
FROM orders o
JOIN products p ON o.product_id = p.product_id
WHERE o.user_id = u.user_id
) AS total_spent,
(
SELECT STRING_AGG(p.product_name, ', ')
FROM orders o
JOIN products p ON o.product_id = p.product_id
WHERE o.user_id = u.user_id
) AS products_ordered
FROM users u
ORDER BY total_spent DESC;Los resultados obtenidos serían los siguientes:
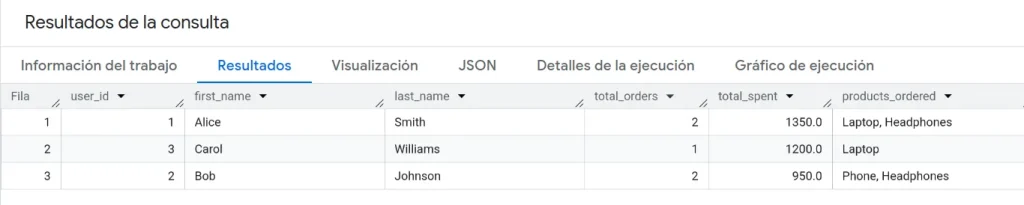
Ahora, procedemos a lanzar la misma query pero con pipe operator:
FROM users
|> JOIN orders ON orders.user_id = users.user_id
|> JOIN products ON products.product_id = orders.product_id
|> EXTEND COUNT(*) OVER orders AS total_orders
WINDOW orders AS (PARTITION BY users.user_id)
|> EXTEND SUM(products.price) OVER products AS total_products
WINDOW products AS (PARTITION BY users.user_id)
|> EXTEND STRING_AGG(products.product_name, ', ') OVER orders AS name_orders
WINDOW orders AS (PARTITION BY users.user_id)
|> SELECT DISTINCT users.user_id, users.first_name, users.last_name, total_orders, total_products, name_orders;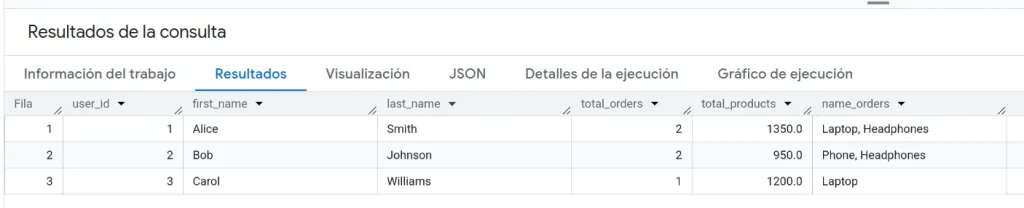
Conclusión
Los pipe operators permiten cambiar cómo se estructura una query SQL a una forma más intuitiva, donde el orden semántico y el orden sintáctico se corresponden. De esta manera, permiten entender más fácilmente queries complejas, facilitando su mantenimiento y evolución.
¡Esto es todo! Si este artículo te ha parecido interesante, te animamos a visitar la categoría Data Engineering para ver todos los posts relacionados y a compartirlo en redes. ¡Hasta pronto!
