
We begin a collection of tutorials on the use and operation of DataHub, a Data Governance platform that we already mentioned in the post What is a Data Catalog and what does it consist of. In this series, we explore the concept of data governance from a more practical perspective.
DataHub is an open source tool, a crucial aspect to understand why it stands out among the best data governance platforms. For cross-cutting tasks like this, third-party or open source tools are the best choice. The reason is simple: many of the big competitors approach the data governance challenge from a biased and self-serving perspective, offering solutions that primarily integrate their own products, often resulting in a vendor lock-in. This does not cover the wide variety of real-world architectures, which may include hybrid solutions across multiple clouds or on-premise-cloud architectures largely composed of open source technologies.
DataHub has created a robust community that develops its own integrations with other platforms, which encourages developers of those platforms to integrate their solutions, such as data warehouses, with minimal effort.
As a data governance platform, DataHub offers a comprehensive solution for the integration of multiple data sources, ETL/ELT transformation systems and visualisation or consumption systems. All of this is managed from a single web platform, facilitating the democratisation of data within the organisation and enabling easy data sharing. In addition, DataHub includes a data incident reporting system, promoting collaboration in the improvement of data quality by any user.
Data Hub Architecture
DataHub is a platform developed by LinkedIn, designed to offer a comprehensive data governance solution. This involves many aspects that, in my opinion, make the architecture more complex in exchange for covering extra functionalities than a simple Data Catalog. DataHub is geared towards solving data quality problems through a comprehensive data observability system, often including real-time integrations with various data sources. Let’s look at how the DataHub components communicate from a great height.
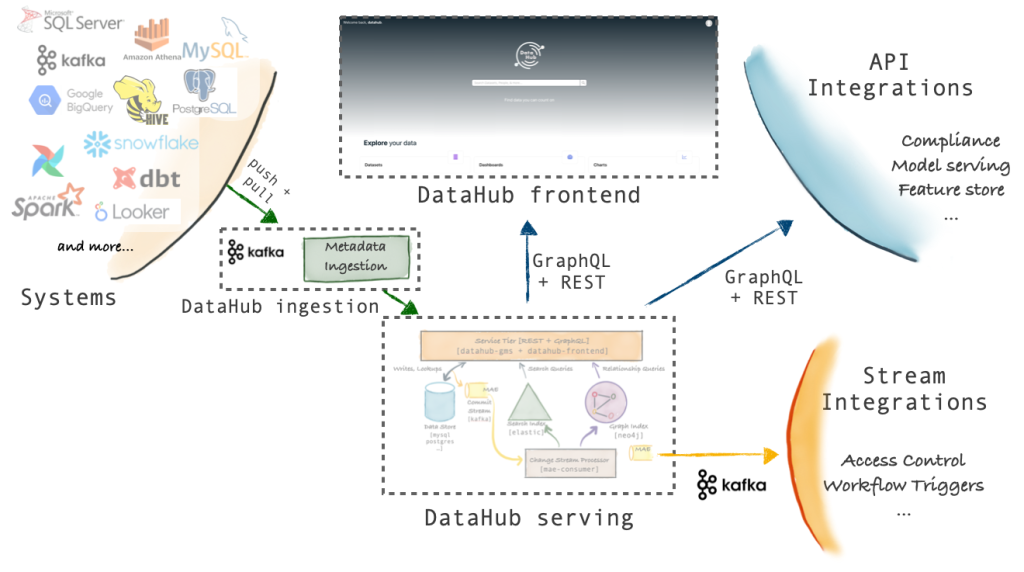
As we can see, the different sources supported in DataHub can be ingested through the ‘Push / Pull DataHub Ingestion’ system, which allows through Api or Kafka the ingestion of information within DataHub. We can also observe that DataHub exposes an Api Rest with GraphQL to be able to query and serve the information. Mainly, this component connects with the frontend.
DataHub under the hood
DataHub relies on MySQL and Elasticsearch as its two main components for the persistence of all the metadata and schemas of our organisation.
The metadata service, better known as GMS, is the heart of DataHub and is responsible for connecting to the persistence layer, centralising what is to be stored and how it passes through this component. Against the GMS service connects both the ingest service and the visual component of DataHub in web form.
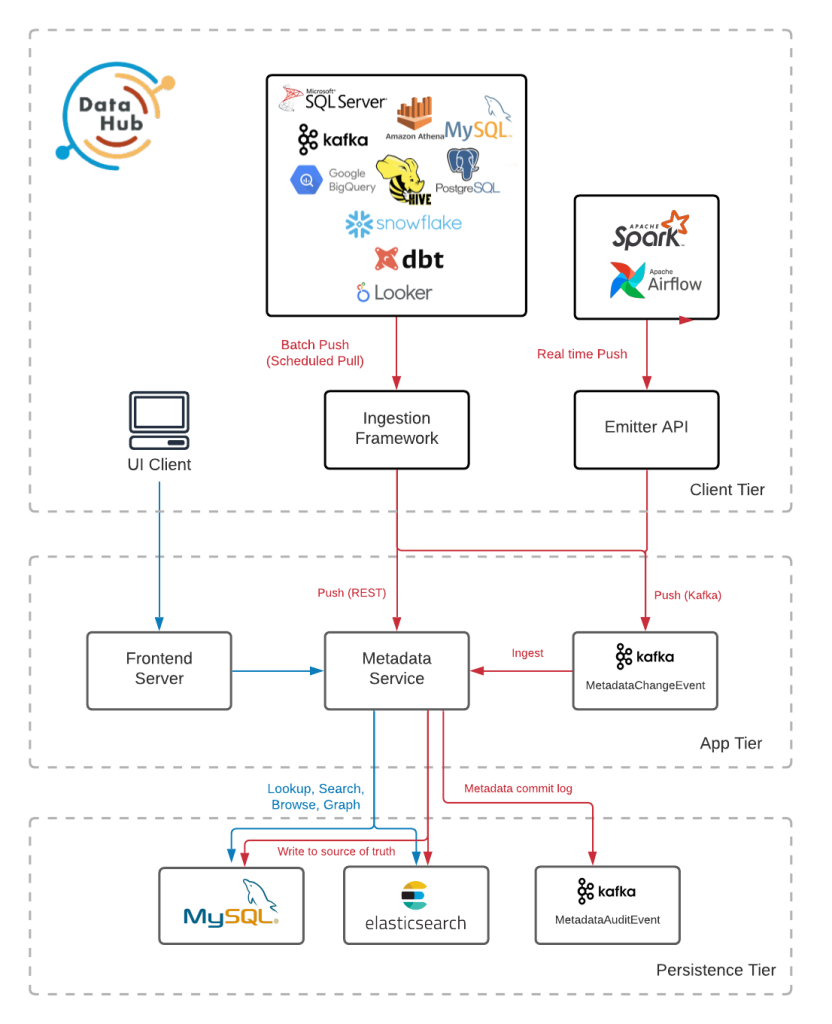
Metadata Service or GMS
This is the component on which all the others revolve. It is an application developed in Java and relies on two technologies:
- GraphQL api, which is used for updating and querying the application’s metadata. This api exposes two different endpoints:
- localhost:8080/api/graphiql (metadata-service). This endpoint would be the one we can use publicly. We will see examples of its use later, as it is often used for automated data ingestion purposes.
- localhost:9002/api/graphiql (datahub-frontend-react). This service is not publicly accessible, in fact it is protected by default authentication.
- Api Rest.li which is in charge of managing the raw models in PDL. This api is used internally by the system, hence the raw data returned.
Internally, GMS uses PDL (Pegasus Data Language) for the definition of the schemas of the different metadata. The PDL project has also been developed by LinkedIn and facilitates both the validation of data against schemas and their generation and interoperability.
Ingest Service
The metadata ingestion within DataHub, as we have already mentioned, can be done in two ways through the Push/Pull Api service.
When we use the push system, we are sending the data directly to the metadata service, either through the Rest Api, or through a Kafka topic that we enable for that purpose. The responsibility for sending the data falls directly on the sender, this has a clear advantage, the data is kept up to date in real time. The disadvantage of this system is that all the logic and responsibility falls on the sender, so we transfer an extra responsibility to a microservice that perhaps should not have it. For this, we can make use of architectural patterns to limit the impact of having such logic in our applications or systems.
The pull system is the complete opposite of push. In the previous system, the sender was the one who had the initiative to send the information and, in this case, the initiative is taken by DataHub, which is the one who asks the source for the metadata it will need. This system works quite well with DataWarehouse platforms, as it allows to ask for changes in the tables and their content.
Around an ingest task there are four key concepts that relate to each other.
- Recipes: These are the configuration files for metadata ingestion. Basically, it tells the system which sources should be ingested and where they should be ingested.
- Sources: A source is nothing more than a component or service within our organisation that will be represented within DataHub. A list of available sources can be found in the DataHub Integrations documentation.
- Transformers: Within a recipe we can define transformations that will affect the sources before reaching their destination. These transformations are designed to customise ingests, allowing you to define, for example, tags, specify the owner, modify a key field of the source, etc.
- Sink: When defining the destination we can choose between two options. The destination can be the datahub-rest service, which would be the default destination. Or the destination can be the datahub-kafka service. There is also the ability to send the data to a console or a file, but this is only done for development and debugging purposes of an ingest.
Persistence layer
Finally, we will look at the persistence layer. In it, we can find two databases, Mysql and Elasticsearch. The first one is in charge of persisting all the metadata of the system, for which it uses the already known PDL and stores them in a single table inside the database.
The table is called metadata_aspects_v2. Let’s see an example record:
| urn | urn:li:corpuser:datahub |
| aspect | corpUserEditableInfo |
| version | 0 |
| metadata | {«skills»:[],»teams»:[],»pictureLink»:»https://raw.githubusercontent.com/datahub-project/datahub/master/datahub-web-react/src/images/default_avatar.png»} |
| system_metadata | |
| created_on | 2024-07-09 11:51:32 |
| created_by | urn:li:corpuser:__datahub_system |
| created_for |
All metadata is stored with this structure, the main information here is the urn, aspect and metadata fields. The way DataHub finds data is through the URN field, which functions as the resource locator, and all key information is found within the metadata field.
Elasticsearch, on the other hand, is mainly responsible for improving metadata search. Elasticsearch allows the data to be indexed in such a way that the search for the data and the auto-completion when using the web frontend is much more efficient.
Conclusion
DataHub offers a complete and flexible solution for data governance. Its focus on community and integrations makes it a solid choice for those looking for flexibility and scalability in data management.
If you found this article interesting, we encourage you to visit the Data Engineering category to see similar posts to this one and to share it on social networks. See you soon!
