
When developing code, it is not only important to consider its functionality, but also its readability. This is especially important in working environments where a team of people are working on the same code. Readable code that is unified by common rules not only makes it easier to understand, but also ultimately increases the productivity of the whole team.
There are several tools designed to improve code quality. These include formatters such as Black and linters such as Ruff or Pylint, which focus on languages such as Python and others like it. However, SQLFluff is characterised by its exclusive focus on SQL, which makes it a particularly relevant tool for data engineers, given the fundamental role that this language plays in their day-to-day work.
What is SQLFluff?
SQLFluff is a linting and autoformatting tool designed specifically for SQL, which allows you to maintain consistent quality standards in SQL code, reducing errors and simplifying reviews.
This is a particularly interesting feature for all things Data related. This is because SQL is a language that is very relevant in this area, as it is used very frequently to perform queries on stored data. Furthermore, SQLFluff not only supports multiple SQL dialects, such as ANSI, T-SQL, PostgreSQL, BigQuery, among others, but also integrates with tools such as dbt to analyse and format dynamically generated models.
Installing SQLFluff
Having explained what SQLFluff is and what it is used for, the next step is to install it within the project we are working on. The easiest way to do this is to use pip or poetry, depending on how you manage your development environment. In my case, I usually use poetry, so I will explain it following that approach.
If you manage your dependencies with Poetry, you can add SQLFluff as a dependency to your project’s pyproject.toml file with the following command:
poetry add sqlfluffIn addition, if you are using DBT in your project, you will also need to install the DBT templater so that SQLFluff can correctly process macros and templates.
poetry add sqlfluff-templater-dbtOnce it is installed and running within your virtual environment, you can verify that it is correctly configured using the command:
sqlfluff --versionBasic SQLFluff configuration
After installing and verifying that we have it running in our virtual environment, the next step is to configure it to get the most out of it.
SQLFluff configuration is done through a .sqlfluff file, which has to be placed in the root of the project. This file defines the linting rules, the SQL dialect and other customisable options that we will see below.
First, it is important to define some general settings. For this, we will use YAML annotations that will allow us to specify certain key parameters such as the SQL dialect or the templater we want to use. In addition, in this file we will also define and customise specifics of how we want the linting to be performed through specific sections reserved for it, such as indentation or whether SQL keywords should be upper or lower case.
Creating the .sqlfluff file
With all this in mind, a .sqlfluff file with a basic configuration might look like this:
[sqlfluff]
dialect = postgres
templater = dbt
max_line_length = 120
processes = -1
[sqlfluff:templater:jinja]
# Path to the jinja templates
loader_search_path = include
ignore_template_errors = True
[sqlfluff:indentation]
# Allow implicit indents in code
allow_implicit_indents = True
tab_space_size = 4
indented_joins = True
template_blocks_indent = True
[sqlfluff:rules:aliasing.length]
# Sets a minimum length of 3 characters for table or column aliases
min_alias_length = 3
max_alias_length = 15
ignore_short_aliases = False
[sqlfluff:rules:capitalisation.keywords]
# SQL keywords must be capitalized
capitalisation_policy = upper
require_capitalisation = True
[sqlfluff:rules:capitalisation.identifiers]
# Identifiers must be lowercase.
extended_capitalisation_policy = lower
[sqlfluff:rules:capitalisation.functions]
# Function names must be capitalized.
extended_capitalisation_policy = upper
[sqlfluff:rules:capitalisation.literals]
# Text values must be lowercase.
capitalisation_policy = lower
[sqlfluff:rules:capitalisation.types]
# SQL data type names (STRING, INTEGER..) must be capitalized.
extended_capitalisation_policy = upper
[sqlfluff:rules:convention.not_equal]
# The inequality operator must be in C style (!= instead of <>)
preferred_not_equal_style = c_styleAs you may have noticed, there are a myriad of adjustments that can be made here. This gives SQLFluff incredible flexibility and precision, allowing you to have very fine-grained control over how all of your SQL code is written.
Once this part is set up, the next step is to test it on a specific file. To do this, just run the following command:
sqlfluff lint path/to/sql_fileAnd this will show you an output with all the settings that have to be made to meet the specifications you have set up earlier.
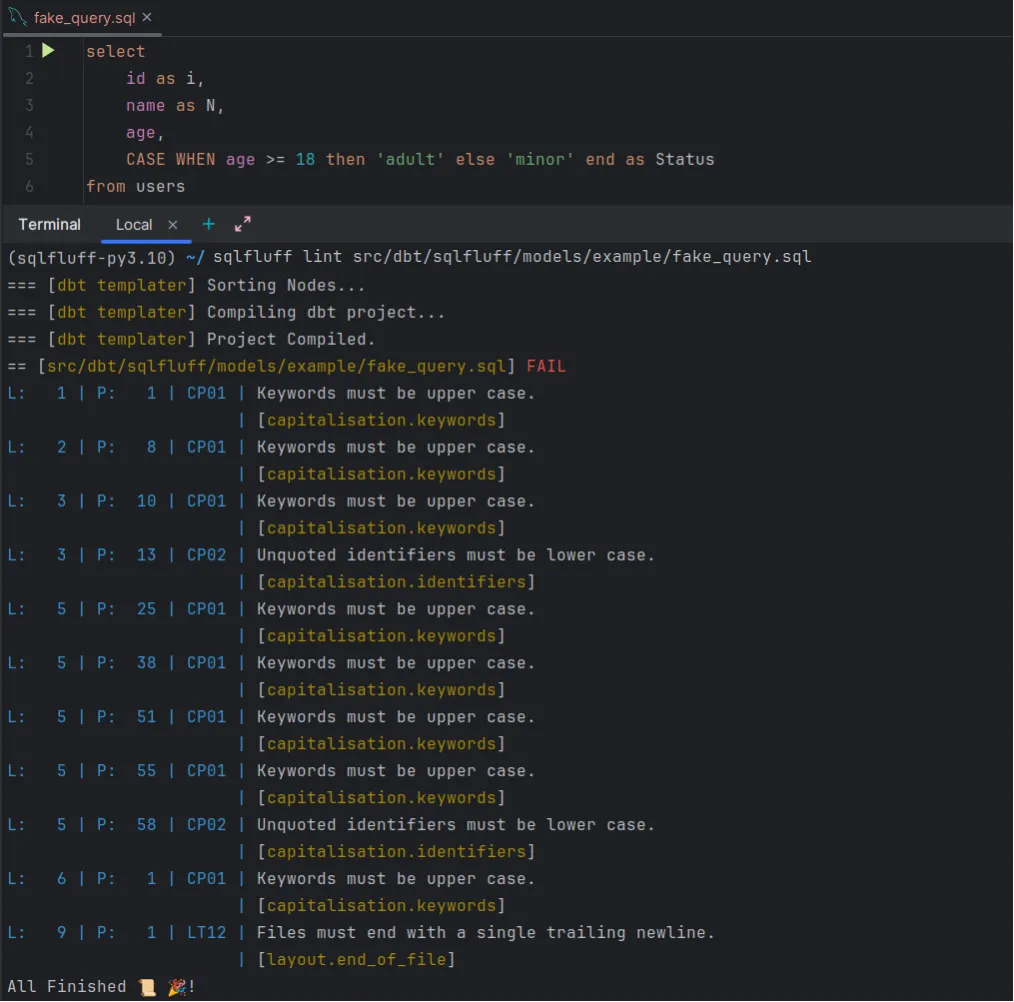
Linter vs Pre-commit in SQLFluff
One of the main features of SQLFluff is that it not only offers linter functionality when executed manually, but can also be integrated into pre-commit. This way, you can automate the validation of files that are staged before committing a commit.
Linter
As mentioned above, SQLFluff can be run directly from the terminal to check that the SQL code complies with the parameters set in your configuration file.
At this point, the main commands are as follows:
- lint: Parse SQL files and display errors in relation to the defined rules.
sqlfluff lint path/to/sql/files- fix: First run the linter and on the errors obtained, automatically apply the necessary corrections to adjust the file to the defined rules.
sqlfluff fix path/to/sql/files- render: This command is especially useful if you use jinja, as it allows you to see how SQL files will be rendered. It is beneficial when debugging generated code.
sqlfluff render path/to/sql/file.sql- parse: Finally, using this command, we can obtain a hierarchical representation of the SQL code, which will help us to see how it is structured.
sqlfluff parse path/to/sql/file.sqlAs you can see, the possibilities of this tool are enormous. Thanks to the commands explained above and others available in the tool (which can be accessed with sqlfluff -h), you can validate changes during development without having to integrate with external tools.
Pre-commit
On the other hand, SQLFluff has another functionality that allows it to be integrated into the pre-commit flow, running automatically on the files prepared for commit (in staging) and validating that they comply with the established rules before being committed to the repository.
To do this, the pre-commit-config.yml file has to be configured as follows:
- repo: https://github.com/sqlfluff/sqlfluff
rev: 3.2.5
hooks:
- id: sqlfluff-fix
args: ["--config", ".sqlfluff"]At this point, you have to specify whether you want only one linter to be made at the time of pre-committing, for which you would have to configure it with:
- id: sqlfluff-lintHowever, if you prefer it to apply the changes, you should leave it as indicated in the first example.
On the other hand, in the arguments section, it is also important to specify the configuration file to be executed. Although we will see it later, in complex projects you can have different configuration files adapted to different parts of the code.
SQLFluff integration with DBT
Let’s move on to another of SQLFluff’s strengths, which is that it can be integrated with projects that use DBT.
To do this, the first thing to do is to include the DBT templater in the .sqlfluff file in the following way:
[sqlfluff:templater:dbt]
# Path to the dbt project.
project_dir = ./src/dbt/sqlfluff
exclude_paths = target/In project_dir we will define the path to the DBT project and in exclude_paths we will specify the paths that we want to be excluded from the analysis.
Once this step is done, we only have to take into account the database we are using and install the necessary adapter to allow the connection to be made. In my case, dbt-postgres, since it is the database I am using.
poetry add dbt-postgresFinally, if we want to integrate it with pre-commit, we will have to add it to the pre-commit-config.yaml file as follows:
- repo: https://github.com/sqlfluff/sqlfluff
rev: 3.2.5
hooks:
- id: sqlfluff-fix
args: ["--config", ".sqlfluff"]
additional_dependencies: ["--sqlfluff-templater-dbt", "dbt-postgres"]Once these settings have been made, SQLFluff can be used in code processed by DBT.
Linting in DBT projects
When linting a DBT project, it is important to understand the main differences between DBT and jinja.
In DBT, before performing validation, a compilation of the project is carried out to check that the generated SQL is functional and correct. In this way, it also ensures that our code is valid within a DBT context. That is, if our DBT model has no style errors, but it has form errors, SQLFfluff will show an error in the compile.
On the other hand, if the DBT templater is not configured before launching the linter on a DBT project, it will only correct the style errors, formatting only the SQL code, but it will not take into account the logic or the DBT level context.
Specific exclusions with .sqlfluffignore
The .sqlfluffignore file is an essential tool for excluding specific files or directories from SQLFluff analysis. This is useful when you have temporary folders, automatically generated files or any content that does not need to be processed in your project.
Like the .sqlfluff configuration file, .sqlfluffignore should be placed in the root of the project and should have a structure similar to the following:
# Folders
src/logs/
src/tmp/
__pycache__/
node_modules/
# Files
*.log
*.bak
# Paths
src/test/ignore
# SQL Files
src/query/TEST1.sql
src/dbt/sqlfluff/models/example/fake_query_ignore.sqlAs can be seen, as in a .gitignore file, exclusions can be made at folder level, file types, paths or directly on specific files.
Finally, it is important to note that if the .sqlfluffignore file is located in the root of the project, SQLFluff will automatically detect it and exclude the defined elements, so no additional configuration is required.
Advanced use of SQLFluff
Multiple configurations
Finally, let’s talk about how to integrate different configurations for larger projects that integrate different tools. In my case, I am working with a project that integrates DBT and Airflow, where each tool requires a specific configuration.
On the one hand, DBT needs to include the management of variables, models and dependencies to be able to perform SQL compilation and validation. On the other hand, Airflow’s templates are based on jinja, which allows it to be run with a simpler configuration.
Likewise, and although in my case it is not necessary due to the current management of the project I am working on, independent styles can be specified for DTB and Airflow by simply configuring a specific configuration file for each tool.
Configuration files
First of all, as two configurations will be integrated, two .sqlfluff files will be created. Each of them will have the specific configuration adapted to the corresponding tool and both have to be located in the root of the project.
On the one hand, the one for DBT will be called dbt.sqlfluff and will have the configuration specified above with the DBT templater. On the other hand, the one for Airflow will be called airflow.sqlfluff and will contain the jinja templater.
Linter specifying the configuration
Once both configuration files have been generated, the next step is to be able to use them independently in the desired part of the code. To do this, when executing the command with the specific path to the file, the configuration flag has to be included as follows:
sqlfluff lint --config airflow.sqlfluff path/to/sql/fileThis will allow us to use one or another configuration depending on which part of the code we want to review.
Pre-commit with several configuration files
Finally, it will be necessary to configure pre-commit to use one configuration file or another depending on the tool or the part of the project to which it is being applied. This can be done by modifying the .pre-commit-config.yaml file as follows:
- repo: https://github.com/sqlfluff/sqlfluff
rev: 3.2.5
hooks:
- id: sqlfluff-fix
args: ["--config", "airflow.sqlfluff"]
exclude: "^src/dbt"
name: "sqlfluff_airflow"
- id: sqlfluff-fix
args: [ "--config", "dbt.sqlfluff" ]
additional_dependencies : ['sqlfluff-templater-dbt', 'dbt-postgres']
files: "^src/dbt"
name: "sqlfluff_dbt"As can be seen, two hooks have been configured. One of them has the Airflow configuration and, through the exclude, it is applied to the whole project except the specified path. The other one has the necessary configuration to execute DBT, associated to the DBT configuration file and it is applied only to the files that are inside the specified path.
Finally, in order to differentiate between the two processes, a name field has been added to allow a clearer visualisation of what is being executed.
With this configuration, when performing a commit, the pre-commit will be executed automatically, taking into account each part’s specific configuration.
Custom contexts in .sqlfluff for Jinja
When working with jinja it is very common to have dynamic variables that, if not handled properly, can generate errors in the SLQFluff linter. In order to avoid this, custom contexts can be configured within the .sqlfluff file to solve these cases.
In my specific case, in the Airflow project I use dynamic variables to specify the dataset to which the queries point. For this reason, if I don’t configure a specific context that recognises this casuistry, at the time of making the linter it will generate a failure in this point.
To test this configuration, I have generated the following test sql file:
CREATE OR REPLACE TABLE `{{ var.value.get('test') }}.example`
OPTIONS (description = "Example of a query with jinja") AS
SELECT
test.id,
test.name,
test.age,
age.date
FROM
`{{ var.value.get('test') }}.example_1` AS test
LEFT JOIN
`{{ var.value.get('test') }}.example_2` AS age
ON test.age = age.age_idAnd I have included the following in the airflow.sqlfluff file:
[sqlfluff:templater:jinja:context]
var = {"value": {"test": "example"}}In this case, the jinja context specified at the time of compilation will replace the variable ‘test’ by the parameter ‘example’, so when running the linter it will not show any error.
To check that this really happens, I run the render of that file and I get this result:
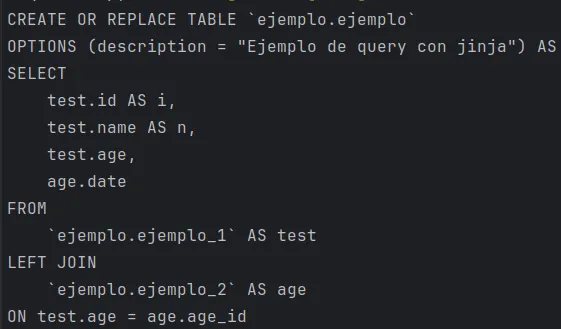
You can see that it has replaced the variable ‘test’ with ‘example’ and will therefore allow me to compile without errors.
Conclusion
As you have seen throughout this article, SQLFluff is an incredibly useful and versatile tool, especially for working environments where SQL is the preferred language.
Moreover, due to its easy installation, its simplicity of use and the wide configuration applicable, SQLFluff is the perfect linter to integrate in your projects.
If you found this article interesting, we encourage you to visit the Data Engineering category to see other posts similar to this one and to share it on networks. See you soon!
