
In a previous article of our blog we detailed what is RAG (Retrieval Augmented Generation) and how to take advantage of embedding models to extend the knowledge of an LLM with our own document base.
In this post, we will talk about the implementation of a RAG system in practice, as well as some extensions that can be made to provide systems based on large language models (LLMs) with tools and extensions.
LlamaIndex framework
A current project that implements RAG is LlamaIndex. It was originally conceived as a library to facilitate the implementation of RAG systems and their commissioning for applications.
LlamaIndex provides specific high and low level classes and methods for the many steps of a RAG application: ingesting document data in many different formats, interpreting the documents, splitting them into nodes, enriching them with metadata, embedding them in vectors and storing them in dedicated databases, building an index (the core class in the library that relates documents to their associated vectors) and querying the index, being able to establish which LLM (with external providers via API or local instances) to use at each step.
The high-level structure allows building simple demonstrations of RAG in very few lines of code, while the low-level structure allows fine-tuning the development for particular situations and makes it viable as a library for production applications.
Another project similar to LlamaIndex is LangChain. This library provides the necessary components to build RAG applications in a more accessible way, implementing at a high level many tools similar to LlamaIndex. However, LlamaIndex is more flexible by having lower-level methods, as well as a huge community involvement that results in numerous extensions to the library, such as for ingesting various document formats.
Minimal demo version
We can illustrate the minimal version of an augmented chatbot with documentation in just 5 lines of Python code, and it is the first tutorial offered in the LlamaIndex documentation. The following code block illustrates the high-level capabilities of this library. As a prerequisite, it is necessary to export the OpenAI key that gives access to the LLMs and embedding models required (although it is possible to configure it to use other models either locally or provided by third parties), in addition to creating the “data” folder with text files on which to run the RAG.
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)
chat_engine = index.as_chat_engine()
chat_engine.chat()Step by step, the above demo does the following:
- Reads and interprets all documents in the local “data” folder. It converts them into objects of the LlamaIndex class “Document”, giving them an ID and additional metadata.
- It creates an index, the central object of the library. In this step, the documents are sliced into nodes, and the embeddings or vectors corresponding to these nodes are calculated. This index stores in memory both the vectors and the reference to the original nodes and documents. The default embedding model used is text-embedding-ada-002, provided by OpenAI.
- A chatbot is initialized with ChatGPT 3.5 (the default model) whose capabilities are augmented with the RAG index created in the previous step.
This tiny demo illustrates very well some steps that would be necessary to design and implement in a production RAG application. On the one hand, we have the ingestion (step 1). That is, the loading and management of a document base with which we want to extend the LLM capabilities. In this case, we have the documents locally, working with low-level classes and methods, it is possible to program complex ingestion pipelines from different sources. It is also convenient to perform a preprocessing of these documents.
In a second step, the loading of the index can be customized in many aspects: which embedding model we want to use, what metadata we want to add to the vectors, where to save them. In this example they remain in RAM, in production it is necessary to store them in a dedicated database. It is also possible to build a workflow that loads a precomputed index and recalculates embeddings only for new documents or documents whose content has changed.
Finally, the use of the index is in this case the deployment of a chatbot, but it is possible to use a RAG system for very different purposes. Here we could tune the prompt that the LLM receives, turn it into an agent capable of executing functions, give it more than one index on which to RAG, etc.
The library offers many low-level tools that allow to implement each of these steps in a flexible way, adapting to very different use cases.
From natural language to SQL
An interesting variant of RAG also allows querying structured data from natural language. The basic idea is to provide an LLM with the schema of a relational database as a context, together with a question that can be answered by launching a query to that database.
A simple example would be, considering a database of purchases in an online store, to launch the following query:
User: What is the best-selling product in the year 2023 among 15-25 year olds?
A RAG system connected to a database (which we assume has tables to answer such a question) would process the question as follows, passing to an LLM the following enrichment with contextual information.
User: A query follows, and subsequently, a schema of a database. Your task is to write a syntactically correct SQL query that only involves tables and columns of the given schema and that allows to solve the question.
Question: what is the best-selling product in 2023 among 15-25 year olds?
Schema:
- table “historic_sales”: (timestamp, product_id, quantity, user_id)
- table “product_catalogue”: (id, product_name, description)
- table “users”: (id, full_name, age, email)
LLM:
SELECT product_catalogue.product_name FROM historic_sales
JOIN product_catalogue ON historic_sales.product_id = product_catalogue.id
JOIN users ON historic_sales.user_id = users.id
WHERE users.age BETWEEN 15 AND 25 AND EXTRACT(YEAR FROM historic_sales.timestamp) = 2023 GROUP BY product_id ORDER BY SUM(quantity)
LIMIT 1The system can be complemented with a component that is in charge of executing the database query, thus allowing the user’s query to be solved exactly. An advantage of this approach is that the data remains private to the LLM in case of requiring the use of an external API, only the database schema is sent to the LLM. A common extension of the above example is the provision to the LLM of the primary and secondary keys and, if allowed by the database, descriptions of the columns and what each of them represents, increasing the quality of the suggested SQL queries.
LlamaIndex has its own implementation of a RAG-SQL system through the NLSQLTableQueryEngine class. This class performs RAG in several steps: it fetches schematic information from the database, provides it to an LLM that builds the SQL query, executes it and uses the obtained information to give a final answer to the user.
The first RAG step on the database schemas is necessary to rescue only the schemas required for the construction of the SQL query. If all the schemas are used, this information could get out of the contextual window that accepts the LLM.
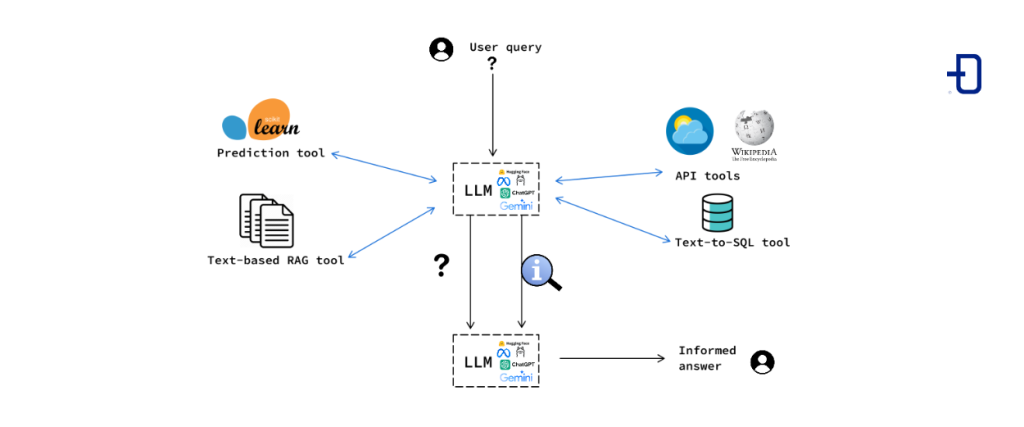
Agents
The above example highlights the usefulness of using LLMs or RAG systems as components of more complex information systems. In this sense, both LlamaIndex and Langchain allow the construction of “agents”. This concept was already developed by OpenAI by allowing in its API “function calling”: a query to a GPT model together with the structure of a function allows the model, given a question, to return what input the function would need in order to answer the question.
An agent, in this context, is composed of an LLM and a series of tools, which can be of a very diverse nature, accompanied by a description of their functionality. Examples of these tools are Python functions, external calls to APIs, RAG systems, SQL query synthesizers from natural language, prediction models, etc.
The central component of the agent is an LLM that, based on the user’s prompt (query), the conversation history and the set of tools accompanied by their corresponding descriptions, decides whether to execute one or more of these tools and with which call parameters. The result of these executions is provided, together with the original input, back to the LLM, which synthesizes the result of the process into a message back to the user.
Conclusion
RAG techniques effectively allow to have simultaneously the power of language models and an internal knowledge base without the need for costly retraining. As use cases we can identify support for software development from documentation (LlamaIndex has a RAG system to browse and consult its library documentation), complement for user assistance, enrichment of chatbots, management of work and ticket systems, etc.
Deploying a RAG application requires preliminary work to explore and structure the data, and the nature of the data dictates what indexing and enrichment strategies the vector database requires. These techniques are not a universal solution to all types of problems but they are good complements to existing workflows.
If you found this article interesting, we encourage you to visit the Data Science category to see other posts similar to this one and to share it on social networks. See you soon!
