
We all know that Artificial Intelligence is advancing at a significant speed in recent years. One of the aspects that is currently gaining most visibility is the ability to generate images with the unique source of origin of a descriptive text.
Evolution in time
There are several projects working towards this end, but the first to surprise us with its results was DALL-E, based on GPT-3, which in January 2021 showed us how, with a few simple input texts, it generated images that were surprisingly faithful to the text.

A year later, DALL-E 2 appeared, with even more impressive results than its predecessor, more realistic images and four times the resolution.

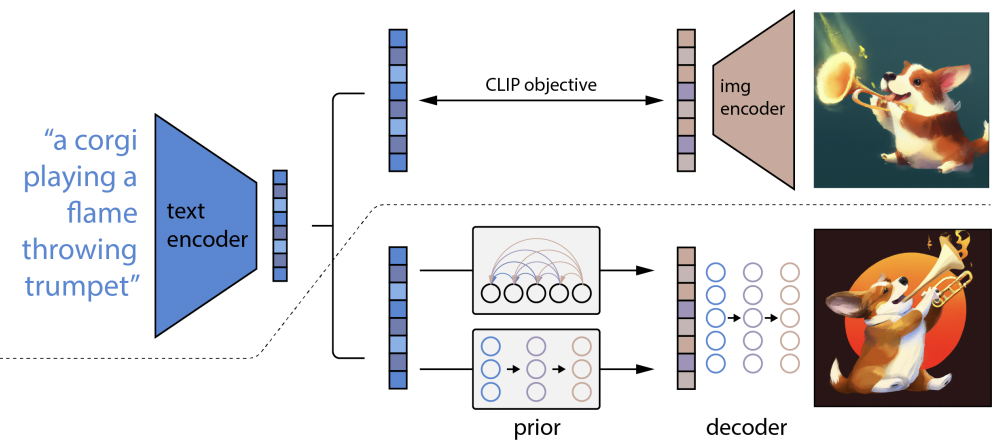
Artificial Intelligence models accessible to everyone
Although initially these great advances were only within the reach of large companies with significant resources on these systems, over time, different communities of experts in these areas have worked together to publish different projects under free software licenses, which allow us to test and have these advances directly at home.
So we have projects such as Diffusers, or Stable Diffusion among others, which we can configure and set up on our computers in a few minutes to create images with these techniques at home.
In this way, by configuring a local environment with the relevant libraries and a few lines of code, we can start to carry out the first tests as we wish.
High resolution images with Latent Diffusion Models (LDM)
For example, if we want to use a system based on LDM (Latent Diffusion Models), with a few minutes of work we have our environment configured and ready to create content.
from diffusers import DiffusionPipeline
model_id = "CompVis/ldm-text2im-large-256"
ldm = DiffusionPipeline.from_pretrained(model_id)
prompt = "a cat programming on a laptop"
images = ldm([prompt])["sample"]
for idx, image in enumerate(images):
image.save(f"img-output-{idx}.png")
Although it is a low resolution image, we have obtained a unique image, generated from that interpreted text.
This does not mean that we have a model that has copied and pasted bits and pieces of a cat and a laptop into our image. What we have is a system that has inferred in the training process what a cat should look like, what a laptop should look like, and generated a new image by trying to put the cat into the action it was asked to do.
Stable Diffusion Models: More accurate images than with LDM
If we use the same input text but use a more advanced model such as Stable Diffusion, we get an image with higher resolution, more accurate in some respects and just as unique and original.

In this simple way, we can propose images with the only limitation of our imagination and the way we can represent our idea in a text.
For example, what would a fighter plane designed by Leonardo Da Vinci look like?
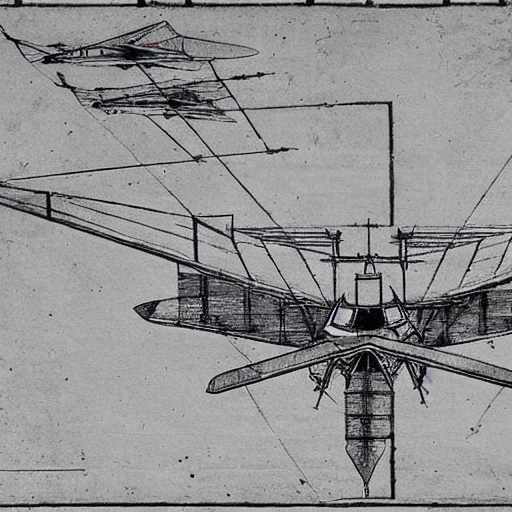
The image generated shows a preliminary sketch of what could be an aircraft, apparently in profile and from the front, with sketches that could represent the author’s measurements when drawing it to scale.
Recreating artworks with Artificial Intelligence
So, is it possible for an artificial intelligence to be creative? Let’s put it to the test.
Surely we all have in mind what Vincent van Gogh’s famous painting “The Starry Night” looks like.

We are going to do the following exercise: we are going to ask for the representation of different well-known works of art but interpreted by other well-known artists in order to see, for example, how artists such as Leonardo Da Vinci, Pablo Picasso or Salvador Dalí would have interpreted the work.
In the following table we will see the representation by a model based on LDM, with a lower resolution.



Although when we see the images we are able to identify which work it is, each of them has a different style, colors and strokes, as the model has tried to be faithful to the work of each of the authors in order to represent the painting.
If we repeat the same exercise but with a Stable Diffusion model:



Here we can see a more defined line, partly thanks to the better resolution of this model, but evidently due to the greater volume of training data and an important evolution over the first one.
In any case, the new works are genuine representations created from the “knowledge” of the work to be imitated and the techniques of the authors to be represented.
But lets take the difficulty level up a notch. Now we are going to recreate “The Last Supper”, comparing also how each model performs for it.
LDM:



Stable Diffusion Model:



In this case, the representation of the work is surprisingly detailed and we can clearly appreciate the “styles” that the artificial intelligence has interpreted to obtain each of the results.
If we are looking for something even more complicated to interpret, we can ask for the representation of “The Sistine Chapel” by different authors (in this case, an image of the chapel through the eyes of each author).
LDM:




Stable Diffusion:

Pablo Picasso



At this point I thought I had to look for a good challenge, a work with a lot of detail, full of objects, people, shadows and nuances, so I asked him for a representation of “The Maids of Honour” by different authors.
Stable Diffusion:




The results are fascinating and, considering that each of these images has been created only from a simple text (and the training of a model with a large volume of information, obviously), it must be recognized that the images obtained give rise to a whole debate.
Conclusion
So, we consider as art any product or activity that is carried out with the aim of obtaining something aesthetic, that transmits concepts, ideas or emotions. When art is generated by a human, it is clear, it is art. But do we consider a work generated by an artificial intelligence to be art?
Actually, the process it has followed is very similar. It has learned to interpret information, contextualize it and express it in a new and unique way, which is what a human would do in its learning process.
Therefore, we find ourselves with new tools that bring new scenarios, new professions, new challenges to the table. Perhaps it will become a new art to create the right inputs to obtain works that will have an impact on humanity in the not too distant future?
In any case, what is clear is that thanks to the great advances in artificial intelligence, both for text comprehension and for the creation of graphic arts, we have tools at our fingertips that open up new possibilities for the creation of projects of great value. Projects that we will see coming to light in the next few years, marking a before and after in these fields.
If you found this article interesting, we encourage you to visit the Algorithms category of our blog to see posts similar to this one and to share it with all your contacts. Don’t forget to mention us to let us know your opinion @Damavisstudio. See you soon!
