
Apache Spark Streaming is a widely used technology for real-time data processing. In Theoretical Introduction to Spark Streaming, we learned about the key concepts and how this Apache ecosystem solution works. We also looked at some practical examples with Apache Spark Structured Streaming that helped us implement our first data processing pipeline.
This time, we will analyze how Python and PySpark work with streaming applications. We will review the main differences between the two APIs from a real-time perspective. We will look at examples and explain the code so that we can all understand and perform our tests with a language such as Python, which is booming and is used by most of the data engineering community.
How does Spark Streaming work?
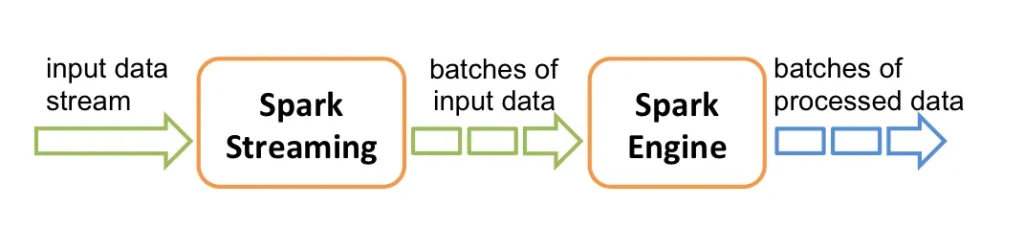
Before we begin, I would like to clarify that when we think of streams or real time, we imagine a queue that processes items one by one. To supplement the information already analyzed in other posts, Spark Streaming receives real-time input from data streams and divides the data into batches. These batches are processed by the Spark Engine to generate a stream of batches with the logic already applied.
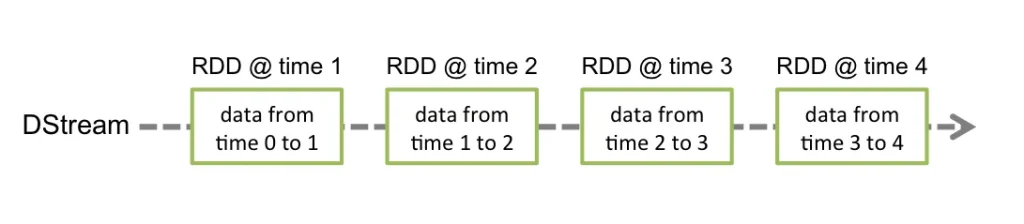
Spark Streaming is based on an abstraction called a discretized stream (DStream). A DStream represents a continuous stream of data, which is actually a continuous series of RDDs. Each RDD contains data corresponding to a specific time interval, from one moment to another.
From StreamContext to StructuredStream
This, of course, is the classic way Spark works with streams. In fact, it continues to do so, albeit at a lower level. Since version 3.4, the use of StreamContext (a system for direct use of DStreams) has been deprecated, giving way to StructuredStream.
Next, we will analyze how Spark Streaming is used in PySpark.
Example with StreamingContext
First, we will start with an example of reading a CSV file in PySpark streaming.
from pyspark import SparkContext
from pyspark.streaming import StreamingContext, DStream
sc = SparkContext("local[*]", "EjemploStreamContext")
ssc = StreamingContext(sc, 1)
input:DStream[str] = ssc.socketTextStream("localhost", 9999
def transform_text(text):
return text.upper()
transformed_lines = input.map(transform_text)
transformed_lines.pprint()
ssc.start()
ssc.awaitTermination()In this case, we are opening a connection to a port on localhost. The application will listen to that port and display everything sent to it on the screen, but in uppercase.
To test the application, we must open a socket connection to that port:
nc -lk 9999Everything we write after that command will be reflected in our application.
In this example, we see that input is a DStream[str]. This gives us a series of methods that StructuredStream does not provide. Some of the most famous ones would be map, flatMap, and reduceByKey. All of them disappear when using StructuredStream.
Spark Streaming with Pandas
from pathlib import Path
from pyspark.sql import SparkSession, DataFrame
from pyspark.sql.functions import avg, count
from pyspark.sql.types import StructType, IntegerType, StringType
abs = Path(__file__).resolve()
cities_path = abs.parent.parent / 'var' / 'cities'
spark = SparkSession.builder.appName("EjemploPandas").getOrCreate()
cities_schema = StructType() \
.add("LatD", IntegerType()) \
.add("LatM", IntegerType()) \
.add("LatS", IntegerType()) \
.add("NS", StringType()) \
.add("LonD", IntegerType()) \
.add("LonM", IntegerType()) \
.add("LonS", IntegerType()) \
.add("EW", StringType()) \
.add("City", StringType()) \
.add("State", StringType())
df:DataFrame = spark.readStream.option("sep", ",").option("header", "true").schema(cities_schema).csv(
str(cities_path))
def filter_func(iterator):
for pdf in iterator:
yield pdf[pdf.State == 'GA']
filtered_df = df.mapInPandas(filter_func,df.schema,barrier=True)
result = filtered_df.groupBy("State").agg(avg("LatD").alias("latm_avg"), avg("LatM").alias("latm_avg"),
avg("LatS").alias("lats_avg"), count("State").alias("count"))
query = result.writeStream.outputMode("complete").format("console").start(truncate=False
query.awaitTermination()This time, we load a CSV file with a specific structure and apply filtering and aggregation.
The most interesting thing is that we start to see differences between the APIs. We can see that the filter_func function is highlighted in color, which is called using the mapInPandas method. This is a notable difference. Despite having some disadvantages compared to its older sibling, PySpark integrates with both Pandas and Arrow.
This feature can be useful, especially if we are in a context where there is functionality that comes implemented with Pandas integration and we can exploit this resource.
The same is true with Arrow; it is possible to use the mapInArrow function. This significantly reduces the overhead of serialization and deserialization between Spark and Pandas. The operation would be the same as mapInPandas, but using Arrow underneath.
Example with StructuredStream
This is probably the simplest example we can give. The complete code, including the csv read, can be downloaded from Damavis Git.
from pathlib import Path
from pyspark.sql import SparkSession
from pyspark.sql.functions import *
abs = Path(__file__).resolve()
reader_path = abs.parent.parent / 'var' / 'lorem'
spark = SparkSession.builder.appName("EjemploStructuredStream").getOrCreate()
df:DataFrame
= spark.readStream.format("text").load(str(reader_path))
word_counts = df \
.select(explode(split(df.value, " ")).alias("word")) \
.groupBy("word").count()
query = word_counts.writeStream \
.outputMode("complete") \
.format("console") \
.start()
query.awaitTermination()In this example, we are using the StructuredStream API. This API provides us with a DataFrame object, and here we can find another difference with Scala. When we delve deeper into the readStream method that works with the DataStreamReader object, we see that in Scala there are occasions when, instead of returning a DataFrame, it returns a Dataset. For example, in the case of the readStream.textFile method.
This feature is specific to the difference between languages, as Dataset is not included in PySpark. This is because Python is a dynamically typed language, and this implementation requires a static typing type, as it takes advantage of this typing to perform optimizations.
Conclusion
In conclusion, in this post we have learned how to use streams in PySpark. After some research, we have seen the main differences with respect to the Scala version. We have also seen practical examples that show the variations between the two APIs.
Although PySpark has certain limitations compared to Scala (such as not having Datasets), it compensates for this with the flexibility provided by the language. In addition to advantages such as integration with Pandas and Arrow, which make working with data easier and more efficient. Now it is up to you to choose which language you like best for your streaming applications.
And that’s all! If you found this article interesting, we encourage you to visit the Data Engineering category to see all related posts and to share it on networks. See you soon!
