
Kafka is one of the most popular technologies in the Apache stack, which we have already explored in our blog. If you are not yet familiar with it, we recommend reading Introduction to Apache Kafka to learn about its main components.
Kafka Architecture: From Zookeeper to KRaft
First, we will analyze how this technology has developed over time in relation to what we have discussed previously.
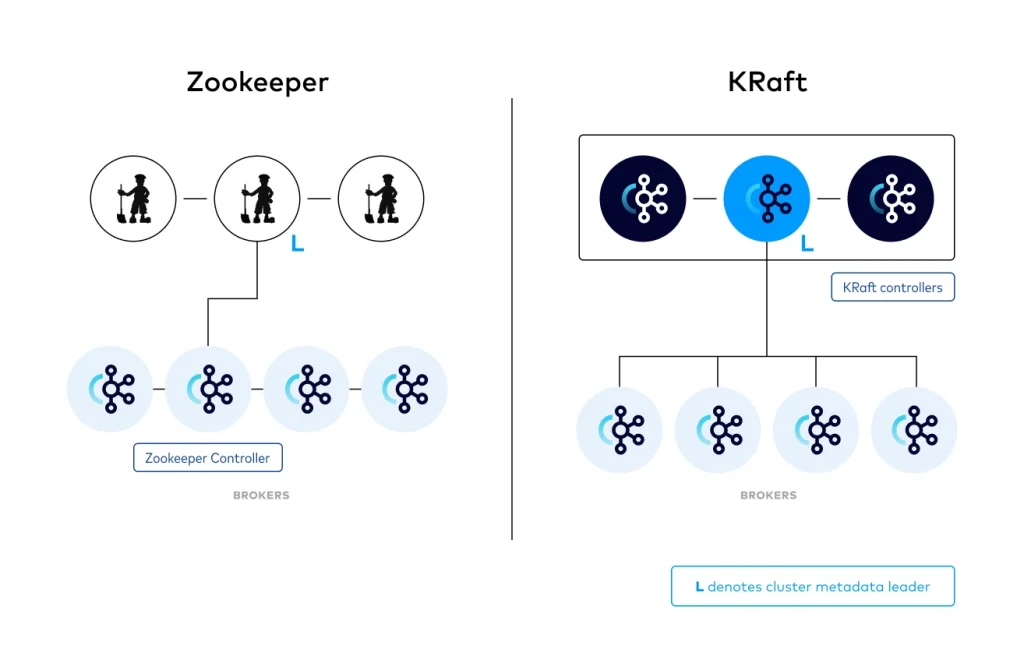
Kafka’s architecture has evolved and no longer depends on Zookeeper. Since version 3.3, a new consensus system called KRaft (Apache Kafka on Raft) has been introduced. For the time being, Zookeeper can still be used as a consensus mechanism. However, there are plans to eliminate this dependency in the future.
Remember that Zookeeper connected to the brokers. It has also been an essential component in Kafka for coordinating configuration, broker information, and cluster status.
How KRaft works in Kafka
With KRaft, Kafka uses its own consensus protocol (based on Raft) to manage the status of brokers and partitions internally. A set of brokers (Controllers) store and replicate this information, keeping it consistent without the need for an external system. When we talk about an external system, we mean that Zookeeper has its own identity. In addition, it is used in many other projects as a backend support for distributed systems.
KRaft manages everything internally with one or more Controllers. These Controllers are special brokers that use the Raft protocol to replicate the state and maintain consensus in the cluster. This unifies Kafka into a single system and facilitates management.
KRaft coordinates the assignment and status of partitions within the cluster, as well as the election of the leader for each partition. This leader selection process is crucial. The leader broker for each partition is the one that handles read and write operations. For its part, KRaft verifies that a leader is assigned efficiently and reliably.
KRaft ensures that the replicas of each partition are synchronized with the leader. Data replication between brokers is managed to ensure the durability and consistency of the information. This allows data to remain available even in the event of failure of one or more brokers.
Finally, it maintains and coordinates the states of consumer groups, including tracking the offsets that each consumer has processed. This ensures that consumers can continue from the last point read in the event of a disconnection or failure, without the need for additional coordination with Zookeeper.
Partitions in Apache Kafka
One of the main concepts we need to understand is how the partitioning system works within Kafka.
Each Kafka topic is divided into multiple partitions, allowing messages to be distributed among several brokers. This facilitates scalability and parallel processing. Within a partition, Kafka guarantees the order of messages. That is, events are kept in the same order in which they were sent and read. However, at the topic level, since each partition is independent, this same order is not guaranteed.
Replicas, leaders, and followers
Each partition has replicas to protect data durability and availability. Only one of these replicas acts as the “leader,” responsible for managing all read and write operations for the topic. The rest of the replicas function as “followers,” continuously synchronizing with the leader so they can take over its role in case of failure.
Kafka maintains a list of synchronized replicas or ISRs (In-Sync Replicas), which are up to date with the leader. This way, if the broker hosting the leader of a partition fails, Kafka automatically chooses a new leader replica from the ISR list. This prevents service interruption.
Sometimes, it may be useful to assign messages to partitions. That is, certain messages always fall into the same partition. If a message has a key, the partitioner calculates a hash of that key, which allows the message to be directed to a specific partition. This way, all messages with the same key will go to the same partition, respecting the relative order of messages of that type.
To better understand this, let’s explain it with an example. Imagine that we need to ensure the order of operations between accounts at a bank. We know that Kafka ensures the order of messages within the same partition. But if the messages were transactions and were assigned a partition randomly, it could lead to some kind of race condition. If we make the key (which decides where a message should go) the account number, we ensure that we will always read all transactions related to the same account in order.
Apache Kafka case studies
Let’s move on to the practical side. Below, we will look at the different cases we have presented and analyze how Kafka would behave. To do this, we will use this Kafka Visualization tool, which will allow us to observe the behavior of messages in different partitions.
Example 1: Producers and consumers in a topic with two partitions
Let’s start with the simplest example. In this case, we have a producer that sends messages to two brokers (those that appear with the shutdown button). The topic has two partitions, so each broker displays those two lines where the messages are inserted.
In a random partition assignment system, messages can fall into either partition 1 or 2, but the order within the partition is always respected. In other words, the latest messages will always be newer than the previous ones.
At the bottom, there is a consumer group called A. This consumer group only has one consumer, so it is responsible for reading both partitions to obtain all the messages.
*Note: In the image, you can clearly see how the dark-colored partitions are the leader partitions. You can also see how the producer sends data only to the leader partitions. As mentioned above, the other partitions will synchronize with the leader.
Case 2: Distribution of consumers in a consumer group
In this case, we have added one more consumer to consumer group A. We can see how each consumer distributes the messages from the topic and prepares to read each one from a different partition.
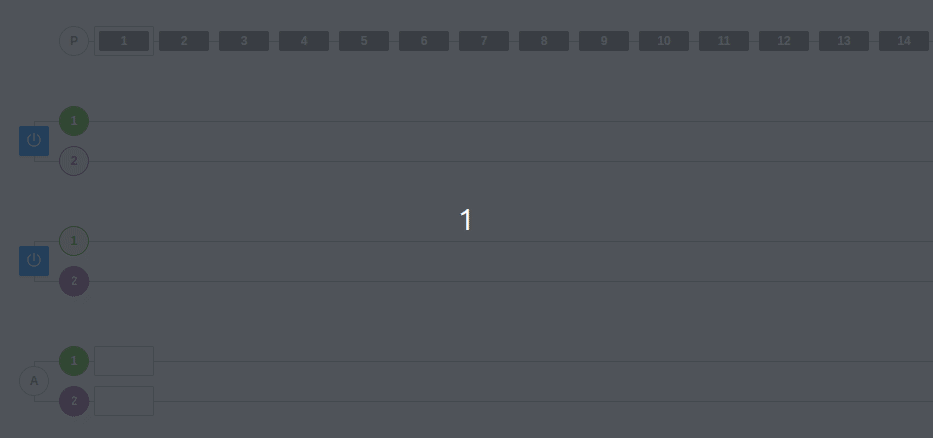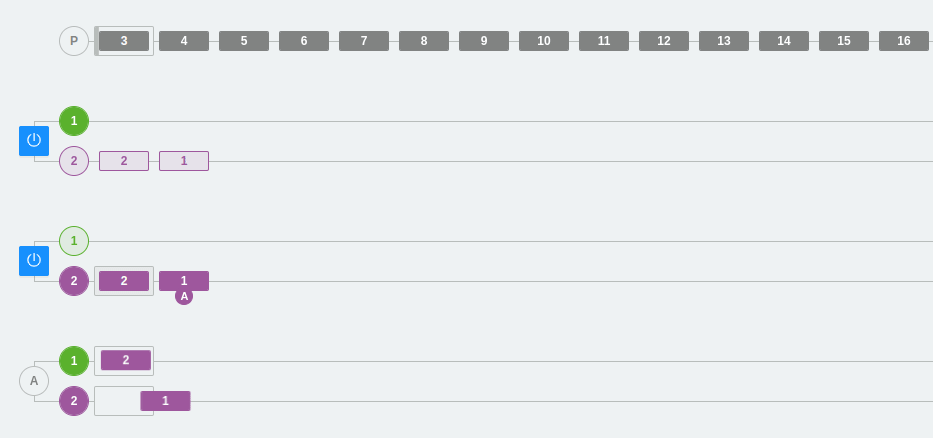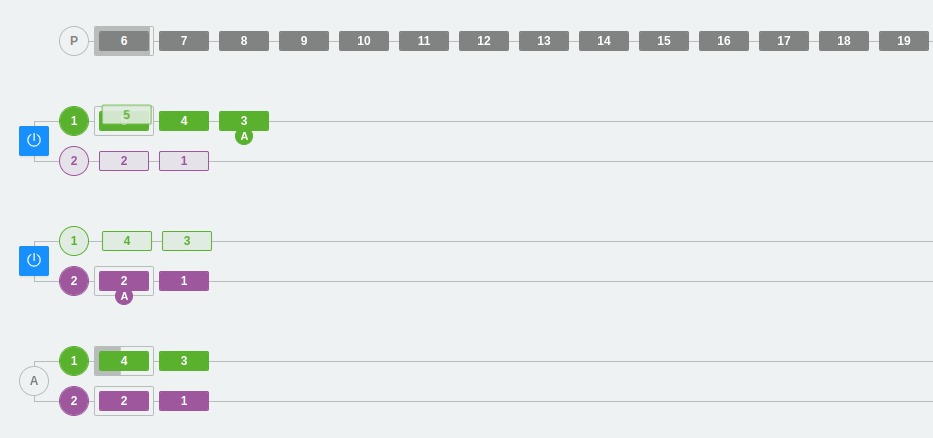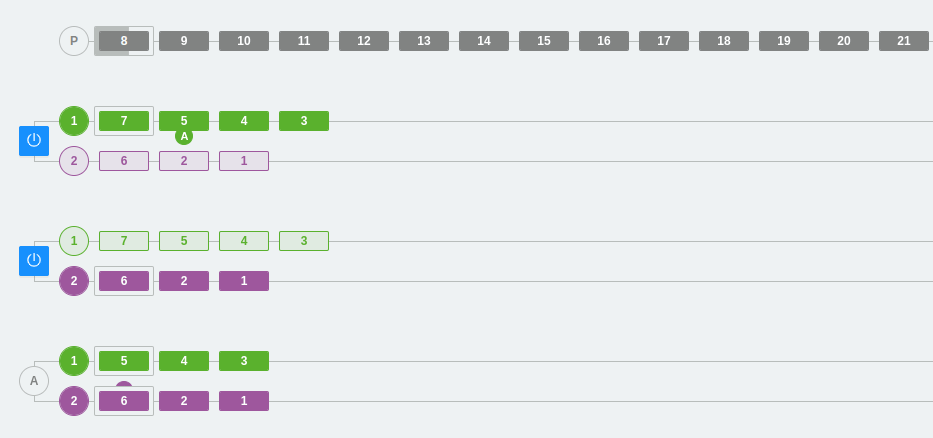
This example illustrates a limitation that we discussed earlier, but it is probably much clearer now. We cannot have more consumers in a consumer group than the number of partitions that the topic has.
What happens if we add a new partition in this same example?
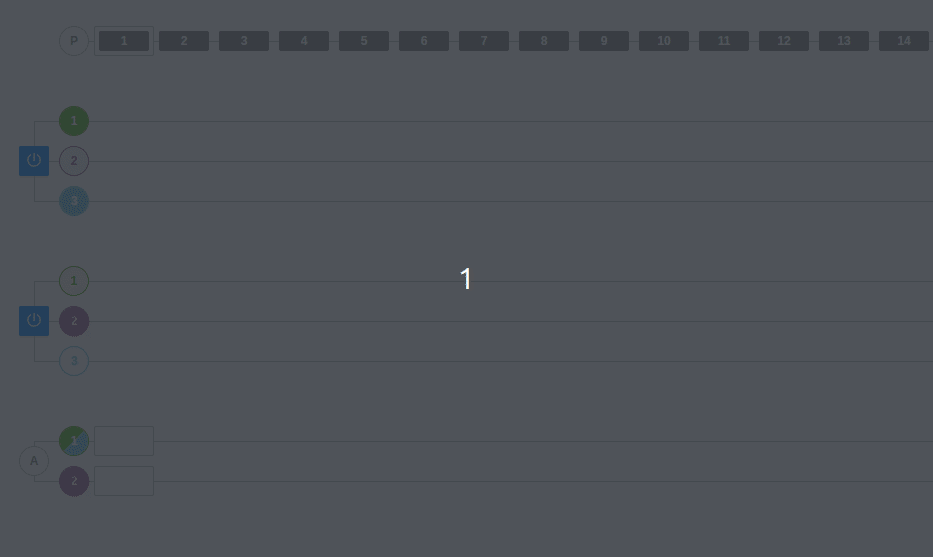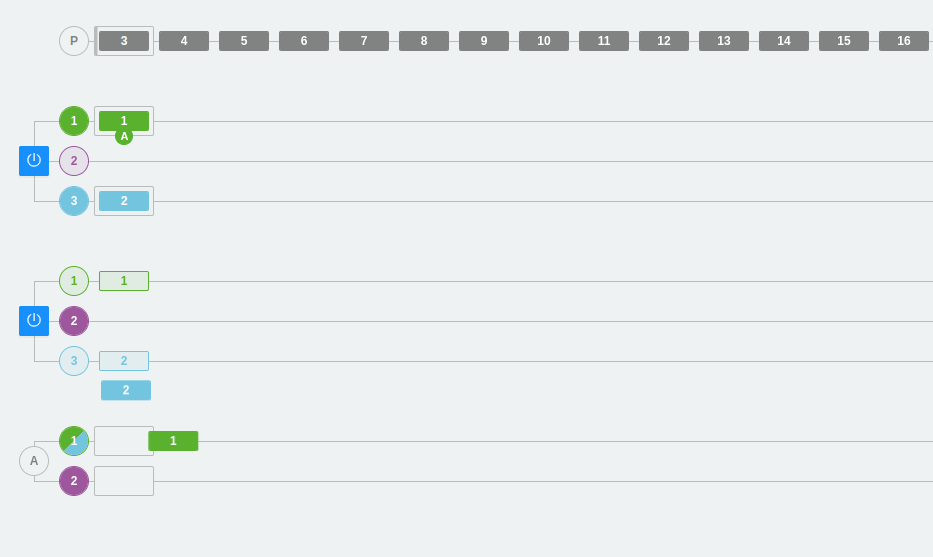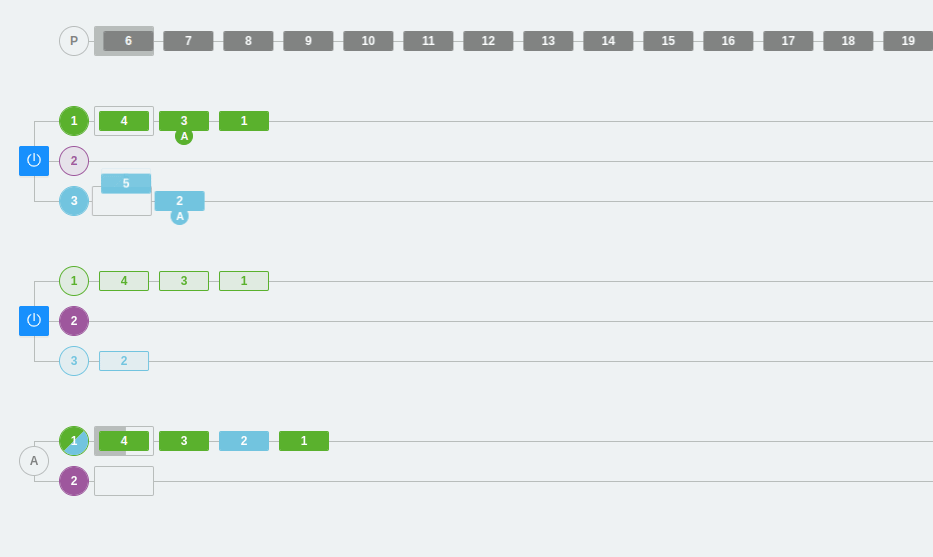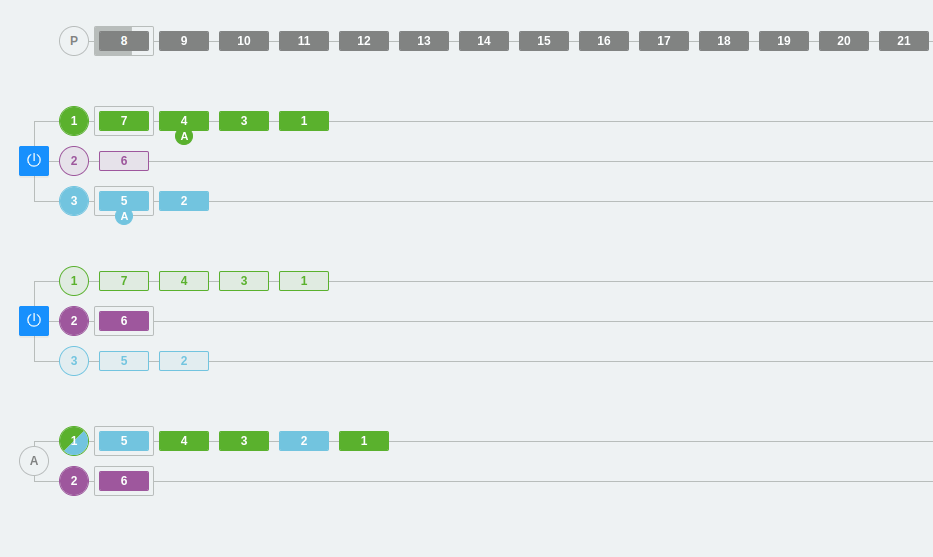
What happens is that one of the consumers will collect messages from two partitions and the other consumer will only collect messages from one partition.
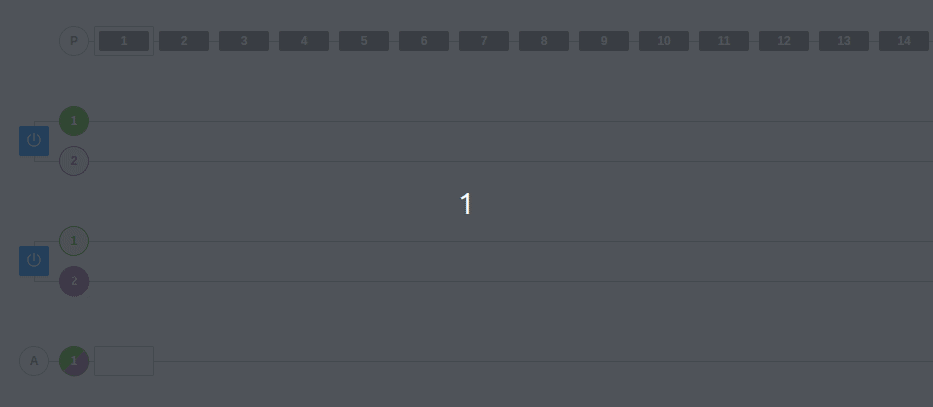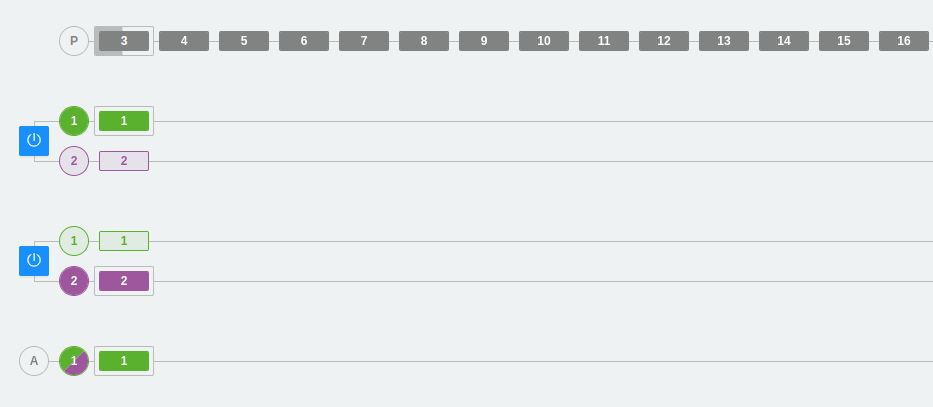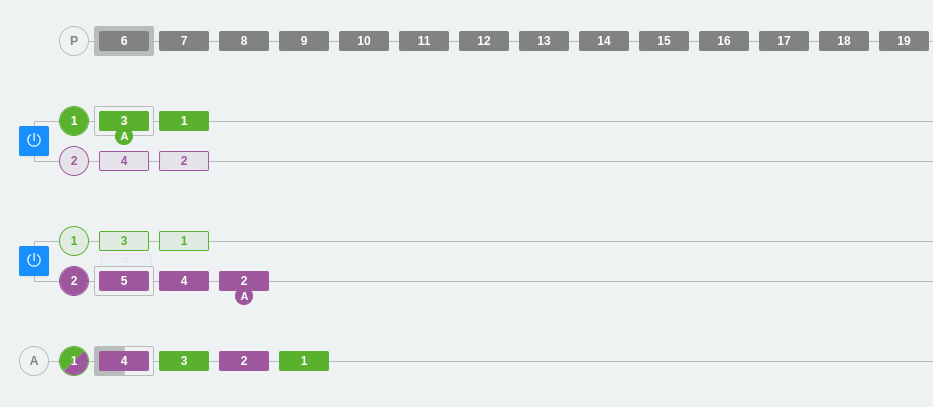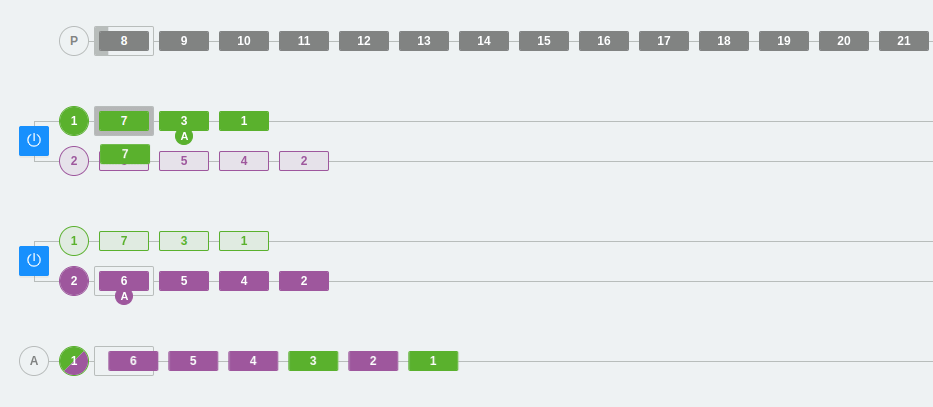
Example 3: Scaling partitions and consumers in Kafka
In the following example, we have three partitions in the two brokers and three consumers within the same consumer group A.
As we have already seen, a consumer from the group will be connected to each partition. Each partition has a number and a color that identifies it so that it is easier to follow the flow visually.
On the other hand, we can see that the colors are green, purple, and deep blue. At one point, the partitions are changed, one is removed, and the third partition disappears. The rest of the messages will be placed in the other partitions and consumer 3 will be deactivated (since it will not be able to listen directly on any partition). Remember that, in this case, consumers that cannot be assigned to a partition will remain inactive. This does not mean that they are useless, as they ensure high availability from the point of view of data consumption.
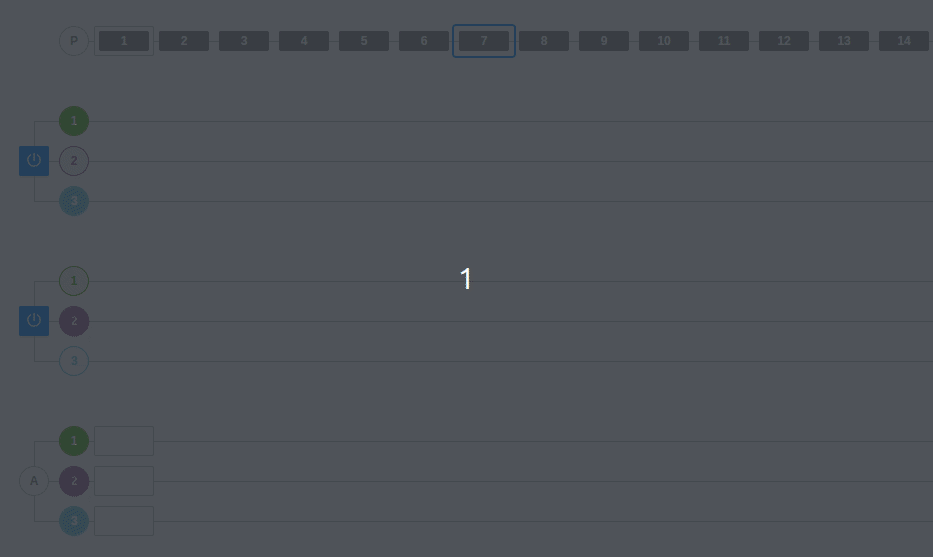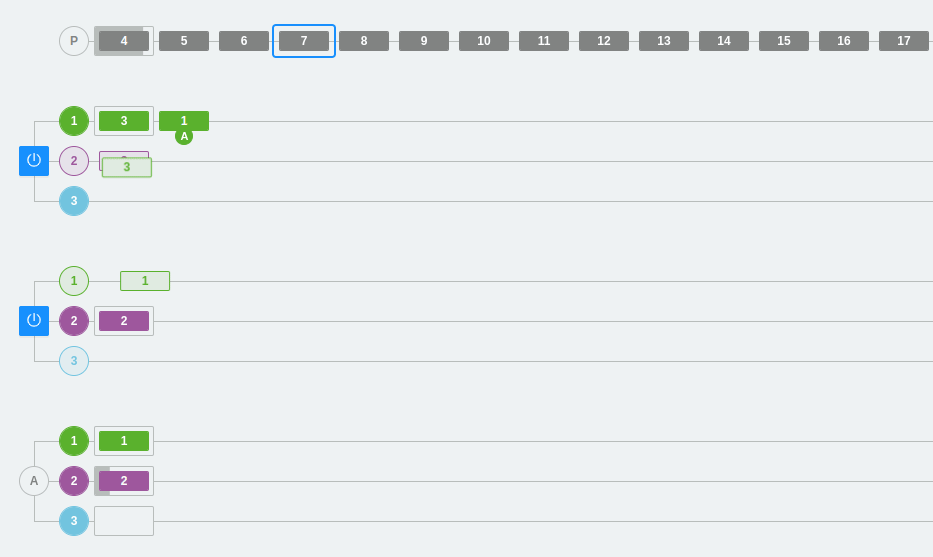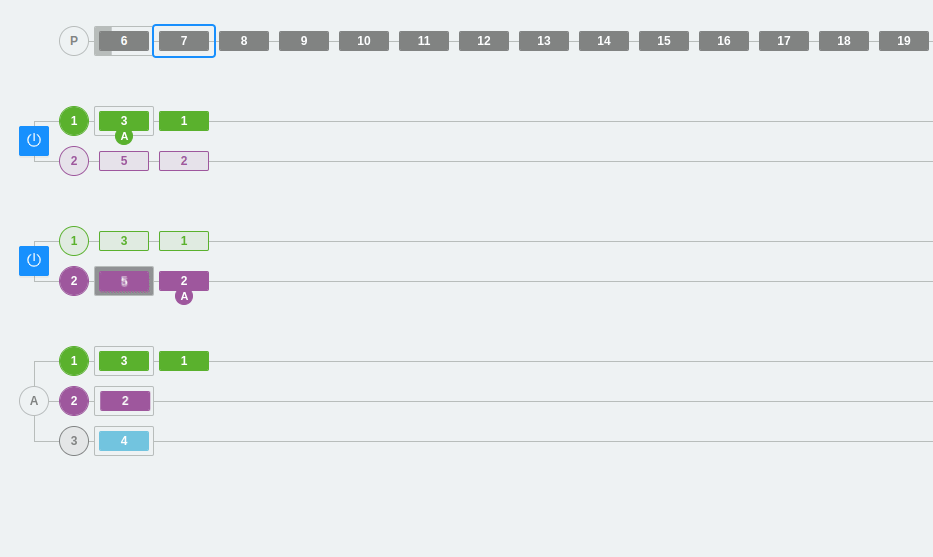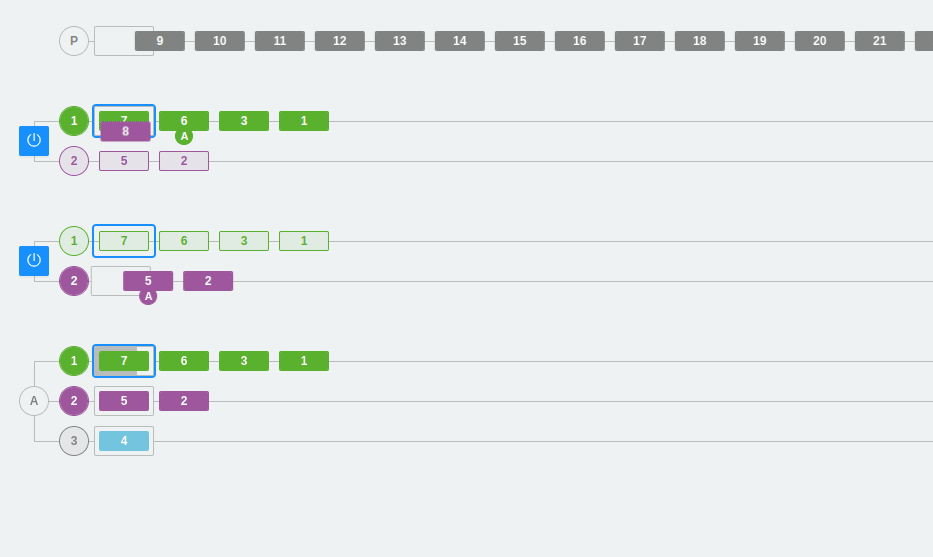
Case 4: Broker failure and cluster recovery
In this example, we will see what happens when we remove a broker that becomes inactive for any reason.

As can be seen, we have two brokers with two partitions each. At a given moment, the second broker is interrupted. The only available broker takes on the entire workload, with the secondary partition becoming the primary partition. Subsequently, the inactive broker is reactivated. Immediately, the cluster tends to synchronize the messages by moving all messages that were injected during the downtime to the second broker. Thus, we can see that the second broker has not recovered the primary partition in purple, as it has remained in the first broker until the status changes.
Conclusion
In this post, we have seen how the Apache Kafka architecture has evolved with the introduction of KRaft. This system has arrived with the aim of replacing Zookeeper in the internal management of the cluster. Now, Kafka is able to autonomously handle consensus and replication, simplifying its architecture and improving efficiency.
So much for today’s post. If you found it interesting, we encourage you to visit the Software category to see similar articles and to share it in networks with your contacts. See you soon!
